Deadlock Detection
If a system does not employ either a deadlock-prevention or a deadlock- avoidance algorithm, then a deadlock situationmay occur. In this environment, the system may provide:
• An algorithm that examines the state of the system to determine whether a deadlock has occurred
• An algorithm to recover from the deadlock
Next, we discuss these two requirements as they pertain to systems with only a single instance of each resource type, as well as to systems with sev- eral instances of each resource type. At this point, however, we note that a detection-and-recovery scheme requires overhead that includes not only the run-time costs of maintaining the necessary information and executing the detection algorithm but also the potential losses inherent in recovering from a deadlock.
Single Instance of Each Resource Type
If all resources have only a single instance, then we can define a deadlock- detection algorithm that uses a variant of the resource-allocation graph, called a wait-for graph. We obtain this graph from the resource-allocation graph by removing the resource nodes and collapsing the appropriate edges.
More precisely, an edge from Ti to Tj in a wait-for graph implies that thread Ti is waiting for thread Tj to release a resource that Ti needs. An edge Ti → Tj
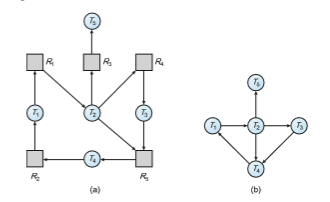
exists in a wait-for graph if and only if the corresponding resource-allocation graph contains two edges Ti → Rq and Rq → Tj for some resource Rq. In Figure 8.11, we present a resource-allocation graph and the corresponding wait-for graph.
As before, a deadlock exists in the system if and only if the wait-for graph contains a cycle. To detect deadlocks, the system needs to maintain the wait- for graph and periodically invoke an algorithm that searches for a cycle in the graph. An algorithm to detect a cycle in a graph requires O(n 2) operations, where n is the number of vertices in the graph.
The BCC toolkit described in Section 2.10.4 provides a tool that can detect potential deadlocks with Pthreads mutex locks in a user process running on a Linux system. The BCC tool deadlock detector operates by inserting probes which trace calls to the pthread mutex lock() and pthread mutex unlock() functions. When the specified process makes a call to either function, deadlock detector constructs a wait-for graph of mutex locks in that process, and reports the possibility of deadlock if it detects a cycle in the graph.
Several Instances of a Resource Type
The wait-for graph scheme is not applicable to a resource-allocation system with multiple instances of each resource type. We turn now to a deadlock- detection algorithm that is applicable to such a system. The algorithm employs several time-varying data structures that are similar to those used in the banker’s algorithm (Section 8.6.3):
• Available. Avector of length_m_ indicates the number of available resources of each type.
DEADLOCK DETECTION USING JAVATHREAD DUMPS
Although Java does not provide explicit support for deadlock detection, a thread dump can be used to analyze a running program to determine if there is a deadlock. A thread dump is a useful debugging tool that displays a snapshot of the states of all threads in a Java application. Java thread dumps also show locking information, including which locks a blocked thread is waiting to acquire. When a thread dump is generated, the JVM searches the wait-for graph to detect cycles, reporting anydeadlocks it detects. To generate a thread dump of a running application, from the command line enter:
Ctrl-L (UNIX, Linux, or macOS) Ctrl-Break (Windows)
In the source-code download for this text, we provide a Java example of the program shown in Figure 8.1 and describe how to generate a thread dump that reports the deadlocked Java threads.
• Allocation. An n × _m_matrix defines the number of resources of each type currently allocated to each thread.
• Request. An n × m matrix indicates the current request of each thread. If Request[i][j] equals k, then thread Ti is requesting k more instances of resource type Rj.
The ≤ relation between two vectors is defined as in Section 8.6.3. To sim- plify notation, we again treat the rows in the matrices Allocation and Request as vectors; we refer to them as Allocationi and Requesti**.** The detection algo- rithm described here simply investigates every possible allocation sequence for the threads that remain to be completed. Compare this algorithm with the banker’s algorithm of Section 8.6.3.
1. Let**Work** and Finish be vectors of length m and n, respectively. Initialize Work = Available. For i = 0, 1, …, n–1, if Allocationi ≠ 0, then Finish[i] = false. Otherwise, Finish[i] = true.
2. Find an index i such that both
a. Finish[i] == false
b. Requesti ≤**Work**
If no such i exists, go to step 4.
3. Work =Work + Allocationi Finish[i] = true Go to step 2.
4. If Finish[i] == false for some i, 0≤ i< n, then the system is in a deadlocked state. Moreover, if Finish[i] == false, then thread Ti is deadlocked.
This algorithm requires an order of m × _n_2 operations to detect whether the system is in a deadlocked state.
You may wonder why we reclaim the resources of thread Ti (in step 3) as soon as we determine that Requesti ≤ Work (in step 2b). We know that Ti is currently not involved in a deadlock (since Requesti ≤ Work). Thus, we take an optimistic attitude and assume that Ti will require no more resources to complete its task; it will thus soon return all currently allocated resources to the system. If our assumption is incorrect, a deadlock may occur later. That deadlock will be detected the next time the deadlock-detection algorithm is invoked.
To illustrate this algorithm, we consider a system with five threads T 0 through T 4 and three resource types A, B, and C. Resource type A has seven instances, resource type B has two instances, and resource type C has six instances. The following snapshot represents the current state of the system:
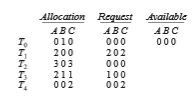
Suppose now that thread _T_2 makes one additional request for an instance of type C. The Request matrix is modified as follows:

Detection-Algorithm Usage
When should we invoke the detection algorithm? The answer depends on two factors:
1. How often is a deadlock likely to occur?
2. How many threads will be affected by deadlock when it happens?
MANAGING DEADLOCK IN DATABASES
Database systems provide a useful illustration of how both open-source and commercial software manage deadlock. Updates to a database may be performed as transactions, and to ensure data integrity, locks are typically used. A transaction may involve several locks, so it comes as no surprise that deadlocks are possible in a database with multiple concurrent transac- tions. To manage deadlock, most transactional database systems include a deadlock detection and recovery mechanism. The database server will peri- odically search for cycles in the wait-for graph to detect deadlock among a set of transactions. When deadlock is detected, a victim is selected and the transaction is aborted and rolled back, releasing the locks held by the victim transaction and freeing the remaining transactions from deadlock. Once the remaining transactions have resumed, the aborted transaction is reissued. Choice of a victim transaction depends on the database system; for instance, MySQL attempts to select transactions that minimize the number of rows being inserted, updated, or deleted.
If deadlocks occur frequently, then the detection algorithm should be invoked frequently. Resources allocated to deadlocked threads will be idle until the deadlock can be broken. In addition, the number of threads involved in the deadlock cycle may grow.
Deadlocks occur only when some thread makes a request that cannot be granted immediately. This request may be the final request that completes a chain of waiting threads. In the extreme, then, we can invoke the deadlock- detection algorithm every time a request for allocation cannot be granted immediately. In this case,we can identify not only the deadlocked set of threads but also the specific thread that “caused” the deadlock. (In reality, each of the deadlocked threads is a link in the cycle in the resource graph, so all of them, jointly, caused the deadlock.) If there are many different resource types, one request may create many cycles in the resource graph, each cycle completed by the most recent request and “caused” by the one identifiable thread.
Of course, invoking the deadlock-detection algorithm for every resource request will incur considerable overhead in computation time. A less expen- sive alternative is simply to invoke the algorithm at defined intervals—for example, once per hour or whenever CPU utilization drops below 40 percent. (Adeadlock eventually cripples system throughput and causes CPU utilization to drop.) If the detection algorithm is invoked at arbitrary points in time, the resource graph may contain many cycles. In this case, we generally cannot tell which of the many deadlocked threads “caused” the deadlock.