Advantages of Distributed Systems
A distributed system is a collection of loosely coupled nodes interconnected by a communication network. From the point of view of a specific node in a distributed system, the rest of the nodes and their respective resources are remote, whereas its own resources are local.
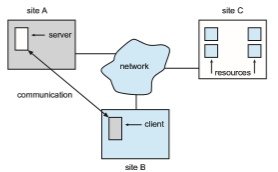
The nodes in a distributed system may vary in size and function. They may include small microprocessors, personal computers, and large general- purpose computer systems. These processors are referred to by a number of names, such as processors, sites, machines, and hosts, depending on the context in which they are mentioned. We mainly use site to indicate the location of a machine and node to refer to a specific system at a site. Nodes can exist in a client–server configuration, a peer-to-peer configuration, or a hybrid of these. In the common client-server configuration, one node at one site, the server, has a resource that another node, the client (or user), would like to use. A general structure of a client–server distributed system is shown in Figure 19.1. In a peer-to-peer configuration, there are no servers or clients. Instead, the nodes share equal responsibilities and can act as both clients and servers.
When several sites are connected to one another by a communication net- work, users at the various sites have the opportunity to exchange information. At a low level, messages are passed between systems, much as messages are passed between processes in the single-computer message system discussed in Section 3.4. Given message passing, all the higher-level functionality found in standalone systems can be expanded to encompass the distributed system. Such functions include file storage, execution of applications, and remote pro- cedure calls (RPCs).
There are three major reasons for building distributed systems: resource sharing, computational speedup, and reliability. In this section, we briefly discuss each of them.
Resource Sharing
If a number of different sites (with different capabilities) are connected to one another, then a user at one site may be able to use the resources available at another. For example, a user at site A may query a database located at site B. Meanwhile, a user at site B may access a file that resides at site A. In general, resource sharing in a distributed system provides mechanisms for sharing files at remote sites, processing information in a distributed database, printing files at remote sites, using remote specialized hardware devices such as a supercomputer or a graphics processing unit (GPU), and performing other operations.
Computation Speedup
If a particular computation can be partitioned into subcomputations that can run concurrently, then a distributed system allows us to distribute the sub- computations among the various sites. The subcomputations can be run con- currently and thus provide computation speedup. This is especially relevant when doing large-scale processing of big data sets (such as analyzing large amounts of customer data for trends). In addition, if a particular site is cur- rently overloaded with requests, some of them can be moved or rerouted to other, more lightly loaded sites. Thismovement of jobs is called load balancing and is common among distributed system nodes and other services provided on the Internet.
Reliability
If one site fails in a distributed system, the remaining sites can continue oper- ating, giving the system better reliability. If the system is composed of multi- ple large autonomous installations (that is, general-purpose computers), the failure of one of them should not affect the rest. If, however, the system is composed of diversified machines, each of which is responsible for some cru- cial system function (such as the web server or the file system), then a single failure may halt the operation of the whole system. In general, with enough redundancy (in both hardware and data), the system can continue operation even if some of its nodes have failed.
The failure of a node or site must be detected by the system, and appro- priate action may be needed to recover from the failure. The system must no longer use the services of that site. In addition, if the function of the failed site can be taken over by another site, the system must ensure that the transfer of function occurs correctly. Finally, when the failed site recovers or is repaired, mechanisms must be available to integrate it back into the system smoothly.