LOGICAL AGENTS
In which we design agents that can form representations of a complex world, use a process of inference to derive new representations about the world, and use these new representations to deduce what to do.
Humans, it seems, know things; and what they know helps them do things. These are not empty statements. They make strong claims about how the intelligence of humans is achieved—not by purely reflex mechanisms but by processes of reasoning that operate on internal representations of knowledge. In AI, this approach to intelligence is embodied inknowledge-based agents.
The problem-solving agents of Chapters 3 and 4 know things, but only in a very limited, inflexible sense. For example, the transition model for the 8-puzzle—knowledge of what the actions do—is hidden inside the domain-specific code of the RESULT function. It can be used to predict the outcome of actions but not to deduce that two tiles cannot occupy the same space or that states with odd parity cannot be reached from states with even parity. The atomic representations used by problem-solving agents are also very limiting. In a partially observable environment, an agent’s only choice for representing what it knows about the current state is to list all possible concrete states—a hopeless prospect in large environments.
Chapter 6 introduced the idea of representing states as assignments of values to variables; this is a step in the right direction, enabling some parts of the agent to work in a domain-independent way and allowing for more efficient algorithms. In this chapter and those that follow, we take this step to its logical conclusion, so to speak—we develop logic as a general class of representations to support knowledge-based agents. Such agents can combine and recombine information to suit myriad purposes. Often, this process can be quite far removed from the needs of the moment—as when a mathematician proves a theorem or an astronomer calculates the earth’s life expectancy. Knowledge-based agents can accept new tasks in the form of explicitly described goals; they can achieve competence quickly by being told or learning new knowledge about the environment; and they can adapt to changes in the environment by updating the relevant knowledge.
We begin in Section 7.1 with the overall agent design. Section 7.2 introduces a simple new environment, the wumpus world, and illustrates the operation of a knowledge-based agent without going into any technical detail. Then we explain the general principles of logic in Section 7.3 and the specifics of propositional logic in Section 7.4. While less expressive than first-order logic (Chapter 8), propositional logic illustrates all the basic concepts of logic; it also comes with well-developed inference technologies, which we describe in sections 7.5 and 7.6. Finally, Section 7.7 combines the concept of knowledge-based agents with the technology of propositional logic to build some simple agents for the wumpus world.
KNOWLEDGE-BASED AGENTS
The central component of a knowledge-based agent is its knowledge base, or KB. A knowledge base is a set of sentences. (Here “sentence” is used as a technical term. It is related but not identical to the sentences of English and other natural languages.) Each sentence is expressed in a language called a knowledge representation language and represents some assertion about the world. Sometimes we dignify a sentence with the name axiom, when the sentence is taken as given without being derived from other sentences.
There must be a way to add new sentences to the knowledge base and a way to query what is known. The standard names for these operations are TELL and ASK, respectively. Both operations may involve inference—that is, deriving new sentences from old. Inference must obey the requirement that when one ASKs a question of the knowledge base, the answer should follow from what has been told (or TELLed) to the knowledge base previously. Later in this chapter, we will be more precise about the crucial word “follow.” For now, take it to mean that the inference process should not make things up as it goes along.
Figure 7.1 shows the outline of a knowledge-based agent program. Like all our agents, it takes a percept as input and returns an action. The agent maintains a knowledge base, KB , which may initially contain some background knowledge.
Each time the agent program is called, it does three things. First, it TELLs the knowledge base what it perceives. Second, it ASKs the knowledge base what action it should perform. In the process of answering this query, extensive reasoning may be done about the current state of the world, about the outcomes of possible action sequences, and so on. Third, the agent program TELLs the knowledge base which action was chosen, and the agent executes the action.
The details of the representation language are hidden inside three functions that implement the interface between the sensors and actuators on one side and the core representation and reasoning system on the other. MAKE-PERCEPT-SENTENCE constructs a sentence asserting that the agent perceived the given percept at the given time. constructs a sentence that asks what action should be done at the current time. Finally, MAKE-ACTION-SENTENCE constructs a sentence asserting that the chosen action was executed. The details of the inference mechanisms are hidden inside TELL and ASK. Later sections will reveal these details.
The agent in Figure 7.1 appears quite similar to the agents with internal state described in Chapter 2. Because of the definitions of TELL and ASK, however, the knowledge-based agent is not an arbitrary program for calculating actions. It is amenable to a description at
function KB-AGENT(percept ) returns an action persistent: KB , a knowledge base t , a counter, initially 0, indicating time
TELL(KB , MAKE-PERCEPT-SENTENCE(percept , t )) action←ASK(KB , MAKE-ACTION-QUERY(t )) TELL(KB , MAKE-ACTION-SENTENCE(action , t )) t← t + 1 return action
Figure 7.1 A generic knowledge-based agent. Given a percept, the agent adds the percept to its knowledge base, asks the knowledge base for the best action, and tells the knowledge base that it has in fact taken that action. the knowledge level, where we need specify only what the agent knows and what its goals are, in order to fix its behavior. For example, an automated taxi might have the goal of taking a passenger from San Francisco to Marin County and might know that the Golden Gate Bridge is the only link between the two locations. Then we can expect it to cross the Golden Gate Bridge because it knows that that will achieve its goal. Notice that this analysis is independent of how the taxi works at the implementation level. It doesn’t matter whether its geographical knowledge is implemented as linked lists or pixel maps, or whether it reasons by manipulating strings of symbols stored in registers or by propagating noisy signals in a network of neurons.
A knowledge-based agent can be built simply by TELLing it what it needs to know. Starting with an empty knowledge base, the agent designer can TELL sentences one by one until the agent knows how to operate in its environment. This is called the declarative approach to system building. In contrast, the procedural approach encodes desired behaviors directly as program code. In the 1970s and 1980s, advocates of the two approaches engaged in heated debates. We now understand that a successful agent often combines both declarative and procedural elements in its design, and that declarative knowledge can often be compiled into more efficient procedural code.
We can also provide a knowledge-based agent with mechanisms that allow it to learn for itself. These mechanisms, which are discussed in Chapter 18, create general knowledge about the environment from a series of percepts. A learning agent can be fully autonomous.
THE WUMPUS WORLD
In this section we describe an environment in which knowledge-based agents can show their worth. The wumpus world is a cave consisting of rooms connected by passageways. Lurking somewhere in the cave is the terrible wumpus, a beast that eats anyone who enters its room. The wumpus can be shot by an agent, but the agent has only one arrow. Some rooms contain bottomless pits that will trap anyone who wanders into these rooms (except for the wumpus, which is too big to fall in). The only mitigating feature of this bleak environment is the possibility of finding a heap of gold. Although the wumpus world is rather tame by modern computer game standards, it illustrates some important points about intelligence.
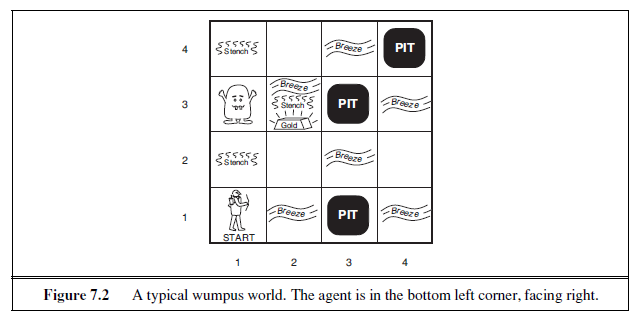
A sample wumpus world is shown in Figure 7.2. The precise definition of the task environment is given, as suggested in Section 2.3, by the PEAS description:
-
Performance measure: +1000 for climbing out of the cave with the gold, –1000 for falling into a pit or being eaten by the wumpus, –1 for each action taken and –10 for using up the arrow. The game ends either when the agent dies or when the agent climbs out of the cave.
-
Environment: A 4× 4 grid of rooms. The agent always starts in the square labeled [1,1], facing to the right. The locations of the gold and the wumpus are chosen randomly, with a uniform distribution, from the squares other than the start square. In addition, each square other than the start can be a pit, with probability 0.2.
-
Actuators: The agent can move Forward, TurnLeft by 90◦, or TurnRight by 90◦. The agent dies a miserable death if it enters a square containing a pit or a live wumpus. (It is safe, albeit smelly, to enter a square with a dead wumpus.) If an agent tries to move forward and bumps into a wall, then theagent does not move. The action Grab can be used to pick up the gold if it is in the same square as the agent. The action Shoot can be used to fire an arrow in a straight line in the direction the agent is facing. The arrow continues until it either hits (and hence kills) the wumpus or hits a wall. The agent has only one arrow, so only the first Shoot action has any effect. Finally, the action Climb can be used to climb out of the cave, but only from square [1,1].
-
Sensors: The agent has five sensors, each of which gives a single bit of information:
– In the square containing the wumpus and in the directly (not diagonally) adjacent squares, the agent will perceive a Stench.
– In the squares directly adjacent to a pit, the agent will perceive a Breeze. – In the square where the gold is, the agent will perceive a Glitter. – When an agent walks into a wall, it will perceive a Bump. – When the wumpus is killed, it emits a woeful Scream that can be perceived anywhere in the cave.
The percepts will be given to the agent program in the form of a list of five symbols; for example, if there is a stench and a breeze, but no glitter, bump, or scream, the agent program will get [Stench,Breeze ,None,None,None ].
We can characterize the wumpus environment along the various dimensions given in Chapter 2. Clearly, it is discrete, static, and single-agent. (The wumpus doesn’t move, fortunately.) It is sequential, because rewards may come only after many actions are taken. It is partially observable, because some aspects of the state are not directly perceivable: the agent’s location, the wumpus’s state of health, and the availability of an arrow. As for the locations of the pits and the wumpus: we could treat them as unobserved parts of the state that happen to be immutable—in which case, the transition model for the environment is completely
known; or we could say that the transition model itself is unknown because the agent doesn’t know which Forward actions are fatal—in which case, discovering the locations of pits and wumpus completes the agent’s knowledge of the transition model.
For an agent in the environment, the main challenge is its initial ignorance of the configuration of the environment; overcoming this ignorance seems to require logical reasoning. In most instances of the wumpus world, it is possible for the agent to retrieve the gold safely. Occasionally, the agent must choose between going home empty-handed and risking death to find the gold. About 21% of the environments are utterly unfair, because the gold is in a pit or surrounded by pits.
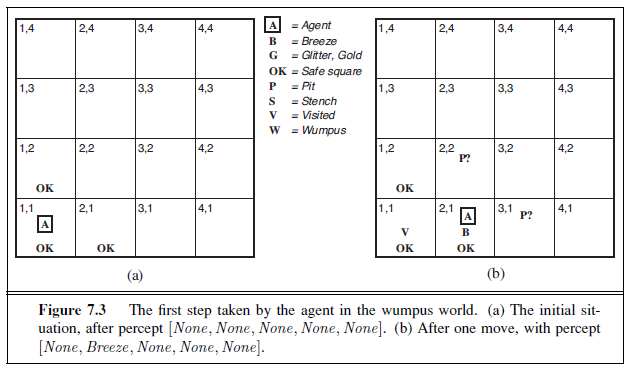
Let us watch a knowledge-based wumpus agent exploring the environment shown in Figure 7.2. We use an informal knowledge representation language consisting of writing down symbols in a grid (as in Figures 7.3 and 7.4).
The agent’s initial knowledge base contains the rules of the environment, as described previously; in particular, it knows that it is in [1,1] and that [1,1] is a safe square; we denote that with an “A” and “OK,” respectively, in square [1,1].
The first percept is [None,None,None,None ,None], from which the agent can conclude that its neighboring squares, [1,2] and [2,1], are free of dangers—they are OK. Figure 7.3(a) shows the agent’s state of knowledge at this point.
A cautious agent will move only into a square that it knows to be OK. Let us suppose the agent decides to move forward to [2,1]. The agent perceives a breeze (denoted by “B”) in [2,1], so there must be a pit in a neighboring square. The pit cannot be in [1,1], by the rules of the game, so there must be a pit in [2,2] or [3,1] or both. The notation “P?” in Figure 7.3(b) indicates a possible pit in those squares. At this point, there is only one known square that is OK and that has not yet been visited. So the prudent agent will turn around, go back to [1,1], and then proceed to [1,2].
The agent perceives a stench in [1,2], resulting in the state of knowledge shown in Figure 7.4(a). The stench in [1,2] means that there must be a wumpus nearby. But the
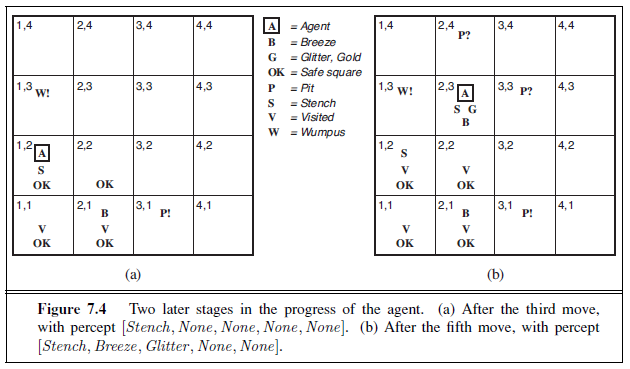
wumpus cannot be in [1,1], by the rules of the game, and it cannot be in [2,2] (or the agent would have detected a stench when it was in [2,1]). Therefore, the agent can infer that the wumpus is in [1,3]. The notation W! indicates this inference. Moreover, the lack of a breeze in [1,2] implies that there is no pit in [2,2]. Yet the agent has already inferred that there must be a pit in either [2,2] or [3,1], so this means it must be in [3,1]. This is a fairly difficult inference, because it combines knowledge gained at different times in different places and relies on the lack of a percept to make one crucial step.
The agent has now proved to itself that there is neither a pit nor a wumpus in [2,2], so it is OK to move there. We do not show the agent’s state of knowledge at [2,2]; we just assume that the agent turns and moves to [2,3], giving us Figure 7.4(b). In [2,3], the agent detects a glitter, so it should grab the gold and then return home.
Note that in each case for which the agent draws a conclusion from the available information, that conclusion is guaranteed to be correct if the available information is correct. This is a fundamental property of logical reasoning. In the rest of this chapter, we describe how to build logical agents that can represent information and draw conclusions such as those described in the preceding paragraphs.
LOGIC
This section summarizes the fundamental concepts of logical representation and reasoning. These beautiful ideas are independent of any of logic’s particular forms. We therefore postpone the technical details of those forms until the next section, using instead the familiar example of ordinary arithmetic.
In Section 7.1, we said that knowledge bases consist of sentences. These sentences are expressed according to the syntax of the representation language, which specifies all the sentences that are well formed. The notion of syntax is clear enough in ordinary arithmetic: “x + y = 4” is a well-formed sentence, whereas “x4y+ =” is not.
A logic must also define the semantics or meaning of sentences. The semantics definesSEMANTICS
the truth of each sentence with respect to each possible world. For example, the semanticsTRUTH
POSSIBLE WORLD for arithmetic specifies that the sentence “x + y = 4” is true in a world where x is 2 and y
is 2, but false in a world where x is 1 and y is 1. In standard logics, every sentence must be either true or false in each possible world—there is no “in between.”1
When we need to be precise, we use the term model in place of “possible world.”Where as possible worlds might be thought of as (potentially) real environments that the agent might or might not be in, models are mathematical abstractions, each of which simply fixes the truth or falsehood of every relevant sentence. Informally, we may think of a possible world as, for example, having x men and y women sitting at a table playing bridge, and the sentence x + y = 4 is true when there are four people in total. Formally, the possible models are just all possible assignments of real numbers to the variables x and y. Each such assignment fixes the truth of any sentence of arithmetic whose variables are x and y. If a sentence α is true in model m, we say that m satisfies α or sometimes m is a model of α. We use the notation M(α) to mean the set of all models of α.
Now that we have a notion of truth, we are ready to talk about logical reasoning. This involves the relation of logical entailment between sentences—the idea that a sentence follows logically from another sentence. In mathematical notation, we write
α |= β
1 Fuzzy logic, discussed in Chapter 14, allows for degrees of truth.
to mean that the sentence α entails the sentence β. The formal definition of entailment is this: α |= β if and only if, in every model in which α is true, β is also true. Using the notation just introduced, we can write
α |= β if and only if M(α) ⊆ M(β) .
(Note the direction of the ⊆ here: if α |= β, then α is a stronger assertion than β: it rules out more possible worlds.) The relation of entailment is familiar from arithmetic; we are happy with the idea that the sentence x = 0 entails the sentence x^y^ = 0. Obviously, in any model where x is zero, it is the case that x^y^ is zero (regardless of the value of y).
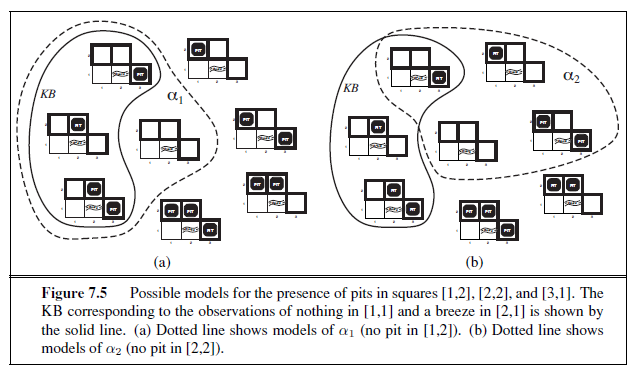
We can apply the same kind of analysis to the wumpus-world reasoning example given in the preceding section. Consider the situation in Figure 7.3(b): the agent has detected nothing in [1,1] and a breeze in [2,1]. These percepts, combined with the agent’s knowledge of the rules of the wumpus world, constitute the KB. The agent is interested (among other things) in whether the adjacent squares [1,2], [2,2], and [3,1] contain pits. Each of the three squares might or might not contain a pit, so (for the purposes of this example) there are 23 =8
possible models. These eight models are shown in Figure 7.5.2
The KB can be thought of as a set of sentences or as a single sentence that asserts all the individual sentences. The KB is false in models that contradict what the agent knows— for example, the KB is false in any model in which [1,2] contains a pit, because there is no breeze in [1,1]. There are in fact just three models in which the KB is true, and these are
2 Although the figure shows the models as partial wumpus worlds, they are really nothing more than assignments of true and false to the sentences “there is a pit in [1,2]” etc. Models, in the mathematical sense, do not need to have ’orrible ’airy wumpuses in them.
shown surrounded by a solid line in Figure 7.5. Now let us consider two possible conclusions:
α1 = “There is no pit in [1,2].” α2 = “There is no pit in [2,2].”
We have surrounded the models of α1 and α2 with dotted lines in Figures 7.5(a) and 7.5(b), respectively. By inspection, we see the following:
in every model in which KB is true, α1 is also true.
Hence, KB |= α1: there is no pit in [1,2]. We can also see that
in some models in which KB is true, α2 is false.
Hence, KB |≠ α2: the agent cannot conclude that there is no pit in [2,2]. (Nor can it conclude that there is a pit in [2,2].)^3^
The preceding example not only illustrates entailment but also shows how the definition of entailment can be applied to derive conclusions—that is, to carry out logical inference. The inference algorithm illustrated in Figure 7.5 is called model checking, because it enumerates all possible models to check that α is true in all models in which KB is true, that is, that M(KB) ⊆ M(α).
In understanding entailment and inference, it might help to think of the set of all consequences of KB as a haystack and of α as a needle. Entailment is like the needle being in the haystack; inference is like finding it. This distinction is embodied in some formal notation: if an inference algorithm i can derive α from KB , we write
KB |-~i~ α ,
which is pronounced “α is derived from KB by i” or “i derives α from KB .” An inference algorithm that derives only entailed sentences is called sound or truthpreserving. Soundness is a highly desirable property. An unsound inference procedure essentially makes things up as it goes along—it announces the discovery of nonexistent needles. It is easy to see that model checking, when it is applicable,4 is a sound procedure.
The property of completeness is also desirable: an inference algorithm is complete if it can derive any sentence that is entailed. For real haystacks, which are finite in extent, it seems obvious that a systematic examination can always decide whether the needle is in the haystack. For many knowledge bases, however, the haystack of consequences is infinite, and completeness becomes an important issue.5 Fortunately, there are complete inference procedures for logics that are sufficiently expressive to handle many knowledge bases.
We have described a reasoning process whose conclusions are guaranteed to be true in any world in which the premises are true; in particular, if KB is true in the real world, then any sentence α derived from KB by a sound inference procedure is also true in the real world. So, while an inference process operates on “syntax”—internal physical configurations such as bits in registers or patterns of electrical blips in brains—the process corresponds
3 The agent can calculate the probability that there is a pit in [2,2]; Chapter 13 shows how. 4 Model checking works if the space of models is finite—for example, in wumpus worlds of fixed size. For arithmetic, on the other hand, the space of models is infinite: even if we restrict ourselves to the integers, there are infinitely many pairs of values for x and y in the sentence x + y = 4. 5 Compare with the case of infinite search spaces in Chapter 3, where depth-first search is not complete.

to the real-world relationship whereby some aspect of the real world is the case6 by virtue of other aspects of the real world being the case. This correspondence between world and representation is illustrated in Figure 7.6.
The final issue to consider is grounding—the connection between logical reasoning processes and the real environment in which the agent exists. In particular, how do we know that KB is true in the real world? (After all, KB is just “syntax” inside the agent’s head.) This is a philosophical question about which many, many books have been written. (See Chapter 26.) A simple answer is that the agent’s sensors create the connection. For example, our wumpus-world agent has a smell sensor. The agent program creates a suitable sentence whenever there is a smell. Then, whenever that sentence is in the knowledge base, it is true in the real world. Thus, the meaning and truth of percept sentences are defined by the processes of sensing and sentence construction that produce them. What about the rest of the agent’s knowledge, such as its belief that wumpuses cause smells in adjacent squares? This is not a direct representation of a single percept, but a general rule—derived, perhaps, from perceptual experience but not identical to a statement of that experience. General rules like this are produced by a sentence construction process called learning, which is the subject of Part V. Learning is fallible. It could be the case that wumpuses cause smells except on February 29 in leap years, which is when they take their baths. Thus, KB may not be true in the real world, but with good learning procedures, there is reason for optimism.
PROPOSITIONAL LOGIC: A VERY SIMPLE LOGIC
We now present a simple but powerful logic called propositional logic. We cover the syntax of propositional logic and its semantics—the way in which the truth of sentences is determined. Then we look at entailment—the relation between a sentence and another sentence that follows from it—and see how this leads to a simple algorithm for logical inference. Everything takes place, of course, in the wumpus world.
6 As Wittgenstein (1922) put it in his famous Tractatus: “The world is everything that is the case.”
Syntax
The syntax of propositional logic defines the allowable sentences. The atomic sentences consist of a single proposition symbol. Each such symbol stands for a proposition that can be true or false. We use symbols that start with an uppercase letter and may contain other letters or subscripts, for example: P , Q, R, W~1,3~ and North . The names are arbitrary but are often chosen to have some mnemonic value—we use W~1,3~ to stand for the proposition that the wumpus is in [1,3]. (Remember that symbols such as W~1,3~ are atomic, i.e., W , 1, and 3 are not meaningful parts of the symbol.) There are two proposition symbols with fixed meanings: True is the always-true proposition and False is the always-false proposition. Complex sentences are constructed from simpler sentences, using parentheses and logical connectives. There are five connectives in common use:
-
¬ (not). A sentence such as ¬W~1,3~ is called the negation of W~1,3~. A literal is either an atomic sentence (a positive literal) or a negated atomic sentence (a negative literal).
-
∧ (and). A sentence whose main connective is ∧, such as W~1,3~ ∧ P~3,1~, is called a conjunction; its parts are the conjuncts. (The ∧ looks like an “A” for “And.”)
-
∨ (or). A sentence using ∨, such as (W~1,3~∧P~3,1~)∨W~2,2~, is a disjunction of the disjuncts (W~1,3~ ∧ P~3,1~) and W~2,2~. (Historically, the ∨ comes from the Latin “vel,” which means “or.” For most people, it is easier to remember ∨ as an upside-down ∧.)
-
⇒ (implies). A sentence such as (W~1,3~∧P~3,1~) ⇒ ¬W~2,2~ is called an implication (or conditional). Its premise or antecedent is (W~1,3~∧P~3,1~), and its conclusion or consequent is ¬W~2,2~. Implications are also known as rules or if–then statements. The implication RULES symbol is sometimes written in other books as ⊃ or →.
⇔ (if and only if). The sentence W~1,3~ ⇔ ¬W~2,2~ is a biconditional. Some other books write this as ≡.
Sentence → AtomicSentence | ComplexSentence
AtomicSentence → True | False | P | Q | R | . . .
ComplexSentence → ( Sentence ) | [ Sentence ]
| ¬ Sentence
| Sentence ∧ Sentence
| Sentence ∨ Sentence
| Sentence ⇒ Sentence
| Sentence ⇔ Sentence
OPERATOR PRECEDENCE : ¬,∧,∨,⇒,⇔
Figure 7.7 A BNF (Backus–Naur Form) grammar of sentences in propositional logic, along with operator precedences, from highest to lowest.
Figure 7.7 gives a formal grammar of propositional logic; see page 1060 if you are not familiar with the BNF notation. The BNF grammar by itself is ambiguous; a sentence with several operators can be parsed by the grammar in multiple ways. To eliminate the ambiguity we define a precedence for each operator. The “not” operator (¬) has the highest precedence, which means that in the sentence ¬A ∧ B the ¬ binds most tightly, giving us the equivalent of (¬A)∧B rather than ¬(A∧B). (The notation for ordinary arithmetic is the same: −2+4 is 2, not –6.) When in doubt, use parentheses to make sure of the right interpretation. Square brackets mean the same thing as parentheses; the choice of square brackets or parentheses is solely to make it easier for a human to read a sentence.
Semantics
Having specified the syntax of propositional logic, we now specify its semantics. The semantics defines the rules for determining the truth of a sentence with respect to a particular model. In propositional logic, a model simply fixes the truth value—true or false—for every proposition symbol. For example, if the sentences in the knowledge base make use of the proposition symbols P~1,2~, P~2,2~, and P~3,1~, then one possible model is
M~1~ = {P~1,2~ = false, P~2,2~ = false, P~3,1~ = true} .
With three proposition symbols, there are 23 = 8 possible models—exactly those depicted in Figure 7.5. Notice, however, that the models are purely mathematical objects with no necessary connection to wumpus worlds. P~1,2~ is just a symbol; it might mean “there is a pit in [1,2]” or “I’m in Paris today and tomorrow.”
The semantics for propositional logic must specify how to compute the truth value of any sentence, given a model. This is done recursively. All sentences are constructed from atomic sentences and the five connectives; therefore, we need to specify how to compute the truth of atomic sentences and how to compute the truth of sentences formed with each of the five connectives. Atomic sentences are easy:
-
True is true in every model and False is false in every model.
-
The truth value of every other proposition symbol must be specified directly in the model. For example, in the model M~1~ given earlier, P~1,2~ is false.
For complex sentences, we have five rules, which hold for any subsentences P and Q in any model m (here “iff” means “if and only if”):
-
¬P is true iff P is false in m.
-
P ∧Q is true iff both P and Q are true in m.
-
P ∨Q is true iff either P or Q is true in m.
-
P ⇒ Q is true unless P is true and Q is false in m.
-
P ⇔ Q is true iff P and Q are both true or both false in m.
The rules can also be expressed with truth tables that specify the truth value of a complex sentence for each possible assignment of truth values to its components. Truth tables for the five connectives are given in Figure 7.8. From these tables, the truth value of any sentence s can be computed with respect to any model m by a simple recursive evaluation. For example,
| P | Q | ¬P | P ∧Q | P ∨Q | P ⇒ Q | P ⇔ Q |
|---|---|---|---|---|---|---|
| false | false | true | false | false | true | true |
| false | true | true | false | true | true | false |
| true | false | false | false | true | false | false |
| true | true | false | true | true | true | true |
Figure 7.8 Truth tables for the five logical connectives. To use the table to compute, for example, the value of P ∨Q when P is true and Q is false, first look on the left for the row where P is true and Q is false (the third row). Then look in that row under the P ∨Q column to see the result: true.
the sentence ¬P~1,2~ ∧ (P~2,2~ ∨ P~3,1~), evaluated in M~1~, gives true ∧ (false ∨ true)= true ∧
true = true . Exercise 7.3 asks you to write the algorithm PL-TRUE?(s, m), which computes the truth value of a propositional logic sentence s in a model m.
The truth tables for “and,” “or,” and “not” are in close accord with our intuitions about the English words. The main point of possible confusion is that P ∨Q is true when P is true or Q is true or both. A different connective, called “exclusive or” (“xor” for short), yields false when both disjuncts are true.7 There is no consensus on the symbol for exclusive or; some choices are ∨̇ or ≠ or ⊕.
The truth table for ⇒ may not quite fit one’s intuitive understanding of “P implies Q” or “if P then Q.” For one thing, propositional logic does not require any relation of causation or relevance between P and Q. The sentence “5 is odd implies Tokyo is the capital of Japan” is a true sentence of propositional logic (under the normal interpretation), even though it is a decidedly odd sentence of English. Another point of confusion is that any implication is true whenever its antecedent is false. For example, “5 is even implies Sam is smart” is true, regardless of whether Sam is smart. This seems bizarre, but it makes sense if you think of “P ⇒ Q” as saying, “If P is true, then I am claiming that Q is true. Otherwise I am making no claim.” The only way for this sentence to be false is if P is true but Q is false.
The biconditional, P ⇔ Q, is true whenever both P ⇒ Q and Q ⇒ P are true. In English, this is often written as “P if and only if Q.” Many of the rules of the wumpus world are best written using ⇔. For example, a square is breezy if a neighboring square has a pit, and a square is breezy only if a neighboring square has a pit. So we need a biconditional,
B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~) ,
where B~1,1~ means that there is a breeze in [1,1].
A simple knowledge base
Now that we have defined the semantics for propositional logic, we can construct a knowledge base for the wumpus world. We focus first on the immutable aspects of the wumpus world, leaving the mutable aspects for a later section. For now, we need the following symbols for each [x, y] location:
7 Latin has a separate word, aut, for exclusive or.
P~x,y~ is true if there is a pit in [x, y]. W~x,y~ is true if there is a wumpus in [x, y], dead or alive. B~x,y~ is true if the agent perceives a breeze in [x, y]. S~x,y~ is true if the agent perceives a stench in [x, y].
The sentences we write will suffice to derive ¬P~1,2~ (there is no pit in [1,2]), as was done informally in Section 7.3. We label each sentence Ri so that we can refer to them:
- There is no pit in [1,1]:
R~1~ : ¬P~1,1~ .
- A square is breezy if and only if there is a pit in a neighboring square. This has to be stated for each square; for now, we include just the relevant squares:
R~2~ : B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~) .
R~3~ : B~2,1~ ⇔ (P~1,1~ ∨ P~2,2~ ∨ P~3,1~) .
- The preceding sentences are true in all wumpus worlds. Now we include the breeze percepts for the first two squares visited in the specific world the agent is in, leading up to the situation in Figure 7.3(b).
R~4~ : ¬B~1,1~ .
R~5~ : B~2,1~ .
A simple inference procedure
Our goal now is to decide whether KB |= α for some sentence α. For example, is ¬P~1,2~ entailed by our KB? Our first algorithm for inference is a model-checking approach that is a direct implementation of the definition of entailment: enumerate the models, and check that α is true in every model in which KB is true. Models are assignments of true or false to every proposition symbol. Returning to our wumpus-world example, the relevant proposi- tion symbols are B~1,1~, B~2,1~, P~1,1~, P~1,2~, P~2,1~, P~2,2~, and P~3,1~. With seven symbols, there are 27 = 128 possible models; in three of these, KB is true (Figure 7.9). In those three models, ¬P~1,2~ is true, hence there is no pit in [1,2]. On the other hand, P~2,2~ is true in two of the three models and false in one, so we cannot yet tell whether there is a pit in [2,2].
Figure 7.9 reproduces in a more precise form the reasoning illustrated in Figure 7.5. A general algorithm for deciding entailment in propositional logic is shown in Figure 7.10. Like the BACKTRACKING-SEARCH algorithm on page 215, TT-ENTAILS? performs a recursive enumeration of a finite space of assignments to symbols. The algorithm is sound because it implements directly the definition of entailment, and complete because it works for any KB and α and always terminates—there are only finitely many models to examine.
Of course, “finitely many” is not always the same as “few.” If KB and α contain n symbols in all, then there are 2^n^ models. Thus, the time complexity of the algorithm is O(2^n^). (The space complexity is only O(n) because the enumeration is depth-first.) Later in this chapter we show algorithms that are much more efficient in many cases. Unfortunately, propositional entailment is co-NP-complete (i.e., probably no easier than NP-complete—see Appendix A), so every known inference algorithm for propositional logic has a worst-case complexity that is exponential in the size of the input.
| B~1,1~ | B~2,1~ | P~1,1~ | P~1,2~ | P~2,1~ | P~2,2~ | P~3,1~ | R~1~ | R~2~ | R~3~ | R~4~ | R~5~ | KB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| false | false | false | false | false | false | false | true | true | true | true | false | false |
| false | false | false | false | false | false | true | true | true | false | true | false | false |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| false | true | false | false | false | false | false | true | true | false | true | true | false |
| false | true | false | false | false | false | true | true | true | true | true | true | true |
| false | true | false | false | false | true | false | true | true | true | true | true | true |
| false | true | false | false | false | true | true | true | true | true | true | true | true |
| false | true | false | false | true | false | false | true | false | false | true | true | false |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| . | . | . | . | . | . | . | . | . | . | . | . | . |
| true | true | true | true | true | true | true | false | true | true | false | true | false |
Figure 7.9 A truth table constructed for the knowledge base given in the text. KB is true if R~1~ through R~5~ are true, which occurs in just 3 of the 128 rows (the ones underlined in the right-hand column). In all 3 rows, P~1,2~ is false, so there is no pit in [1,2]. On the other hand, there might (or might not) be a pit in [2,2].
function TT-ENTAILS?(KB , α) returns true or false
inputs: KB , the knowledge base, a sentence in propositional logic α, the query, a sentence in propositional logic
symbols← a list of the proposition symbols in KB and α return TT-CHECK-ALL(KB , α, symbols ,{ })
function TT-CHECK-ALL(KB , α, symbols ,model ) returns true or false
if EMPTY?(symbols) then if PL-TRUE?(KB ,model ) then return PL-TRUE?(α,model ) else return true // when KB is false, always return true
else do P ← FIRST(symbols) rest←REST(symbols) return (TT-CHECK-ALL(KB , α, rest ,model ∪ {P = true}) and TT-CHECK-ALL(KB , α, rest ,model ∪ {P = false }))
Figure 7.10 A truth-table enumeration algorithm for deciding propositional entailment. (TT stands for truth table.) PL-TRUE? returns true if a sentence holds within a model. The variable model represents a partial model—an assignment to some of the symbols. The key- word “and” is used here as a logical operation on its two arguments, returning true or false .
(α ∧ β) ≡ (β ∧ α) commutativity of ∧ (α ∨ β) ≡ (β ∨ α) commutativity of ∨ ((α ∧ β) ∧ γ) ≡ (α ∧ (β ∧ γ)) associativity of ∧ ((α ∨ β) ∨ γ) ≡ (α ∨ (β ∨ γ)) associativity of ∨ ¬(¬α) ≡ α double-negation elimination (α ⇒ β) ≡ (¬β ⇒ ¬α) contraposition (α ⇒ β) ≡ (¬α ∨ β) implication elimination (α ⇔ β) ≡ ((α ⇒ β) ∧ (β ⇒ α)) biconditional elimination ¬(α ∧ β) ≡ (¬α ∨ ¬β) De Morgan ¬(α ∨ β) ≡ (¬α ∧ ¬β) De Morgan (α ∧ (β ∨ γ)) ≡ ((α ∧ β) ∨ (α ∧ γ)) distributivity of ∧ over ∨ (α ∨ (β ∧ γ)) ≡ ((α ∨ β) ∧ (α ∨ γ)) distributivity of ∨ over ∧
Figure 7.11 Standard logical equivalences. The symbols α, β, and γ stand for arbitrary sentences of propositional logic.
PROPOSITIONAL THEOREM PROVING
So far, we have shown how to determine entailment by model checking: enumerating models and showing that the sentence must hold in all models. In this section, we show how entailment can be done by theorem proving applying rules of inference directly to the sentences in our knowledge base to construct a proof of the desired sentence without consulting models. If the number of models is large but the length of the proof is short, then theorem proving can be more efficient than model checking.
Before we plunge into the details of theorem-proving algorithms, we will need some additional concepts related to entailment. The first concept is logical equivalence: two sentences α and β are logically equivalent if they are true in the same set of models. We write this as α ≡ β. For example, we can easily show (using truth tables) that P ∧ Q and Q ∧ P are logically equivalent; other equivalences are shown in Figure 7.11. These equivalences play much the same role in logic as arithmetic identities do in ordinary mathematics. An alternative definition of equivalence is as follows: any two sentences α and β are equivalent only if each of them entails the other:
α ≡ β if and only if α |= β and β |= α .
The second concept we will need is validity. A sentence is valid if it is true in all models. For example, the sentence P ∨¬P is valid. Valid sentences are also known as tautologies—they are necessarily true. Because the sentence True is true in all models, every valid sentence is logically equivalent to True . What good are valid sentences? From our definition of entailment, we can derive the deduction theorem, which was known to the ancient Greeks:
For any sentences α and β_,_ α |= β if and only if the sentence (α ⇒ β) is valid.
(Exercise 7.5 asks for a proof.) Hence, we can decide if α |= β by checking that (α ⇒ β) is true in every model—which is essentially what the inference algorithm in Figure 7.10 does or by proving that (α ⇒ β) is equivalent to True . Conversely, the deduction theorem states that every valid implication sentence describes a legitimate inference.
The final concept we will need is satisfiability. A sentence is satisfiable if it is true in, or satisfied by, some model. For example, the knowledge base given earlier, (R~1~ ∧ R~2~ ∧ R~3~ ∧ R~4~ ∧ R~5~), is satisfiable because there are three models in which it is true, as shown in Figure 7.9. Satisfiability can be checked by enumerating the possible models until one is found that satisfies the sentence. The problem of determining the satisfiability of sentences in propositional logic—the SAT problem—was the first problem proved to be NP-complete. Many problems in computer science are really satisfiability problems. For example, all the constraint satisfaction problems in Chapter 6 ask whether the constraints are satisfiable by some assignment.
Validity and satisfiability are of course connected: α is valid iff ¬α is unsatisfiable; contrapositively, α is satisfiable iff ¬α is not valid. We also have the following useful result:
α |= β if and only if the sentence (α ∧ ¬β) is unsatisfiable.
Proving β from α by checking the unsatisfiability of (α ∧ ¬β) corresponds exactly to the standard mathematical proof technique of reductio ad absurdum (literally, “reduction to an absurd thing”). It is also called proof by refutation or proof by contradiction. One assumes a sentence β to be false and shows that this leads to a contradiction with known axioms α. This contradiction is exactly what is meant by saying that the sentence (α ∧ ¬β) is unsatisfiable.
Inference and proofs
This section covers inference rules that can be applied to derive a proof—a chain of conclu-INFERENCE RULES
PROOF sions that leads to the desired goal. The best-known rule is called Modus Ponens (Latin for MODUS PONENS mode that affirms) and is written
α ⇒ β, α / β.
The notation means that, whenever any sentences of the form α ⇒ β and α are given, then the sentence β can be inferred. For example, if (WumpusAhead ∧WumpusAlive) ⇒ Shoot
and (WumpusAhead ∧WumpusAlive) are given, then Shoot can be inferred. Another useful inference rule is And-Elimination, which says that, from a conjunction,AND-ELIMINATION
any of the conjuncts can be inferred: α ∧ β / α.
For example, from (WumpusAhead ∧ WumpusAlive), WumpusAlive can be inferred.
By considering the possible truth values of α and β, one can show easily that Modus Ponens and And-Elimination are sound once and for all. These rules can then be used in any particular instances where they apply, generating sound inferences without the need for enumerating models.
All of the logical equivalences in Figure 7.11 can be used as inference rules. For example, the equivalence for biconditional elimination yields the two inference rules
α ⇔ β / (α ⇒ β) ∧ (β ⇒ α) and (α ⇒ β) ∧ (β ⇒ α) / α ⇔ β .
Not all inference rules work in both directions like this. For example, we cannot run Modus Ponens in the opposite direction to obtain α ⇒ β and α from β.
Let us see how these inference rules and equivalences can be used in the wumpus world. We start with the knowledge base containing R~1~ through R~5~ and show how to prove ¬P~1,2~, that is, there is no pit in [1,2]. First, we apply biconditional elimination to R~2~ to obtain
R~6~ : (B~1,1~ ⇒ (P~1,2~ ∨ P~2,1~)) ∧ ((P~1,2~ ∨ P~2,1~) ⇒ B~1,1~) .
Then we apply And-Elimination to R~6~ to obtain
R~7~ : ((P~1,2~ ∨ P~2,1~) ⇒ B~1,1~) .
Logical equivalence for contrapositives gives
R~8~ : (¬B~1,1~ ⇒ ¬(P~1,2~ ∨ P~2,1~)) .
Now we can apply Modus Ponens with R~8~ and the percept R~4~ (i.e., ¬B~1,1~), to obtain
R~9~ : ¬(P~1,2~ ∨ P~2,1~) .
Finally, we apply De Morgan’s rule, giving the conclusion
R~1~0 : ¬P~1,2~ ∧ ¬P~2,1~ .
That is, neither [1,2] nor [2,1] contains a pit. We found this proof by hand, but we can apply any of the search algorithms in Chapter 3
to find a sequence of steps that constitutes a proof. We just need to define a proof problem as follows:
-
INITIAL STATE: the initial knowledge base.
-
ACTIONS: the set of actions consists of all the inference rules applied to all the sentences that match the top half of the inference rule.
-
RESULT: the result of an action is to add the sentence in the bottom half of the inference rule.
-
GOAL: the goal is a state that contains the sentence we are trying to prove.
Thus, searching for proofs is an alternative to enumerating models. In many practical cases finding a proof can be more efficient because the proof can ignore irrelevant propositions, no matter how many of them there are. For example, the proof given earlier leading to ¬P~1,2~ ∧ ¬P~2,1~ does not mention the propositions B~2,1~, P~1,1~, P~2,2~, or P~3,1~. They can be ignored because the goal proposition, P~1,2~, appears only in sentence R~2~; the other propositions in R~2~ appear only in R~4~ and R~2~; so R~1~, R~3~, and R~5~ have no bearing on the proof. The same would hold even if we added a million more sentences to the knowledge base; the simple truth-table algorithm, on the other hand, would be overwhelmed by the exponential explosion of models.
One final property of logical systems is monotonicity, which says that the set of en-MONOTONICITY
tailed sentences can only increase as information is added to the knowledge base.8 For any sentences α and β,
if KB |= α then KB ∧ β |= α .
8 Nonmonotonic logics, which violate the monotonicity property, capture a common property of human reasoning: changing one’s mind. They are discussed in Section 12.6.
For example, suppose the knowledge base contains the additional assertion β stating that there are exactly eight pits in the world. This knowledge might help the agent draw additional conclusions, but it cannot invalidate any conclusion α already inferred—such as the conclusion that there is no pit in [1,2]. Monotonicity means that inference rules can be applied whenever suitable premises are found in the knowledge base—the conclusion of the rule must follow regardless of what else is in the knowledge base.
Proof by resolution
We have argued that the inference rules covered so far are sound, but we have not discussed the question of completeness for the inference algorithms that use them. Search algorithms such as iterative deepening search (page 89) are complete in the sense that they will find any reachable goal, but if the available inference rules are inadequate, then the goal is not reachable—no proof exists that uses only B~1,2~ those inference rules. For example, if we removed the biconditional elimination rule, the proof in the preceding section would not go through. The current section introduces a single inference rule, resolution, that yields a complete inference algorithm when coupled with any complete search algorithm.
We begin by using a simple version of the resolution rule in the wumpus world. Let us consider the steps leading up to Figure 7.4(a): the agent returns from [2,1] to [1,1] and then goes to [1,2], where it perceives a stench, but no breeze. We add the following facts to the knowledge base:
R~11~ : ¬B~1,2~ .
R~12~ : B~1,2~ ⇔ (P~1,1~ ∨ P~2,2~ ∨ P~1,3~) .
By the same process that led to R~10~ earlier, we can now derive the absence of pits in [2,2] and [1,3] (remember that [1,1] is already known to be pitless):
R~13~ : ¬P~2,2~ .
R~14~ : ¬P~1,3~ .
We can also apply biconditional elimination to R~3~, followed by Modus Ponens with R~5~, to obtain the fact that there is a pit in [1,1], [2,2], or [3,1]:
R~15~ : P~1,1~ ∨ P~2,2~ ∨ P~3,1~ .
Now comes the first application of the resolution rule: the literal ¬P~2,2~ in R~1~3 resolves with the literal P~2,2~ in R~15~ to give the resolvent
R~16~ : P~1,1~ ∨ P~3,1~ .
In English; if there’s a pit in one of [1,1], [2,2], and [3,1] and it’s not in [2,2], then it’s in [1,1] or [3,1]. Similarly, the literal ¬P~1,1~ in R~1~ resolves with the literal P~1,1~ in R~16~ to give
R~17~ : P~3,1~ .
In English: if there’s a pit in [1,1] or [3,1] and it’s not in [1,1], then it’s in [3,1]. These last two inference steps are examples of the unit resolution inference rule,UNIT RESOLUTION
l~1~ ∨ · · · ∨ l~k~, m
l~1~ ∨ · · · ∨ li−1 ∨ li+1 ∨ · · · ∨ l~k~ ,
where each l is a literal and li and m are complementary literals (i.e., one is the negation of the other). Thus, the unit resolution rule takes a clause—a disjunction of literals—and a literal and produces a new clause. Note that a single literal can be viewed as a disjunction of one literal, also known as a unit clause.
The unit resolution rule can be generalized to the full resolution rule,RESOLUTION
l~1~ ∨ · · · ∨ l~k~, m~1~ ∨ · · · ∨ m~n~ / l~1~ ∨ · · · ∨ l~i−1~ ∨ l~i+1~ ∨ · · · ∨ l~k~ ∨ m~1~ ∨ · · · ∨ m~j−1~ ∨ m~j+1~ ∨ · · · ∨ m~n~,
where li and mj are complementary literals. This says that resolution takes two clauses and produces a new clause containing all the literals of the two original clauses except the two complementary literals. For example, we have
P~1,1~ ∨ P~3,1~, ¬P~1,1~ ∨ ¬P~2,2~ / P~3,1~ ∨ ¬P~2,2~ .
There is one more technical aspect of the resolution rule: the resulting clause should contain only one copy of each literal.9 The removal of multiple copies of literals is called factoring. For example, if we resolve (A ∨B) with (A ∨ ¬B), we obtain (A ∨A), which is reduced to just A.
The soundness of the resolution rule can be seen easily by considering the literal l~i~ that is complementary to literal m~j~ in the other clause. If l~i~ is true, then m~j~ is false, and hence m~1~ ∨ · · · ∨ m~j−1~ ∨ m~j+1~ ∨ · · · ∨ m~n~ must be true, because m~1~ ∨ · · · ∨ m~n~ is given. If l~i~ is false, then l~1~ ∨ · · · ∨ l~i−1~ ∨ l~i+1~ ∨ · · · ∨ l~k~ must be true because l~1~ ∨ · · · ∨ l~k~ is given. Now l~i~ is either true or false, so one or other of these conclusions holds—exactly as the resolution rule states.
What is more surprising about the resolution rule is that it forms the basis for a family of complete inference procedures. A resolution-based theorem prover can, for any sentences α and β in propositional logic, decide whether α |= β_._ The next two subsections explain how resolution accomplishes this.
Conjunctive normal form
The resolution rule applies only to clauses (that is, disjunctions of literals), so it would seem to be relevant only to knowledge bases and queries consisting of clauses. How, then, can it lead to a complete inference procedure for all of propositional logic? The answer is that every sentence of propositional logic is logically equivalent to a conjunction of clauses. A sentence expressed as a conjunction of clauses is said to be in conjunctive normal form or CNF (see Figure 7.14). We now describe a procedure for converting to CNF. We illustrate the procedure by converting the sentence B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~) into CNF. The steps are as follows:
- Eliminate ⇔, replacing α ⇔ β with (α ⇒ β) ∧ (β ⇒ α).
(B~1,1~ ⇒ (P~1,2~ ∨ P~2,1~)) ∧ ((P~1,2~ ∨ P~2,1~) ⇒ B~1,1~) .
- Eliminate ⇒, replacing α ⇒ β with ¬α ∨ β:
(¬B~1,1~ ∨ P~1,2~ ∨ P~2,1~) ∧ (¬(P~1,2~ ∨ P~2,1~) ∨B~1,1~) .
9 If a clause is viewed as a set of literals, then this restriction is automatically respected. Using set notation for clauses makes the resolution rule much cleaner, at the cost of introducing additional notation.
- CNF requires ¬ to appear only in literals, so we “move ¬ inwards” by repeated application of the following equivalences from Figure 7.11:
¬(¬α) ≡ α (double-negation elimination) ¬(α ∧ β) ≡ (¬α ∨ ¬β) (De Morgan) ¬(α ∨ β) ≡ (¬α ∧ ¬β) (De Morgan)
In the example, we require just one application of the last rule:
(¬B~1,1~ ∨ P~1,2~ ∨ P~2,1~) ∧ ((¬P~1,2~ ∧ ¬P~2,1~) ∨B~1,1~) .
- Now we have a sentence containing nested ∧ and ∨ operators applied to literals. We apply the distributivity law from Figure 7.11, distributing ∨ over ∧ wherever possible.
(¬B~1,1~ ∨ P~1,2~ ∨ P~2,1~) ∧ (¬P~1,2~ ∨B~1,1~) ∧ (¬P~2,1~ ∨B~1,1~) .
The original sentence is now in CNF, as a conjunction of three clauses. It is much harder to read, but it can be used as input to a resolution procedure.
A resolution algorithm
Inference procedures based on resolution work by using the principle of proof by contradiction introduced on page 250. That is, to show that KB |= α, we show that (KB ∧ ¬α) is unsatisfiable. We do this by proving a contradiction.
A resolution algorithm is shown in Figure 7.12. First, (KB ∧ ¬α) is converted into CNF. Then, the resolution rule is applied to the resulting clauses. Each pair that contains complementary literals is resolved to produce a new clause, which is added to the set if it is not already present. The process continues until one of two things happens:
-
there are no new clauses that can be added, in which case KB does not entail α; or,
-
two clauses resolve to yield the empty clause, in which case KB entails α.
The empty clause—a disjunction of no disjuncts—is equivalent to False because a disjunction is true only if at least one of its disjuncts is true. Another way to see that an empty clause represents a contradiction is to observe that it arises only from resolving two complementary unit clauses such as P and ¬P .
We can apply the resolution procedure to a very simple inference in the wumpus world. When the agent is in [1,1], there is no breeze, so there can be no pits in neighboring squares. The relevant knowledge base is
KB = R~2~ ∧ R~4~ = (B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~)) ∧ ¬B~1,1~
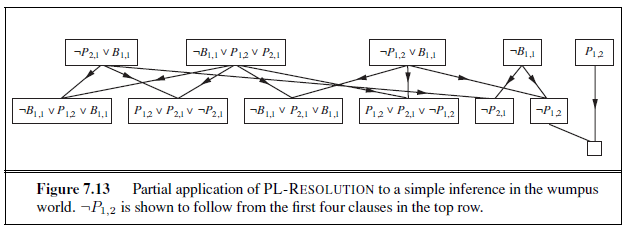
and we wish to prove α which is, say, ¬P~1,2~. When we convert (KB ∧ ¬α) into CNF, we obtain the clauses shown at the top of Figure 7.13. The second row of the figure shows clauses obtained by resolving pairs in the first row. Then, when P~1,2~ is resolved with ¬P~1,2~, we obtain the empty clause, shown as a small square. Inspection of Figure 7.13 reveals that many resolution steps are pointless. For example, the clause B~1,1~∨¬B~1,1~∨P~1,2~ is equivalent to True ∨ P~1,2~ which is equivalent to True . Deducing that True is true is not very helpful. Therefore, any clause in which two complementary literals appear can be discarded.
function PL-RESOLUTION(KB , α) returns true or false
inputs: KB , the knowledge base, a sentence in propositional logic α, the query, a sentence in propositional logic
clauses← the set of clauses in the CNF representation of KB ∧ ¬α new←{} loop do for each pair of clauses Ci, Cj in clauses do
resolvents← PL-RESOLVE(Ci, Cj ) if resolvents contains the empty clause then return true
new←new ∪ resolvents if new ⊆ clauses then return false clauses← clauses ∪new
Figure 7.12 A simple resolution algorithm for propositional logic. The function PL-RESOLVE returns the set of all possible clauses obtained by resolving its two inputs.
Completeness of resolution
To conclude our discussion of resolution, we now show why PL-RESOLUTION is complete. To do this, we introduce the resolution closure RC (S) of a set of clauses S, which is the set of all clauses derivable by repeated application of the resolution rule to clauses in S or their derivatives. The resolution closure is what PL-RESOLUTION computes as the final value of the variable clauses . It is easy to see that RC (S) must be finite, because there are only finitely many distinct clauses that can be constructed out of the symbols P~1~, . . . , P~k~ that appear in S. (Notice that this would not be true without the factoring step that removes multiple copies of literals.) Hence, PL-RESOLUTION always terminates.
The completeness theorem for resolution in propositional logic is called the ground resolution theorem:
If a set of clauses is unsatisfiable, then the resolution closure of those clauses contains the empty clause.
This theorem is proved by demonstrating its contrapositive: if the closure RC (S) does not contain the empty clause, then S is satisfiable. In fact, we can construct a model for S with suitable truth values for P~1~, . . . , P~k~. The construction procedure is as follows:
For i from 1 to k,
– If a clause in RC (S) contains the literal ¬P~i~ and all its other literals are false under the assignment chosen for P~1~, . . . , P~i−1~, then assign false to P~i~.
– Otherwise, assign true to P~i~.
This assignment to P~1~, . . . , P~k~ is a model of S. To see this, assume the opposite—that, at some stage i in the sequence, assigning symbol P~i~ causes some clause C to become false. For this to happen, it must be the case that all the other literals in C must already have been falsified by assignments to P~1~, . . . , P~i−1~. Thus, C must now look like either (false ∨ false ∨ · · · false ∨ P~i~) or like (false ∨ false ∨ · · · false ∨ ¬P~i~). If just one of these two is in RC(S), then the algorithm will assign the appropriate truth value to P~i to make C true, so C can only be falsified if both of these clauses are in RC(S). Now, since RC(S) is closed under resolution, it will contain the resolvent of these two clauses, and that resolvent will have all of its literals already falsified by the assignments to P~1~, . . . , P~i−1~. This contradicts our assumption that the first falsified clause appears at stage i. Hence, we have proved that the construction never falsifies a clause in RC(S); that is, it produces a model of RC(S) and thus a model of S itself (since S is contained in RC(S)).
Horn clauses and definite clauses
The completeness of resolution makes it a very important inference method. In many practical situations, however, the full power of resolution is not needed. Some real-world knowledge bases satisfy certain restrictions on the form of sentences they contain, which enables them to use a more restricted and efficient inference algorithm.
One such restricted form is the definite clause, which is a disjunction of literals of which exactly one is positive. For example, the clause (¬l~1~,1 ∨ ¬Breeze ∨ B~1,1~) is a definite clause, whereas (¬B~1,1~ ∨ P~1,2~ ∨ P~2,1~) is not.
Slightly more general is the Horn clause, which is a disjunction of literals of which at most one is positive. So all definite clauses are Horn clauses, as are clauses with no positive literals; these are called goal clauses. Horn clauses are closed under resolution: if you resolve two Horn clauses, you get back a Horn clause. Knowledge bases containing only definite clauses are interesting for three reasons:
- Every definite clause can be written as an implication whose premise is a conjunction of positive literals and whose conclusion is a single positive literal. (See Exercise 7.13.) For example, the definite clause (¬l~1,1~ ∨ ¬Breeze ∨ B~1,1~) can be written as the implication (l~1,1~ ∧ Breeze) ⇒ B~1,1~. In the implication form, the sentence is easier to understand: it says that if the agent is in [1,1] and there is a breeze, then [1,1] is breezy. In Horn form, the premise is called the body and the conclusion is called the head. sentence consisting of a single positive literal, such as l~1,1~, is called a fact. It too can FACT be written in implication form as True ⇒ l~1,1~, but it is simpler to write just l~1,1~.
CNFSentence → Clause~1~ ∧ · · · ∧ Clause~n~
Clause → Literal~1~ ∨ · · · ∨ Literal~m~
Literal → Symbol | ¬Symbol
Symbol → P | Q | R | . . .
HornClauseForm → DefiniteClauseForm | GoalClauseForm
DefiniteClauseForm → (Symbol~1~ ∧ · · · ∧ Symbol~l~) ⇒ Symbol
GoalClauseForm → (Symbol~1~ ∧ · · · ∧ Symbol~l~) ⇒ False
Figure 7.14 A grammar for conjunctive normal form, Horn clauses, and definite clauses. A clause such as A ∧ B ⇒ C is still a definite clause when it is written as ¬A ∨ ¬B ∨ C, but only the former is considered the canonical form for definite clauses. One more class is the k-CNF sentence, which is a CNF sentence where each clause has at most k literals.
-
Inference with Horn clauses can be done through the forward-chaining and backwar-chaining algorithms, which we explain next. Both of these algorithms are natural, in that the inference steps are obvious and easy for humans to follow. This type of inference is the basis for logic programming, which is discussed in Chapter 9.
-
Deciding entailment with Horn clauses can be done in time that is linear in the size of the knowledge base—a pleasant surprise.
Forward and backward chaining
The forward-chaining algorithm PL-FC-ENTAILS?(KB , q) determines if a single proposition symbol q—the query—is entailed by a knowledge base of definite clauses. It begins from known facts (positive literals) in the knowledge base. If all the premises of an implication are known, then its conclusion is added to the set of known facts. For example, if L~1,1~ and Breeze are known and (L~1,1~ ∧ Breeze) ⇒ B~1,1~ is in the knowledge base, then B~1,1~ can be added. This process continues until the query q is added or until no further inferences can be made. The detailed algorithm is shown in Figure 7.15; the main point to remember is that it runs in linear time.
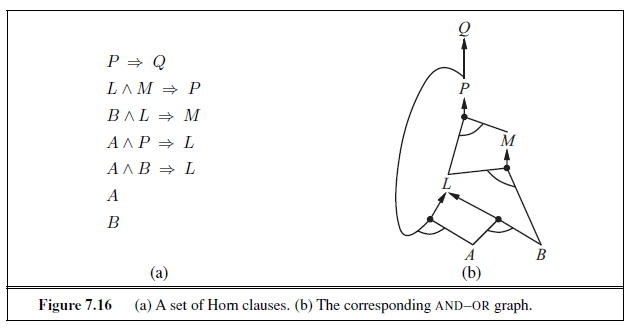
The best way to understand the algorithm is through an example and a P~icture. Figure 7.16(a) shows a simple knowledge base of Horn clauses with A and B as known facts. Figure 7.16(b) shows the same knowledge base drawn as an AND–OR graph (see Chapter 4). In AND–OR graphs, multiple links joined by an arc indicate a conjunction—every link must be proved—while multiple links without an arc indicate a disjunction—any link can be proved. It is easy to see how forward chaining works in the graph. The known leaves (here, A and B) are set, and inference propagates up the graph as far as possible. Wherever a conjunction appears, the propagation waits until all the conjuncts are known before proceeding. The reader is encouraged to work through the example in detail.
function PL-FC-ENTAILS?(KB , q) returns true or false
inputs: KB , the knowledge base, a set of propositional definite clauses q , the query, a proposition symbol
count← a table, where count[c] is the number of symbols in c’s premise inferred← a table, where inferred [s] is initially false for all symbols agenda← a queue of symbols, initially symbols known to be true in KB
while agenda is not empty do p← POP(agenda) if p = q then return true
if inferred [p] = false then inferred [p]← true
for each clause c in KB where p is in c.PREMISE do decrement count[c] if count[c] = 0 then add c.CONCLUSION to agenda
return false
Figure 7.15 The forward-chaining algorithm for propositional logic. The agenda keeps track of symbols known to be true but not yet “processed.” The count table keeps track of how many premises of each implication are as yet unknown. Whenever a new symbol p from the agenda is processed, the count is reduced by one for each implication in whose premise p appears (easily identified in constant time with appropriate indexing.) If a count reaches zero, all the premises of the implication are known, so its conclusion can be added to the agenda. Finally, we need to keep track of which symbols have been processed; a symbol that is already in the set of inferred symbols need not be added to the agenda again. This avoids redundant work and prevents loops caused by implications such as P ⇒ Q and Q⇒ P .
It is easy to see that forward chaining is sound: every inference is essentially an application of Modus Ponens. Forward chaining is also complete: every entailed atomic sentence will be derived. The easiest way to see this is to consider the final state of the inferred table (after the algorithm reaches a fixed point where no new inferences are possible). The table contains true for each symbol inferred during the process, and false for all other symbols. We can view the table as a logical model; moreover, every definite clause in the original KB is true in this model. To see this, assume the opposite, namely that some clause a~1~ ∧. . .∧ a~k~ ⇒ b is false in the model. Then a~1~ ∧ . . . ∧ a~k~ must be true in the model and b must be false in the model. But this contradicts our assumption that the algorithm has reached a fixed point! We can conclude, therefore, that the set of atomic sentences inferred at the fixed point defines a model of the original KB. Furthermore, any atomic sentence q that is entailed by the KB must be true in all its models and in this model in particular. Hence, every entailed atomic sentence q must be inferred by the algorithm.
Forward chaining is an example of the general concept of data-driven reasoning—that is, reasoning in which the focus of attention starts with the known data. It can be used within an agent to derive conclusions from incoming percepts, often without a specific query in mind. For example, the wumpus agent might TELL its percepts to the knowledge base using
an incremental forward-chaining algorithm in which new facts can be added to the agenda to initiate new inferences. In humans, a certain amount of data-driven reasoning occurs as new information arrives. For example, if I am indoors and hear rain starting to fall, it might occur to me that the picnic will be canceled. Yet it will probably not occur to me that the seventeenth petal on the largest rose in my neighbor’s garden will get wet; humans keep forward chaining under careful control, lest they be swamped with irrelevant consequences.
The backward-chaining algorithm, as its name suggests, works backward from the query. If the query q is known to be true, then no work is needed. Otherwise, the algorithm finds those implications in the knowledge base whose conclusion is q . If all the premises of one of those implications can be proved true (by backward chaining), then q is true. When applied to the query Q in Figure 7.16, it works back down the graph until it reaches a set of known facts, A and B, that forms the basis for a proof. The algorithm is essentially identical to the AND-OR-GRAPH-SEARCH algorithm in Figure 4.11. As with forward chaining, an efficient implementation runs in linear time.
Backward chaining is a form of goal-directed reasoning. It is useful for answering specific questions such as “What shall I do now?” and “Where are my keys?” Often, the cost of backward chaining is much less than linear in the size of the knowledge base, because the process touches only relevant facts.
EFFECTIVE PROPOSITIONAL MODEL CHECKING
In this section, we describe two families of efficient algorithms for general propositional inference based on model checking: One approach based on backtracking search, and one on local hill-climbing search. These algorithms are part of the “technology” of propositional logic. This section can be skimmed on a first reading of the chapter.
The algorithms we describe are for checking satisfiability: the SAT problem. (As noted earlier, testing entailment, α |= β, can be done by testing unsatisfiability of α ∧ ¬β.) We have already noted the connection between finding a satisfying model for a logical sentence and finding a solution for a constraint satisfaction problem, so it is perhaps not surprising that the two families of algorithms closely resemble the backtracking algorithms of Section 6.3 and the local search algorithms of Section 6.4. They are, however, extremely important in their own right because so many combinatorial problems in computer science can be reduced to checking the satisfiability of a propositional sentence. Any improvement in satisfiability algorithms has huge consequences for our ability to handle complexity in general.
A complete backtracking algorithm
The first algorithm we consider is often called the Davis–Putnam algorithm, after the seminal paper by Martin Davis and Hilary Putnam (1960). The algorithm is in fact the version described by Davis, Logemann, and Loveland (1962), so we will call it DPLL after the initials of all four authors. DPLL takes as input a sentence in conjunctive normal form—a set of clauses. Like BACKTRACKING-SEARCH and TT-ENTAILS?, it is essentially a recursive, depth-first enumeration of possible models. It embodies three improvements over the simple scheme of TT-ENTAILS?:
-
Early termination: The algorithm detects whether the sentence must be true or false, even with a partially completed model. A clause is true if any literal is true, even if the other literals do not yet have truth values; hence, the sentence as a whole could be judged true even before the model is complete. For example, the sentence (A ∨ B) ∧ (A ∨ C) is true if A is true, regardless of the values of B and C . Similarly, a sentence is false if any clause is false, which occurs when each of its literals is false. Again, this can occur long before the model is complete. Early termination avoids examination of entire subtrees in the search space.
-
Pure symbol heuristic: A pure symbol is a symbol that always appears with the same “sign” in all clauses. For example, in the three clauses (A ∨ ¬B), (¬B ∨ ¬C), and (C ∨ A), the symbol A is pure because only the positive literal appears, B is pure because only the negative literal appears, and C is impure. It is easy to see that if a sentence has a model, then it has a model with the pure symbols assigned so as to make their literals true , because doing so can never make a clause false. Note that, in determining the purity of a symbol, the algorithm can ignore clauses that are already known to be true in the model constructed so far. For example, if the model contains B = false , then the clause (¬B ∨ ¬C) is already true, and in the remaining clauses C appears only as a positive literal; therefore C becomes pure.
-
Unit clause heuristic: A unit clause was defined earlier as a clause with just one literal. In the context of DPLL, it also means clauses in which all literals but one are already assigned false by the model. For example, if the model contains B = true , then (¬B ∨ ¬C) simplifies to ¬C , which is a unit clause. Obviously, for this clause to be true, C must be set to false . The unit clause heuristic assigns all such symbols before branching on the remainder. One important consequence of the heuristic is that
function DPLL-SATISFIABLE?(s) returns true or false inputs: s , a sentence in propositional logic
clauses← the set of clauses in the CNF representation of s symbols← a list of the proposition symbols in s return DPLL(clauses , symbols ,{ })
function DPLL(clauses , symbols ,model ) returns true or false
if every clause in clauses is true in model then return true if some clause in clauses is false in model then return false P , value← FIND-PURE-SYMBOL(symbols , clauses ,model ) if P is non-null then return DPLL(clauses , symbols – P ,model ∪ {P=value}) P , value← FIND-UNIT-CLAUSE(clauses ,model ) if P is non-null then return DPLL(clauses , symbols – P ,model ∪ {P=value}) P← FIRST(symbols); rest←REST(symbols) return DPLL(clauses , rest ,model ∪ {P=true}) or DPLL(clauses , rest ,model ∪ {P=false})
Figure 7.17 The DPLL algorithm for checking satisfiability of a sentence in propositional logic. The ideas behind FIND-PURE-SYMBOL and FIND-UNIT-CLAUSE are described in the text; each returns a symbol (or null) and the truth value to assign to that symbol. Like TT-ENTAILS?, DPLL operates over partial models.
any attempt to prove (by refutation) a literal that is already in the knowledge base will succeed immediately (Exercise 7.23). Notice also that assigning one unit clause can create another unit clause—for example, when C is set to false , (C ∨ A) becomes a unit clause, causing true to be assigned to A. This “cascade” of forced assignments is called unit propagation. It resembles the process of forward chaining with definite clauses, and indeed, if the CNF expression contains only definite clauses then DPLL essentially replicates forward chaining. (See Exercise 7.24.)
The DPLL algorithm is shown in Figure 7.17, which gives the the essential skeleton of the search process.
What Figure 7.17 does not show are the tricks that enable SAT solvers to scale up to large problems. It is interesting that most of these tricks are in fact rather general, and we have seen them before in other guises:
-
Component analysis (as seen with Tasmania in CSPs): As DPLL assigns truth values to variables, the set of clauses may become separated into disjoint subsets, called components, that share no unassigned variables. Given an efficient way to detect when this occurs, a solver can gain considerable speed by working on each component separately.
-
Variable and value ordering (as seen in Section 6.3.1 for CSPs): Our simple implementation of DPLL uses an arbitrary variable ordering and always tries the value true before false. The degree heuristic (see page 216) suggests choosing the variable that appears most frequently over all remaining clauses.
-
Intelligent backtracking (as seen in Section 6.3 for CSPs): Many problems that cannot be solved in hours of run time with chronological backtracking can be solved in seconds with intelligent backtracking that backs up all the way to the relevant point of conflict. All SAT solvers that do intelligent backtracking use some form of conflict clause learning to record conflicts so that they won’t be repeated later in the search. Usually a limited-size set of conflicts is kept, and rarely used ones are dropped.
-
Random restarts (as seen on page 124 for hill-climbing): Sometimes a run appears not to be making progress. In this case, we can start over from the top of the search tree, rather than trying to continue. After restarting, different random choices (in variable and value selection) are made. Clauses that are learned in the first run are retained after the restart and can help prune the search space. Restarting does not guarantee that a solution will be found faster, but it does reduce the variance on the time to solution.
-
Clever indexing (as seen in many algorithms): The speedup methods used in DPLL itself, as well as the tricks used in modern solvers, require fast indexing of such things as “the set of clauses in which variable Xi appears as a positive literal.” This task is complicated by the fact that the algorithms are interested only in the clauses that have not yet been satisfied by previous assignments to variables, so the indexing structures must be updated dynamically as the computation proceeds.
With these enhancements, modern solvers can handle problems with tens of millions of variables. They have revolutionized areas such as hardware verification and security protocol verification, which previously required laborious, hand-guided proofs.
Local search algorithms
We have seen several local search algorithms so far in this book, including (page 122) and SIMULATED-ANNEALING (page 126). These algorithms can be applied directly to satisfiability problems, provided that we choose the right evaluation function. Because the goal is to find an assignment that satisfies every clause, an evaluation function that counts the number of unsatisfied clauses will do the job. In fact, this is exactly the measure used by the MIN-CONFLICTS algorithm for CSPs (page 221). All these algorithms take steps in the space of complete assignments, flipping the truth value of one symbol at a time. The space usually contains many local minima, to escape from which various forms of randomness are required. In recent years, there has been a great deal of experimentation to find a good balance between greediness and randomness.
One of the simplest and most effective algorithms to emerge from all this work is called WAlkSAT (Figure 7.18). On every iteration, the algorithm picks an unsatisfied clause and picks a symbol in the clause to flip. It chooses randomly between two ways to pick which symbol to flip: (1) a “min-conflicts” step that minimizes the number of unsatisfied clauses in the new state and (2) a “random walk” step that picks the symbol randomly.
When WALKSAT returns a model, the input sentence is indeed satisfiable, but when it returns failure , there are two possible causes: either the sentence is unsatisfiable or we need to give the algorithm more time. If we set max flips = ∞ and p > 0, WALKSAT will eventually return a model (if one exists), because the random-walk steps will eventually hit
function WALKSAT(clauses ,p,max flips) returns a satisfying model or failure inputs: clauses , a set of clauses in propositional logic p, the probability of choosing to do a “random walk” move, typically around 0.5 max flips , number of flips allowed before giving up
model← a random assignment of true/false to the symbols in clauses for i = 1 to max flips do if model satisfies clauses then return model
clause← a randomly selected clause from clauses that is false in model
with probability p flip the value in model of a randomly selected symbol from clause
else flip whichever symbol in clause maximizes the number of satisfied clauses return failure
Figure 7.18 The WALKSAT algorithm for checking satisfiability by randomly flipping the values of variables. Many versions of the algorithm exist.
upon the solution. Alas, if max flips is infinity and the sentence is unsatisfiable, then the algorithm never terminates!
For this reason, WALKSAT is most useful when we expect a solution to exist—for example, the problems discussed in Chapters 3 and 6 usually have solutions. On the other hand, WALKSAT cannot always detect unsatisfiability, which is required for deciding entailment. For example, an agent cannot reliably use WALKSAT to prove that a square is safe in the wumpus world. Instead, it can say, “I thought about it for an hour and couldn’t come up with a possible world in which the square isn’t safe.” This may be a good empirical indicator that the square is safe, but it’s certainly not a proof.
The landscape of random SAT problems
Some SAT problems are harder than others. Easy problems can be solved by any old algorithm, but because we know that SAT is NP-complete, at least some problem instances must require exponential run time. In Chapter 6, we saw some surprising discoveries about certain kinds of problems. For example, the n-queens problem—thought to be quite tricky for backtracking search algorithms—turned out to be trivially easy for local search methods, such as min-conflicts. This is because solutions are very densely distributed in the space of assignments, and any initial assignment is guaranteed to have a solution nearby. Thus, n-queens is easy because it is underconstrained.
When we look at satisfiability problems in conjunctive normal form, an underconstrained problem is one with relatively few clauses constraining the variables. For example, here is a randomly generated 3-CNF sentence with five symbols and five clauses:
(¬D ∨ ¬B ∨ C) ∧ (B ∨ ¬A ∨ ¬C) ∧ (¬C ∨ ¬B ∨ E)
∧ (E ∨ ¬D ∨B) ∧ (B ∨ E ∨ ¬C) .
Sixteen of the 32 possible assignments are models of this sentence, so, on average, it would take just two random guesses to find a model. This is an easy satisfiability problem, as are most such underconstrained problems. On the other hand, an overconstrained problem has many clauses relative to the number of variables and is likely to have no solutions.
To go beyond these basic intuitions, we must define exactly how random sentences are generated. The notation CNFk(m,n) denotes a k-CNF sentence with m clauses and n symbols, where the clauses are chosen uniformly, independently, and without replacement from among all clauses with k different literals, which are positive or negative at random. (A symbol may not appear twice in a clause, nor may a clause appear twice in a sentence.)
Given a source of random sentences, we can measure the probability of satisfiability. Figure 7.19(a) plots the probability for CNF3(m, 50), that is, sentences with 50 variables and 3 literals per clause, as a function of the clause/symbol ratio, m/n. As we expect, for small m/n the probability of satisfiability is close to 1, and at large m/n the probability is close to 0. The probability drops fairly sharply around m/n = 4.3. Empirically, we find that the “cliff” stays in roughly the same place (for k = 3) and gets sharper and sharper as n increases. Theoretically, the satisfiability threshold conjecture says that for every k ≥ 3, there is a threshold ratio rk such that, as n goes to infinity, the probability that CNF~k~(n, rn)n is satisfiable becomes 1 for all values of r below the threshold, and 0 for all values above. The conjecture remains unproven.
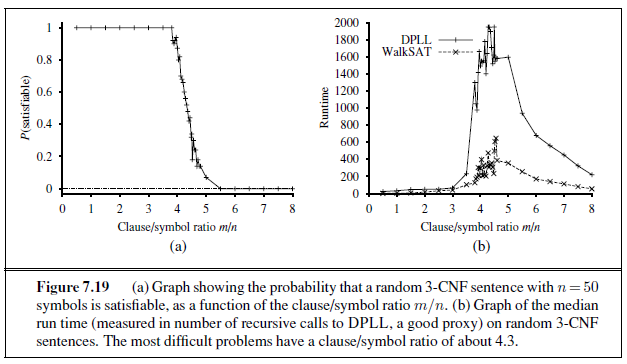
symbols is satisfiable, as a function of the clause/symbol ratio m/n. (b) Graph of the median run time (measured in number of recursive calls to DPLL, a good proxy) on random 3-CNF sentences. The most difficult problems have a clause/symbol ratio of about 4.3.
Now that we have a good idea where the satisfiable and unsatisfiable problems are, the next question is, where are the hard problems? It turns out that they are also often at the threshold value. Figure 7.19(b) shows that 50-symbol problems at the threshold value of 4.3 are about 20 times more difficult to solve than those at a ratio of 3.3. The underconstrained problems are easiest to solve (because it is so easy to guess a solution); the overconstrained problems are not as easy as the underconstrained, but still are much easier than the ones right at the threshold.
AGENTS BASED ON PROPOSITIONAL LOGIC
In this section, we bring together what we have learned so far in order to construct wumpus world agents that use propositional logic. The first step is to enable the agent to deduce, to the extent possible, the state of the world given its percept history. This requires writing down a complete logical model of the effects of actions. We also show how the agent can keep track of the world efficiently without going back into the percept history for each inference. Finally, we show how the agent can use logical inference to construct plans that are guaranteed to achieve its goals.
7.7.1 The current state of the world
As stated at the beginning of the chapter, a logical agent operates by deducing what to do from a knowledge base of sentences about the world. The knowledge base is composed of axioms—general knowledge about how the world works—and percept sentences obtained from the agent’s experience in a particular world. In this section, we focus on the problem of deducing the current state of the wumpus world—where am I, is that square safe, and so on.
We began collecting axioms in Section 7.4.3. The agent knows that the starting square contains no pit (¬P~1,1~) and no wumpus (¬W~1,1~). Furthermore, for each square, it knows that the square is breezy if and only if a neighboring square has a pit; and a square is smelly if and only if a neighboring square has a wumpus. Thus, we include a large collection of sentences of the following form:
B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~)
S~1,1~ ⇔ (W~1,2~ ∨ W~2,1~)
· · ·
The agent also knows that there is exactly one wumpus. This is expressed in two parts. First, we have to say that there is at least one wumpus:
W~1,1~ ∨ W~1,2~ ∨ · · · ∨ W~4,3~ ∨ W~4,4~ .
Then, we have to say that there is at most one wumpus. For each pair of locations, we add a sentence saying that at least one of them must be wumpus-free:
¬W~1,1~ ∨ ¬W~1,2~
¬W~1,1~ ∨ ¬W~1,3~
· · ·
¬W~4,3~ ∨ ¬W~4,4~ .
So far, so good. Now let’s consider the agent’s percepts. If there is currently a stench, one might suppose that a proposition Stench should be added to the knowledge base. This is not quite right, however: if there was no stench at the previous time step, then ¬Stench would already be asserted, and the new assertion would simply result in a contradiction. The problem is solved when we realize that a percept asserts something only about the current time. Thus, if the time step (as supplied to MAKE-PERCEPT-SENTENCE in Figure 7.1) is 4, then we add Stench^4^ to the knowledge base, rather than Stench—neatly avoiding any contradiction with ¬Stench3. The same goes for the breeze, bump, glitter, and scream percepts.
The idea of associating propositions with time steps extends to any aspect of the world that changes over time. For example, the initial knowledge base includes L^0^~1,1~ the agent is in square [1, 1] at time 0—as well as FacingEast^0^, HaveArrow^0^, and WumpusAlive^0^. We use the word fluent (from the Latin fluens, flowing) to refer an aspect of the world that changes. “Fluent” is a synonym for “state variable,” in the sense described in the discussion of factored representations in Section 2.4.7 on page 57. Symbols associated with permanent aspects of the world do not need a time superscript and are sometimes called atemporal variables.
We can connect stench and breeze percepts directly to the properties of the squares where they are experienced through the location fluent as follows.10 For any time step t and any square [x, y], we assert
L^t^~x,y~ ⇒ (Breezet ⇔ B~x,y~)
L^t^~x,y~ ⇒ (Stencht ⇔ S~x,y~) .
Now, of course, we need axioms that allow the agent to keep track of fluents such as L^t^~x,y~. These fluents change as the result of actions taken by the agent, so, in the terminology of Chapter 3, we need to write down the transition model of the wumpus world as a set of logical sentences.
First, we need proposition symbols for the occurrences of actions. As with percepts, these symbols are indexed by time; thus, Forward 0 means that the agent executes the Forward action at time 0. By convention, the percept for a given time step happens first, followed by the action for that time step, followed by a transition to the next time step.
To describe how the world changes, we can try writing effect axioms that specify the outcome of an action at the next time step. For example, if the agent is at location [1, 1] facing east at time 0 and goes Forward , the result is that the agent is in square [2, 1] and no longer is in [1, 1]:
L^0^~1,1~ ∧ FacingEast^0^ ∧ Forward^0^ ⇒ (L^1^~2,1~ ∧ ¬L^1^~1,1~). (7.1)
We would need one such sentence for each possible time step, for each of the 16 squares, and each of the four orientations. We would also need similar sentences for the other actions: Grab, Shoot, Climb, TurnLeft, and TurnRight.
Let us suppose that the agent does decide to move Forward at time 0 and asserts this fact into its knowledge base. Given the effect axiom in Equation (7.1), combined with the initial assertions about the state at time 0, the agent can now deduce that it is in [2, 1]. That is, ASK(KB , L^1^~2,1~)= true . So far, so good. Unfortunately, the news elsewhere is less good: if we ASK(KB ,HaveArrow 1 ), the answer is false , that is, the agent cannot prove it still has the arrow; nor can it prove it doesn’t have it! The information has been lost because the effect axiom fails to state what remains unchanged as the result of an action. The need to do this gives rise to the frame problem.^11^ One possible solution to the frame problem would
10 Section 7.4.3 conveniently glossed over this requirement. 11 The name “frame problem” comes from “frame of reference” in physics—the assumed stationary background with respect to which motion is measured. It also has an analogy to the frames of a movie, in which normally most of the background stays constant while changes occur in the foreground.
be to add frame axioms explicitly asserting all the propositions that remain the same. ForFRAME AXIOM
example, for each time t we would have
Forward^t^ ⇒ (HaveArrow^t^ ⇔ HaveArrow^t+1^)
Forward^t^ ⇒ (WumpusAlive^t^ ⇔ WumpusAlive^t+1^)
· · ·
where we explicitly mention every proposition that stays unchanged from time t to time t + 1 under the action Forward . Although the agent now knows that it still has the arrow after moving forward and that the wumpus hasn’t died or come back to life, the proliferation of frame axioms seems remarkably inefficient. In a world with m different actions and n fluents, the set of frame axioms will be of size O(mn). This specific manifestation of the frame problem is sometimes called the representational frame problem. Historically, the problem was a significant one for AI researchers; we explore it further in the notes at the end of the chapter.
The representational frame problem is significant because the real world has very many fluents, to put it mildly. Fortunately for us humans, each action typically changes no more than some small number k of those fluents—the world exhibits locality. Solving the representational frame problem requires defining the transition model with a set of axioms of size O(mk) rather than size O(mn). There is also an inferential frame problem: the problem of projecting forward the results of a t step plan of action in time O(kt) rather than O(nt). The solution to the problem involves changing one’s focus from writing axioms about actions to writing axioms about fluents. Thus, for each fluent F , we will have an axiom that defines the truth value of F^t+1^ in terms of fluents (including F itself) at time t and the actions that may have occurred at time t. Now, the truth value of F^t+1^ can be set in one of two ways: either the action at time t causes F to be true at t + 1, or F was already true at time t and the action at time t does not cause it to be false. An axiom of this form is called a successor-state axiom and has this schema:
F^t+1^ ⇔ ActionCausesF^t^ ∨ (F^t^ ∧ ¬ActionCausesNotF^t^ ) .
One of the simplest successor-state axioms is the one for HaveArrow . Because there is no action for reloading, the ActionCausesF^t^ part goes away and we are left with
HaveArrow^t+1^ ⇔ (HaveArrow^t^ ∧ ¬Shoot^t^ ) . (7.2)
For the agent’s location, the successor-state axioms are more elaborate. For example, L^t+1^~1,1~ is true if either (a) the agent moved Forward from [1, 2] when facing south, or from [2, 1] when facing west; or (b) L^t^~1,1~ was already true and the action did not cause movement (either because the action was not Forward or because the action bumped into a wall). Written out in propositional logic, this becomes
L^t+1^~1,1~ ⇔ (L^t^~1,1~ ∧ (¬Forward^t^ ∨ Bump^t+1^))
∨ (L^t^~1,2~ ∧ (South^t^ ∧ Forward^t^)) (7.3)
∨ (L^t^~2,1~ ∧ (West^t^ ∧ Forward^t^)) .
Exercise 7.26 asks you to write out axioms for the remaining wumpus world fluents.
Given a complete set of successor-state axioms and the other axioms listed at the beginning of this section, the agent will be able to ASK and answer any answerable question about the current state of the world. For example, in Section 7.2 the initial sequence of percepts and actions is
¬Stench^0^ ∧ ¬Breeze^0^ ∧ ¬Glitter^0^ ∧ ¬Bump^0^ ∧ ¬Scream^0^ ; Forward^0^
¬Stench^1^ ∧ Breeze^1^ ∧ ¬Glitter^1^ ∧ ¬Bump^1^ ∧ ¬Scream^1^ ; TurnRight^1^
¬Stench^2^ ∧ Breeze^2^ ∧ ¬Glitter^2^ ∧ ¬Bump^2^ ∧ ¬Scream^2^ ; TurnRight^2^
¬Stench^3^ ∧ Breeze^3^ ∧ ¬Glitter^3^ ∧ ¬Bump^3^ ∧ ¬Scream^3^ ; Forward^3^
¬Stench^4^ ∧ ¬Breeze^4^ ∧ ¬Glitter^4^ ∧ ¬Bump^4^ ∧ ¬Scream^4^ ; TurnRight^4^
¬Stench^5^ ∧ ¬Breeze^5^ ∧ ¬Glitter^5^ ∧ ¬Bump^5^ ∧ ¬Scream^5^ ; Forward^5^
Stench^6^ ∧ ¬Breeze^6^ ∧ ¬Glitter^6^ ∧ ¬Bump^6^ ∧ ¬Scream^6^
At this point, we have ASK(KB , L^6^~1,2~)= true , so the agent knows where it is. Moreover, ASK(KB ,W~1,3~)= true and ASK(KB , P~3,1~)= true , so the agent has found the wumpus and one of the pits. The most important question for the agent is whether a square is OK to move into, that is, the square contains no pit nor live wumpus. It’s convenient to add axioms for this, having the form
OK^t^~x,y~ ⇔ ¬P~x,y~ ∧ ¬(W~x,y~ ∧ WumpusAlive^t^) .
Finally, ASK(KB ,OK^6^~2,2~)= true, so the square [2, 2] is OK to move into. In fact, given asound and complete inference algorithm such as DPLL, the agent can answer any answerable question about which squares are OK—and can do so in just a few milliseconds for small-tomedium wumpus worlds.
Solving the representational and inferential frame problems is a big step forward, but a pernicious problem remains: we need to confirm that all the necessary preconditions of an action hold for it to have its intended effect. We said that the Forward action moves the agent ahead unless there is a wall in the way, but there are many other unusual exceptions that could cause the action to fail: the agent might trip and fall, be stricken with a heart attack, be carried away by giant bats, etc. Specifying all these exceptions is called the qualification problem.
There is no complete solution within logic; system designers have to use good judgment in deciding how detailed they want to be in specifying their model, and what details they want to leave out. We will see in Chapter 13 that probability theory allows us to summarize all the exceptions without explicitly naming them.
A hybrid agent
The ability to deduce various aspects of the state of the world can be combined fairly straightforwardly with condition–action rules and with problem-solving algorithms from Chapters 3 and 4 to produce a hybrid agent for the wumpus world. Figure 7.20 shows one possible way to do this. The agent program maintains and updates a knowledge base as well as a current plan. The initial knowledge base contains the atemporal axioms—those that don’t depend on t, such as the axiom relating the breeziness of squares to the presence of pits. At each time step, the new percept sentence is added along with all the axioms that depend on t, such as the successor-state axioms. (The next section explains why the agent doesn’t need axioms for future time steps.) Then, the agent uses logical inference, by ASKing questions of the knowledge base, to work out which squares are safe and which have yet to be visited.
The main body of the agent program constructs a plan based on a decreasing priority of goals. First, if there is a glitter, the program constructs a plan to grab the gold, follow a route back to the initial location, and climb out of the cave. Otherwise, if there is no current plan, the program plans a route to the closest safe square that it has not visited yet, making sure the route goes through only safe squares. Route planning is done with A∗ search, not with ASK. If there are no safe squares to explore, the next step—if the agent still has an arrow—is to try to make a safe square by shooting at one of the possible wumpus locations. These are determined by asking where ASK(KB,¬W~x,y~) is false—that is, where it is not known that there is not a wumpus. The function PLAN-SHOT (not shown) uses PLAN-ROUTE to plan a sequence of actions that will line up this shot. If this fails, the program looks for a square to explore that is not provably unsafe—that is, a square for which ASK(KB,¬OK^t^~x,y~) returns false. If there is no such square, then the mission is impossible and the agent retreats to [1, 1] and climbs out of the cave.
Logical state estimation
The agent program in Figure 7.20 works quite well, but it has one major weakness: as time goes by, the computational expense involved in the calls to ASK goes up and up. This happens mainly because the required inferences have to go back further and further in time and involve more and more proposition symbols. Obviously, this is unsustainable—we cannot have an agent whose time to process each percept grows in proportion to the length of its life! What we really need is a constant update time—that is, independent of t. The obvious answer is to save, or cache, the results of inference, so that the inference process at the next time step can build on the results of earlier steps instead of having to start again from scratch.
As we saw in Section 4.4, the past history of percepts and all their ramifications can be replaced by the belief state—that is, some representation of the set of all possible current states of the world.12 The process of updating the belief state as new percepts arrive is called state estimation. Whereas in Section 4.4 the belief state was an explicit list of states, here we can use a logical sentence involving the proposition symbols associated with the current time step, as well as the atemporal symbols. For example, the logical sentence
WumpusAlive^1^ ∧ L^1^~2,1~ ∧ B~2,1~ ∧ (P~3,1~ ∨ P~2,2~) (7.4)
represents the set of all states at time 1 in which the wumpus is alive, the agent is at [2, 1], that square is breezy, and there is a pit in [3, 1] or [2, 2] or both.
Maintaining an exact belief state as a logical formula turns out not to be easy. If there are n fluent symbols for time t, then there are 2^n^ possible states—that is, assignments of truth values to those symbols. Now, the set of belief states is the powerset (set of all subsets) of the set of physical states. There are 2^n^ physical states, hence 22^n^ belief states. Even if we used the most compact possible encoding of logical formulas, with each belief state represented
12 We can think of the percept history itself as a representation of the belief state, but one that makes inference increasingly expensive as the history gets longer.
function HYBRID-WUMPUS-AGENT(percept ) returns an action inputs: percept , a list, [stench,breeze,glitter ,bump,scream] persistent: KB , a knowledge base, initially the atemporal “wumpus physics” t , a counter, initially 0, indicating time plan , an action sequence, initially empty
TELL(KB , MAKE-PERCEPT-SENTENCE(percept , t )) TELL the KB the temporal “physics” sentences for time t safe←{[x , y] : ASK(KB ,OK t x,y) = true}
if ASK(KB ,Glitter t ) = true then plan← [Grab] + PLAN-ROUTE(current ,{[1,1]}, safe) + [Climb] if plan is empty then unvisited←{[x , y] : ASK(KB , L^t′^~x,y~) = false for all t ′ ≤ t} plan← PLAN-ROUTE(current ,unvisited ∩ safe , safe) if plan is empty and ASK(KB ,HaveArrow^t^) = true then possible wumpus←{[x , y] : ASK(KB ,¬W~x,y~) = false} plan← PLAN-SHOT(current ,possible wumpus, safe) if plan is empty then // no choice but to take a risk not unsafe←{[x , y] : ASK(KB ,¬ OK^t^~x,y~) = false} plan← PLAN-ROUTE(current ,unvisited ∩not unsafe, safe) if plan is empty then plan← PLAN-ROUTE(current ,{[1, 1]}, safe) + [Climb] action← POP(plan) TELL(KB , MAKE-ACTION-SENTENCE(action , t )) t← t + 1 return action
function PLAN-ROUTE(current ,goals ,allowed ) returns an action sequence inputs: current , the agent’s current position goals , a set of squares; try to plan a route to one of them allowed , a set of squares that can form part of the route
problem←ROUTE-PROBLEM(current , goals ,allowed ) return A*-GRAPH-SEARCH(problem)
Figure 7.20 A hybrid agent program for the wumpus world. It uses a propositional knowledge base to infer the state of the world, and a combination of problem-solving search and domain-specific code to decide what actions to take.
by a unique binary number, we would need numbers with log~2~(2^2^^n^)= 2^n^ bits to label the current belief state. That is, exact state estimation may require logical formulas whose size is exponential in the number of symbols.
One very common and natural scheme for approximate state estimation is to represent belief states as conjunctions of literals, that is, 1-CNF formulas. To do this, the agent program simply tries to prove X^t^ and ¬X^t^ for each symbol X^t^ (as well as each atemporal symbol whose truth value is not yet known), given the belief state at t − 1. The conjunction of
provable literals becomes the new belief state, and the previous belief state is discarded.
It is important to understand that this scheme may lose some information as time goes along. For example, if the sentence in Equation (7.4) were the true belief state, then neither P~3,1~ nor P~2,2~ would be provable individually and neither would appear in the 1-CNF belief state. (Exercise 7.27 explores one possible solution to this problem.) On the other hand, because every literal in the 1-CNF belief state is proved from the previous belief state, and the initial belief state is a true assertion, we know that entire 1-CNF belief state must be true. Thus, the set of possible states represented by the 1-CNF belief state includes all states that are in fact possible given the full percept history. As illustrated in Figure 7.21, the 1CNF belief state acts as a simple outer envelope, or conservative approximation, around the exact belief state. We see this idea of conservative approximations to complicated sets as a recurring theme in many areas of AI.
Making plans by propositional inference
The agent in Figure 7.20 uses logical inference to determine which squares are safe, but uses A∗ search to make plans. In this section, we show how to make plans by logical inference. The basic idea is very simple:
- Construct a sentence that includes
(a). Init0, a collection of assertions about the initial state; (b). Transition^1^, . . . ,Transition^t^, the successor-state axioms for all possible actions at each time up to some maximum time t; (c). the assertion that the goal is achieved at time t: HaveGold^t^ ∧ ClimbedOut^t^.
-
Present the whole sentence to a SAT solver. If the solver finds a satisfying model, then the goal is achievable; if the sentence is unsatisfiable, then the planning problem is impossible.
-
Assuming a model is found, extract from the model those variables that represent actions and are assigned true . Together they represent a plan to achieve the goals.
A propositional planning procedure, SATP~LAN~, is shown in Figure 7.22. It implements the basic idea just given, with one twist. Because the agent does not know how many steps it will take to reach the goal, the algorithm tries each possible number of steps t, up to some maximum conceivable plan length Tmax. In this way, it is guaranteed to find the shortest plan if one exists. Because of the way SATP~LAN~ searches for a solution, this approach cannot be used in a partially observable environment; SATP~LAN~ would just set the unobservable variables to the values it needs to create a solution.
function SATP~LAN~( init , transition, goal , T max) returns solution or failure * inputs*: init , transition, goal , constitute a description of the problem T max, an upper limit for plan length
for t = 0 to T max do cnf ← TRANSLATE-TO-SAT( init , transition, goal , t ) model← SAT-SOLVER(cnf ) if model is not null then return EXTRACT-SOLUTION(model ) return failure
Figure 7.22 The SATP~LAN~ algorithm. The planning problem is translated into a CNF sentence in which the goal is asserted to hold at a fixed time step t and axioms are included for each time step up to t. If the satisfiability algorithm finds a model, then a plan is extracted by looking at those proposition symbols that refer to actions and are assigned true in the model. If no model exists, then the process is repeated with the goal moved one step later.
The key step in using SATP~LAN~ is the construction of the knowledge base. It might seem, on casual inspection, that the wumpus world axioms in Section 7.7.1 suffice for steps 1(a) and 1(b) above. There is, however, a significant difference between the requirements for entailment (as tested by ASK) and those for satisfiability. Consider, for example, the agent’s location, initially [1, 1], and suppose the agent’s unambitious goal is to be in [2, 1] at time 1. The initial knowledge base contains L^0^~1,1~ and the goal is L^1^~2,1~. Using ASK, we can prove L^1^~2,1~ if Forward^0^ is asserted, and, reassuringly, we cannot prove L^1^~2,1~ if, say, Shoot^0^ is asserted instead. Now, SATP~LAN~ will find the plan [Forward^0^ ]; so far, so good. Unfortunately, SATP~LAN~ also finds the plan [Shoot^0^]. How could this be? To find out, we inspect the model that SATP~LAN~ constructs: it includes the assignment L^0^~2,1~, that is, the agent can be in [2, 1] at time 1 by being there at time^0^ and shooting. One might ask, “Didn’t we say the agent is in [1, 1] at time 0?” Yes, we did, but we didn’t tell the agent that it can’t be in two places at once! For entailment, L^0^~2,1~ is unknown and cannot, therefore, be used in a proof; for satisfiability, on the other hand, L^0^~2,1~ is unknown and can, therefore, be set to whatever value helps to make the goal true. For this reason, SATP~LAN~ is a good debugging tool for knowledge bases because it reveals places where knowledge is missing. In this particular case, we can fix the knowledge base by asserting that, at each time step, the agent is in exactly one location, using a collection of sentences similar to those used to assert the existence of exactly one wumpus. Alternatively, we can assert ¬L^0^~x,y~ for all locations other than [1, 1]; the successor-state axiom for location takes care of subsequent time steps. The same fixes also work to make sure the agent has only one orientation.
SATP~LAN~ has more surprises in store, however. The first is that it finds models with impossible actions, such as shooting with no arrow. To understand why, we need to look more carefully at what the successor-state axioms (such as Equation (7.3)) say about actions whose preconditions are not satisfied. The axioms do predict correctly that nothing will happen when such an action is executed (see Exercise 10.14), but they do not say that the action cannot be executed! To avoid generating plans with illegal actions, we must add precondition axioms stating that an action occurrence requires the preconditions to be satisfied.13 For example, we need to say, for each time t, that
Shoot^t^ ⇒ HaveArrow^t^ .
This ensures that if a plan selects the Shoot action at any time, it must be the case that the agent has an arrow at that time.
SATP~LAN’s~ second surprise is the creation of plans with multiple simultaneous actions. For example, it may come up with a model in which both Forward 0 and Shoot0 are true, which is not allowed. To eliminate this problem, we introduce action exclusion axioms: for every pair of actions A^t^~i~ and A^t^~j~ we add the axiom
¬A^t^~i~ ∨ ¬A^t^~j~ .
It might be pointed out that walking forward and shooting at the same time is not so hard to do, whereas, say, shooting and grabbing at the same time is rather impractical. By imposing action exclusion axioms only on pairs of actions that really do interfere with each other, we can allow for plans that include multiple simultaneous actions—and because SATP~LAN~ finds the shortest legal plan, we can be sure that it will take advantage of this capability.
To summarize, SATP~LAN~ finds models for a sentence containing the initial state, the goal, the successor-state axioms, the precondition axioms, and the action exclusion axioms. It can be shown that this collection of axioms is sufficient, in the sense that there are no longer any spurious “solutions.” Any model satisfying the propositional sentence will be a valid plan for the original problem. Modern SAT-solving technology makes the approach quite practical. For example, a DPLL-style solver has no difficulty in generating the 11-step solution for the wumpus world instance shown in Figure 7.2.
This section has described a declarative approach to agent construction: the agent works by a combination of asserting sentences in the knowledge base and performing logical inference. This approach has some weaknesses hidden in phrases such as “for each time t” and
13 Notice that the addition of precondition axioms means that we need not include preconditions for actions in the successor-state axioms.
“for each square [x, y].” For any practical agent, these phrases have to be implemented by code that generates instances of the general sentence schema automatically for insertion into the knowledge base. For a wumpus world of reasonable size—one comparable to a smallish computer game—we might need a 100× 100 board and 1000 time steps, leading to knowledge bases with tens or hundreds of millions of sentences. Not only does this become rather impractical, but it also illustrates a deeper problem: we know something about the wumpus world—namely, that the “physics” works the same way across all squares and all time steps—that we cannot express directly in the language of propositional logic. To solve this problem, we need a more expressive language, one in which phrases like “for each time t” and “for each square [x, y]” can be written in a natural way. First-order logic, described in Chapter 8, is such a language; in first-order logic a wumpus world of any size and duration can be described in about ten sentences rather than ten million or ten trillion.
SUMMARY
We have introduced knowledge-based agents and have shown how to define a logic with which such agents can reason about the world. The main points are as follows:
-
Intelligent agents need knowledge about the world in order to reach good decisions. Knowledge is contained in agents in the form of sentences in a knowledge representation language that are stored in a knowledge base.
-
A knowledge-based agent is composed of a knowledge base and an inference mechanism. It operates by storing sentences about the world in its knowledge base, using the inference mechanism to infer new sentences, and using these sentences to decide what action to take.
-
A representation language is defined by its syntax, which specifies the structure of sentences, and its semantics, which defines the truth of each sentence in each possible world or model.
-
The relationship of entailment between sentences is crucial to our understanding of reasoning. A sentence α entails another sentence β if β is true in all worlds where α is true. Equivalent definitions include the validity of the sentence α ⇒ β and the unsatisfiability of the sentence α ∧ ¬β.
-
Inference is the process of deriving new sentences from old ones. Sound inference algorithms derive only sentences that are entailed; complete algorithms derive all sentences that are entailed.
-
Propositional logic is a simple language consisting of proposition symbols and logical connectives. It can handle propositions that are known true, known false, or completely unknown.
-
The set of possible models, given a fixed propositional vocabulary, is finite, so en- tailment can be checked by enumerating models. Efficient model-checking inference algorithms for propositional logic include backtracking and local search methods and can often solve large problems quickly.
-
Inference rules are patterns of sound inference that can be used to find proofs. The resolution rule yields a complete inference algorithm for knowledge bases that are expressed in conjunctive normal form. Forward chaining and backward chaining are very natural reasoning algorithms for knowledge bases in Horn form.
-
Local search methods such as WALKSAT can be used to find solutions. Such algorithms are sound but not complete.
-
Logical state estimation involves maintaining a logical sentence that describes the set of possible states consistent with the observation history. Each update step requires inference using the transition model of the environment, which is built from successorstate axioms that specify how each fluent changes.
-
Decisions within a logical agent can be made by SAT solving: finding possible models specifying future action sequences that reach the goal. This approach works only for fully observable or sensorless environments.
-
Propositional logic does not scale to environments of unbounded size because it lacks the expressive power to deal concisely with time, space, and universal patterns of relationships among objects.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
John McCarthy’s paper “Programs with Common Sense” (McCarthy, 1958, 1968) promulgated the notion of agents that use logical reasoning to mediate between percepts and actions. It also raised the flag of declarativism, pointing out that telling an agent what it needs to know is an elegant way to build software. Allen Newell’s (1982) article “The Knowledge Level” makes the case that rational agents can be described and analyzed at an abstract level defined by the knowledge they possess rather than the programs they run. The declarative and procedural approaches to AI are analyzed in depth by Boden (1977). The debate was revived by, among others, Brooks (1991) and Nilsson (1991), and continues to this day (Shaparau et al., 2008). Meanwhile, the declarative approach has spread into other areas of computer science such as networking (Loo et al., 2006).
Logic itself had its origins in ancient Greek philosophy and mathematics. Various logical principles—principles connecting the syntactic structure of sentences with their truth and falsity, with their meaning, or with the validity of arguments in which they figure—are scattered in the works of Plato. The first known systematic study of logic was carried out by Aristotle, whose work was assembled by his students after his death in 322 B.C. as a treatise called the Organon. Aristotle’s syllogisms were what we would now call inference rules. Although the syllogisms included elements of both propositional and first-order logic, the system as a whole lacked the compositional properties required to handle sentences of arbitrary complexity.
The closely related Megarian and Stoic schools (originating in the fifth century B.C. and continuing for several centuries thereafter) began the systematic study of the basic logical connectives. The use of truth tables for defining connectives is due to Philo of Megara. The Stoics took five basic inference rules as valid without proof, including the rule we now call Modus Ponens. They derived a number of other rules from these five, using, among other principles, the deduction theorem (page 249) and were much clearer about the notion of proof than was Aristotle. A good account of the history of Megarian and Stoic logic is given by Benson Mates (1953).
The idea of reducing logical inference to a purely mechanical process applied to a formal language is due to Wilhelm Leibniz (1646–1716), although he had limited success in implementing the ideas. George Boole (1847) introduced the first comprehensive and workable system of formal logic in his book The Mathematical Analysis of Logic. Boole’s logic was closely modeled on the ordinary algebra of real numbers and used substitution of logically equivalent expressions as its primary inference method. Although Boole’s system still fell short of full propositional logic, it was close enough that other mathematicians could quickly fill in the gaps. Schröder (1877) described conjunctive normal form, while Horn form was introduced much later by Alfred Horn (1951). The first comprehensive exposition of modern propositional logic (and first-order logic) is found in Gottlob Frege’s (1879) Begriffschrift (“Concept Writing” or “Conceptual Notation”).
The first mechanical device to carry out logical inferences was constructed by the third Earl of Stanhope (1753–1816). The Stanhope Demonstrator could handle syllogisms and certain inferences in the theory of probability. William Stanley Jevons, one of those who improved upon and extended Boole’s work, constructed his “logical piano” in 1869 to perform inferences in Boolean logic. An entertaining and instructive history of these and other early mechanical devices for reasoning is given by Martin Gardner (1968). The first published computer program for logical inference was the Logic Theorist of Newell, Shaw, and Simon (1957). This program was intended to model human thought processes. Martin Davis (1957) had actually designed a program that came up with a proof in 1954, but the Logic Theorist’s results were published slightly earlier.
Truth tables as a method of testing validity or unsatisfiability in propositional logic were introduced independently by Emil Post (1921) and Ludwig Wittgenstein (1922). In the 1930s, a great deal of progress was made on inference methods for first-order logic. In particular, Gödel (1930) showed that a complete procedure for inference in first-order logic could be obtained via a reduction to propositional logic, using Herbrand’s theorem (Herbrand, 1930). We take up this history again in Chapter 9; the important point here is that the development of efficient propositional algorithms in the 1960s was motivated largely by the interest of mathematicians in an effective theorem prover for first-order logic. The Davis–Putnam algorithm (Davis and Putnam, 1960) was the first effective algorithm for propositional resolution but was in most cases much less efficient than the DPLL backtracking algorithm introduced two years later (1962). The full resolution rule and a proof of its completeness appeared in a seminal paper by J. A. Robinson (1965), which also showed how to do first-order reasoning without resort to propositional techniques.
Stephen Cook (1971) showed that deciding satisfiability of a sentence in propositional logic (the SAT problem) is NP-complete. Since deciding entailment is equivalent to deciding unsatisfiability, it is co-NP-complete. Many subsets of propositional logic are known for which the satisfiability problem is polynomially solvable; Horn clauses are one such subset.
The linear-time forward-chaining algorithm for Horn clauses is due to Dowling and Gallier (1984), who describe their algorithm as a dataflow process similar to the propagation of signals in a circuit.
Early theoretical investigations showed that DPLL has polynomial average-case complexity for certain natural distributions of problems. This potentially exciting fact became less exciting when Franco and Paull (1983) showed that the same problems could be solved in constant time simply by guessing random assignments. The random-generation method described in the chapter produces much harder problems. Motivated by the empirical success of local search on these problems, Koutsoupias and Papadimitriou (1992) showed that a simple hill-climbing algorithm can solve almost all satisfiability problem instances very quickly, suggesting that hard problems are rare. Moreover, Schöning (1999) exhibited a randomized hill-climbing algorithm whose worst-case expected run time on 3-SAT problems (that is, satisfiability of 3-CNF sentences) is O(1.333^n^)—still exponential, but substantially faster than previous worst-case bounds. The current record is O(1.324^n^) (Iwama and Tamaki, 2004). Achlioptas et al. (2004) and Alekhnovich et al. (2005) exhibit families of 3-SAT instances for which all known DPLL-like algorithms require exponential running time.
On the practical side, efficiency gains in propositional solvers have been marked. Given ten minutes of computing time, the original DPLL algorithm in 1962 could only solve problems with no more than 10 or 15 variables. By 1995 the SATZ solver (Li and Anbulagan, 1997) could handle 1,000 variables, thanks to optimized data structures for indexing variables. Two crucial contributions were the watched literal indexing technique of Zhang and Stickel (1996), which makes unit propagation very efficient, and the introduction of clause (i.e., constraint) learning techniques from the CSP community by Bayardo and Schrag (1997). Using these ideas, and spurred by the prospect of solving industrial-scale circuit verification problems, Moskewicz et al. (2001) developed the CHAFF solver, which could handle problems with millions of variables. Beginning in 2002, SAT competitions have been held regularly; most of the winning entries have either been descendants of CHAFF or have used the same general approach. RSAT (Pipatsrisawat and Darwiche, 2007), the 2007 winner, falls in the latter category. Also noteworthy is MINISAT (Een and Sörensson, 2003), an open-source implementation available at http://minisat.se that is designed to be easily modified and improved. The current landscape of solvers is surveyed by Gomes et al. (2008).
Local search algorithms for satisfiability were tried by various authors throughout the 1980s; all of the algorithms were based on the idea of minimizing the number of unsatisfied clauses (Hansen and Jaumard, 1990). A particularly effective algorithm was developed by Gu (1989) and independently by Selman et al. (1992), who called it GSAT and showed that it was capable of solving a wide range of very hard problems very quickly. The WALKSAT algorithm described in the chapter is due to Selman et al. (1996).
The “phase transition” in satisfiability of random k-SAT problems was first observed by Simon and Dubois (1989) and has given rise to a great deal of theoretical and empirical research—due, in part, to the obvious connection to phase transition phenomena in statistical physics. Cheeseman et al. (1991) observed phase transitions in several CSPs and conjecture that all NP-hard problems have a phase transition. Crawford and Auton (1993) located the 3-SAT transition at a clause/variable ratio of around 4.26, noting that this coincides with a sharp peak in the run time of their SAT solver. Cook and Mitchell (1997) provide an excellent summary of the early literature on the problem.
The current state of theoretical understanding is summarized by Achlioptas (2009). The satisfiability threshold conjecture states that, for each k, there is a sharp satisfiability threshold rk, such that as the number of variables n → ∞, instances below the threshold are satisfiable with probability 1, while those above the threshold are unsatisfiable with probability 1. The conjecture was not quite proved by Friedgut (1999): a sharp threshold exists but its location might depend on n even as n → ∞. Despite significant progress in asymptotic analysis of the threshold location for large k (Achlioptas and Peres, 2004; Achlioptas et al., 2007), all that can be proved for k = 3 is that it lies in the range [3.52,4.51]. Current theory suggests that a peak in the run time of a SAT solver is not necessarily related to the satisfiability threshold, but instead to a phase transition in the solution distribution and structure of SAT instances. Empirical results due to Coarfa et al. (2003) support this view. In fact, algorithms such as survey propagation (Parisi and Zecchina, 2002; Maneva et al., 2007) take advantage of special properties of random SAT instances near the satisfiability threshold and greatly outperform general SAT solvers on such instances.
The best sources for information on satisfiability, both theoretical and practical, are the Handbook of Satisfiability (Biere et al., 2009) and the regular International Conferences on Theory and Applications of Satisfiability Testing, known as SAT.
The idea of building agents with propositional logic can be traced back to the seminal paper of McCulloch and Pitts (1943), which initiated the field of neural networks. Contrary to popular supposition, the paper was concerned with the implementation of a Boolean circuit-based agent design in the brain. Circuit-based agents, which perform computation by propagating signals in hardware circuits rather than running algorithms in general-purpose computers, have received little attention in AI, however. The most notable exception is the work of Stan Rosenschein (Rosenschein, 1985; Kaelbling and Rosenschein, 1990), who developed ways to compile circuit-based agents from declarative descriptions of the task environment. (Rosenschein’s approach is described at some length in the second edition of this book.) The work of Rod Brooks (1986, 1989) demonstrates the effectiveness of circuit-based designs for controlling robots—a topic we take up in Chapter 25. Brooks (1991) argues that circuit-based designs are all that is needed for AI—that representation and reasoning are cumbersome, expensive, and unnecessary. In our view, neither approach is sufficient by itself. Williams et al. (2003) show how a hybrid agent design not too different from our wumpus agent has been used to control NASA spacecraft, planning sequences of actions and diagnosing and recovering from faults.
The general problem of keeping track of a partially observable environment was introduced for state-based representations in Chapter 4. Its instantiation for propositional representations was studied by Amir and Russell (2003), who identified several classes of environments that admit efficient state-estimation algorithms and showed that for several other classes the problem is intractable. The temporal-projection problem, which involves determining what propositions hold true after an action sequence is executed, can be seen as a special case of state estimation with empty percepts. Many authors have studied this problem because of its importance in planning; some important hardness results were established by Liberatore (1997). The idea of representing a belief state with propositions can be traced to Wittgenstein (1922).
Logical state estimation, of course, requires a logical representation of the effects of actions—a key problem in AI since the late 1950s. The dominant proposal has been the situation calculus formalism (McCarthy, 1963), which is couched within first-order logic. We discuss situation calculus, and various extensions and alternatives, in Chapters 10 and 12. The approach taken in this chapter—using temporal indices on propositional variables—is more restrictive but has the benefit of simplicity. The general approach embodied in the SATP~LAN~ algorithm was proposed by Kautz and Selman (1992). Later generations of SATP~LAN~ were able to take advantage of the advances in SAT solvers, described earlier, and remain among the most effective ways of solving difficult problems (Kautz, 2006).
The frame problem was first recognized by McCarthy and Hayes (1969). Many researchers considered the problem unsolvable within first-order logic, and it spurred a great deal of research into nonmonotonic logics. Philosophers from Dreyfus (1972) to Crockett (1994) have cited the frame problem as one symptom of the inevitable failure of the entire AI enterprise. The solution of the frame problem with successor-state axioms is due to Ray Reiter (1991). Thielscher (1999) identifies the inferential frame problem as a separate idea and provides a solution. In retrospect, one can see that Rosenschein’s (1985) agents were using circuits that implemented successor-state axioms, but Rosenschein did not notice that the frame problem was thereby largely solved. Foo (2001) explains why the discrete-event control theory models typically used by engineers do not have to explicitly deal with the frame problem: because they are dealing with prediction and control, not with explanation and reasoning about counterfactual situations.
Modern propositional solvers have wide applicability in industrial applications. The application of propositional inference in the synthesis of computer hardware is now a standard technique having many large-scale deployments (Nowick et al., 1993). The SATMC satisfiability checker was used to detect a previously unknown vulnerability in a Web browser user sign-on protocol (Armando et al., 2008).
The wumpus world was invented by Gregory Yob (1975). Ironically, Yob developed it because he was bored with games played on a rectangular grid: the topology of his original wumpus world was a dodecahedron, and we put it back in the boring old grid. Michael Genesereth was the first to suggest that the wumpus world be used as an agent testbed.
EXERCISES
7.1 Suppose the agent has progressed to the point shown in Figure 7.4(a), page 239, having perceived nothing in [1,1], a breeze in [2,1], and a stench in [1,2], and is now concerned with the contents of [1,3], [2,2], and [3,1]. Each of these can contain a pit, and at most one can contain a wumpus. Following the example of Figure 7.5, construct the set of possible worlds. (You should find 32 of them.) Mark the worlds in which the KB is true and those in which each of the following sentences is true:
α2 = “There is no pit in [2,2].” α3 = “There is a wumpus in [1,3].”
Hence show that KB |= α2 and KB |= α3.
7.2 (Adapted from Barwise and Etchemendy (1993).) Given the following, can you prove that the unicorn is mythical? How about magical? Horned?
If the unicorn is mythical, then it is immortal, but if it is not mythical, then it is a mortal mammal. If the unicorn is either immortal or a mammal, then it is horned. The unicorn is magical if it is horned.
7.3 Consider the problem of deciding whether a propositional logic sentence is true in a given model.
a. Write a recursive algorithm PL-TRUE?(s, m) that returns true if and only if the sentence s is true in the model m (where m assigns a truth value for every symbol in s). The algorithm should run in time linear in the size of the sentence. (Alternatively, use a version of this function from the online code repository.)
b. Give three examples of sentences that can be determined to be true or false in a partial model that does not specify a truth value for some of the symbols.
c. Show that the truth value (if any) of a sentence in a partial model cannot be determined efficiently in general.
d. Modify your PL-TRUE? algorithm so that it can sometimes judge truth from partial models, while retaining its recursive structure and linear run time. Give three examples of sentences whose truth in a partial model is not detected by your algorithm.
e. Investigate whether the modified algorithm makes TT-ENTAILS? more efficient.
7.4 Which of the following are correct?
a. False |= True .
b. True |= False .
c. (A ∧ B) |= (A ⇔ B).
d. A ⇔ B |= A ∨ B.
e. A ⇔ B |= ¬A ∨ B.
f. (A ∧ B) ⇒ C |= (A ⇒ C) ∨ (B ⇒ C).
g. (C ∨ (¬A ∧ ¬B)) ≡ ((A ⇒ C) ∧ (B ⇒ C)).
h. (A ∨ B) ∧ (¬C ∨ ¬D ∨ E) |= (A ∨ B).
i. (A ∨ B) ∧ (¬C ∨ ¬D ∨ E) |= (A ∨ B) ∧ (¬D ∨ E).
j. (A ∨ B) ∧ ¬(A ⇒ B) is satisfiable.
k. (A ⇔ B) ∧ (¬A ∨ B) is satisfiable.
l. (A ⇔ B) ⇔ C has the same number of models as (A ⇔ B) for any fixed set of proposition symbols that includes A, B, C .
7.5 Prove each of the following assertions:
a. α is valid if and only if True |= α. b. For any α, False |= α. c. α |= β if and only if the sentence (α ⇒ β) is valid. d. α ≡ β if and only if the sentence (α ⇔ β) is valid. e. α |= β if and only if the sentence (α ∧ ¬β) is unsatisfiable.
7.6 Prove, or find a counterexample to, each of the following assertions:
a. If α |= γ or β |= γ (or both) then (α ∧ β) |= γ b. If α |= (β ∧ γ) then α |= β and α |= γ. c. If α |= (β ∨ γ) then α |= β or α |= γ (or both).
7.7 Consider a vocabulary with only four propositions, A, B, C , and D. How many models are there for the following sentences?
a. B ∨ C . b. ¬A ∨ ¬B ∨ ¬C ∨ ¬D. c. (A ⇒ B) ∧ A ∧ ¬B ∧ C ∧ D.
7.8 We have defined four binary logical connectives.
a. Are there any others that might be useful? b. How many binary connectives can there be? c. Why are some of them not very useful?
7.9 Using a method of your choice, verify each of the equivalences in Figure 7.11 (page 249).
7.10 Decide whether each of the following sentences is valid, unsatisfiable, or neither. Verify your decisions using truth tables or the equivalence rules of Figure 7.11 (page 249).
a. Smoke ⇒ Smoke
b. Smoke ⇒ Fire
c. (Smoke ⇒ Fire) ⇒ (¬Smoke ⇒ ¬Fire)
d. Smoke ∨ Fire ∨ ¬Fire
e. ((Smoke ∧ Heat) ⇒ Fire) ⇔ ((Smoke ⇒ Fire) ∨ (Heat ⇒ Fire))
f. (Smoke ⇒ Fire) ⇒ ((Smoke ∧ Heat) ⇒ Fire)
g. Big ∨ Dumb ∨ (Big ⇒ Dumb)
7.11 Any propositional logic sentence is logically equivalent to the assertion that each possible world in which it would be false is not the case. From this observation, prove that any sentence can be written in CNF.
7.12 Use resolution to prove the sentence ¬A ∧¬B from the clauses in Exercise 7.20.
7.13 This exercise looks into the relationship between clauses and implication sentences.
a. Show that the clause (¬P~1~ ∨ · · · ∨ ¬P~m~ ∨Q) is logically equivalent to the implication sentence (P~1~ ∧ · · · ∧ P~m~) ⇒ Q.
b. Show that every clause (regardless of the number of positive literals) can be written in the form (P~1~ ∧ · · · ∧ P~m~) ⇒ (Q~1~ ∨ · · · ∨ Q~n~), where the P~s~ and Q~s~ are proposition symbols. A knowledge base consisting of such sentences is in implicative normal form or Kowalski form (Kowalski, 1979).
c. Write down the full resolution rule for sentences in implicative normal form.
7.14 According to some political pundits, a person who is radical (R) is electable (E) if he/she is conservative (C), but otherwise is not electable.
a. Which of the following are correct representations of this assertion?
(i) (R ∧ E) ⇐⇒ C
(ii) R ⇒ (E ⇐⇒ C)
(iii) R ⇒ ((C ⇒ E) ∨ ¬E)
b. Which of the sentences in (a) can be expressed in Horn form?
7.15 This question considers representing satisfiability (SAT) problems as CSPs.
a. Draw the constraint graph corresponding to the SAT problem
(¬X~1~ ∨ X~2~) ∧ (¬X~2~ ∨X~~) ∧ . . . ∧ (¬X~n−1~ ∨X~n~)
for the particular case n = 5.
b. How many solutions are there for this general SAT problem as a function of n?
c. Suppose we apply BACKTRACKING-SEARCH (page 215) to find all solutions to a SAT CSP of the type given in (a). (To find all solutions to a CSP, we simply modify the basic algorithm so it continues searching after each solution is found.) Assume that variables are ordered X~1~, . . . ,X~n~ and false is ordered before true . How much time will the algorithm take to terminate? (Write an O(·) expression as a function of n.)
d. We know that SAT problems in Horn form can be solved in linear time by forward chaining (unit propagation). We also know that every tree-structured binary CSP with discrete, finite domains can be solved in time linear in the number of variables (Section 6.5). Are these two facts connected? Discuss.
7.16 Explain why every nonempty propositional clause, by itself, is satisfiable. Prove rigorously that every set of five 3-SAT clauses is satisfiable, provided that each clause mentions exactly three distinct variables. What is the smallest set of such clauses that is unsatisfiable? Construct such a set.
7.17 A propositional 2-CNF expression is a conjunction of clauses, each containing exactly 2 literals, e.g.,
(A ∨ B) ∧ (¬A ∨ C) ∧ (¬B ∨ D) ∧ (¬C ∨ G) ∧ (¬D ∨ G) .
a. Prove using resolution that the above sentence entails G.
b. Two clauses are semantically distinct if they are not logically equivalent. How many semantically distinct 2-CNF clauses can be constructed from n proposition symbols?
c. Using your answer to (b), prove that propositional resolution always terminates in time polynomial in n given a 2-CNF sentence containing no more than n distinct symbols.
d. Explain why your argument in (c) does not apply to 3-CNF.
7.18 Consider the following sentence:
[(Food ⇒ Party) ∨ (Drinks ⇒ Party)] ⇒ [(Food ∧ Drinks) ⇒ Party ] .
a. Determine, using enumeration, whether this sentence is valid, satisfiable (but not valid), or unsatisfiable.
b. Convert the left-hand and right-hand sides of the main implication into CNF, showing each step, and explain how the results confirm your answer to (a).
c. Prove your answer to (a) using resolution.
7.19 A sentence is in disjunctive normal form (DNF) if it is the disjunction of conjunctions of literals. For example, the sentence (A ∧ B ∧ ¬C) ∨ (¬A ∧ C) ∨ (B ∧ ¬C) is in DNF.
a. Any propositional logic sentence is logically equivalent to the assertion that some possible world in which it would be true is in fact the case. From this observation, prove that any sentence can be written in DNF.
b. Construct an algorithm that converts any sentence in propositional logic into DNF. (Hint: The algorithm is similar to the algorithm for conversion to CNF given in Section 7.5.2.)
c. Construct a simple algorithm that takes as input a sentence in DNF and returns a satisfying assignment if one exists, or reports that no satisfying assignment exists.
d. Apply the algorithms in (b) and (c) to the following set of sentences:
A ⇒ B
B ⇒ C
C ⇒ ¬A .
e. Since the algorithm in (b) is very similar to the algorithm for conversion to CNF, and since the algorithm in (c) is much simpler than any algorithm for solving a set of sentences in CNF, why is this technique not used in automated reasoning?
7.20 Convert the following set of sentences to clausal form.
s~1~: A ⇔ (B ∨ E).
s~2~: E ⇒ D.
S3: C ∧ F ⇒ ¬B.
S4: E ⇒ B.
S5: B ⇒ F .
S6: B ⇒ C
Give a trace of the execution of DPLL on the conjunction of these clauses.
7.21 Is a randomly generated 4-CNF sentence with n symbols and m clauses more or less likely to be solvable than a randomly generated 3-CNF sentence with n symbols and m clauses? Explain.
7.22 Minesweeper, the well-known computer game, is closely related to the wumpus world. A minesweeper world is a rectangular grid of N squares with M invisible mines scattered among them. Any square may be probed by the agent; instant death follows if a mine is probed. Minesweeper indicates the presence of mines by revealing, in each probed square, the number of mines that are directly or diagonally adjacent. The goal is to probe every unmined square.
a. Let X~i,j~ be true iff square [i, j] contains a mine. Write down the assertion that exactly two mines are adjacent to [1,1] as a sentence involving some logical combination of X~i,j~ propositions.
b. Generalize your assertion from (a) by explaining how to construct a CNF sentence asserting that k of n neighbors contain mines.
c. Explain precisely how an agent can use DPLL to prove that a given square does (or does not) contain a mine, ignoring the global constraint that there are exactly M mines in all.
d. Suppose that the global constraint is constructed from your method from part (b). How does the number of clauses depend on M and N? Suggest a way to modify DPLL so that the global constraint does not need to be represented explicitly.
e. Are any conclusions derived by the method in part (c) invalidated when the global constraint is taken into account?
f. Give examples of configurations of probe values that induce long-range dependencies such that the contents of a given unprobed square would give information about the contents of a far-distant square. (Hint: consider an N × 1 board.)
7.23 How long does it take to prove KB |= α using DPLL when α is a literal already contained in KB? Explain.
7.24 Trace the behavior of DPLL on the knowledge base in Figure 7.16 when trying to prove Q, and compare this behavior with that of the forward-chaining algorithm.
7.25 Write a successor-state axiom for the Locked predicate, which applies to doors, assuming the only actions available are Lock and Unlock .
7.26 Section 7.7.1 provides some of the successor-state axioms required for the wumpus world. Write down axioms for all remaining fluent symbols.
7.27 Modify the HYBRID-WUMPUS-AGENT to use the 1-CNF logical state estimation method described on page 271. We noted on that page that such an agent will not be able to acquire, maintain, and use more complex beliefs such as the disjunction P~3,1~ ∨ P~2,2~. Suggest a method for overcoming this problem by defining additional proposition symbols, and try it out in the wumpus world. Does it improve the performance of the agent?
FIRST-ORDER LOGIC
In which we notice that the world is blessed with many objects, some of which are related to other objects, and in which we endeavor to reason about them.
In Chapter 7, we showed how a knowledge-based agent could represent the world in which it operates and deduce what actions to take. We used propositional logic as our representation language because it sufficed to illustrate the basic concepts of logic and knowledge-based agents. Unfortunately, propositional logic is too puny a language to represent knowledge of complex environments in a concise way. In this chapter, we examine first-order logic,^1^ which is sufficiently expressive to represent a good deal of our commonsense knowledge. It also either subsumes or forms the foundation of many other representation languages and has been studied intensively for many decades. We begin in Section 8.1 with a discussion of representation languages in general; Section 8.2 covers the syntax and semantics of first-order logic; Sections 8.3 and 8.4 illustrate the use of first-order logic for simple representations.
REPRESENTATION REVISITED
In this section, we discuss the nature of representation languages. Our discussion motivates the development of first-order logic, a much more expressive language than the propositional logic introduced in Chapter 7. We look at propositional logic and at other kinds of languages to understand what works and what fails. Our discussion will be cursory, compressing centuries of thought, trial, and error into a few paragraphs.
Programming languages (such as C++ or Java or Lisp) are by far the largest class of formal languages in common use. Programs themselves represent, in a direct sense, only computational processes. Data structures within programs can represent facts; for example, a program could use a 4 × 4 array to represent the contents of the wumpus world. Thus, the programming language statement World [2,2]←Pit is a fairly natural way to assert that there is a pit in square [2,2]. (Such representations might be considered ad hoc; database systems were developed precisely to provide a more general, domain-independent way to store and
1 Also called first-order predicate calculus, sometimes abbreviated as FOL or FOPC.
retrieve facts.) What programming languages lack is any general mechanism for deriving facts from other facts; each update to a data structure is done by a domain-specific procedure whose details are derived by the programmer from his or her own knowledge of the domain. This procedural approach can be contrasted with the declarative nature of propositional logic, in which knowledge and inference are separate, and inference is entirely domain independent.
A second drawback of data structures in programs (and of databases, for that matter) is the lack of any easy way to say, for example, “There is a pit in [2,2] or [3,1]” or “If the wumpus is in [1,1] then he is not in [2,2].” Programs can store a single value for each variable, and some systems allow the value to be “unknown,” but they lack the expressiveness required to handle partial information.
Propositional logic is a declarative language because its semantics is based on a truth relation between sentences and possible worlds. It also has sufficient expressive power to deal with partial information, using disjunction and negation. Propositional logic has a third property that is desirable in representation languages, namely, compositionality. In a compositional language, the meaning of a sentence is a function of the meaning of its parts. For example, the meaning of “S~1,4~ ∧ S~1,2~” is related to the meanings of “S~1,4~” and “S~1,2~.” It would be very strange if “S~1,4~” meant that there is a stench in square [1,4] and “S~1,2~” meant that there is a stench in square [1,2], but “S~1,4~∧S~1,2~” meant that France and Poland drew 1–1 in last week’s ice hockey qualifying match. Clearly, noncompositionality makes life much more difficult for the reasoning system.
As we saw in Chapter 7, however, propositional logic lacks the expressive power to concisely describe an environment with many objects. For example, we were forced to write a separate rule about breezes and pits for each square, such as
B~1,1~ ⇔ (P~1,2~ ∨ P~2,1~) .
In English, on the other hand, it seems easy enough to say, once and for all, “Squares adjacent to pits are breezy.” The syntax and semantics of English somehow make it possible to describe the environment concisely.
The language of thought
Natural languages (such as English or Spanish) are very expressive indeed. We managed to write almost this whole book in natural language, with only occasional lapses into other languages (including logic, mathematics, and the language of diagrams). There is a long tradition in linguistics and the philosophy of language that views natural language as a declarative knowledge representation language. If we could uncover the rules for natural language, we could use it in representation and reasoning systems and gain the benefit of the billions of pages that have been written in natural language.
The modern view of natural language is that it serves a as a medium for communication rather than pure representation. When a speaker points and says, “Look!” the listener comes to know that, say, Superman has finally appeared over the rooftops. Yet we would not want to say that the sentence “Look!” represents that fact. Rather, the meaning of the sentence depends both on the sentence itself and on the context in which the sentence was spoken. Clearly, one could not store a sentence such as “Look!” in a knowledge base and expect to recover its meaning without also storing a representation of the context—which raises the question of how the context itself can be represented. Natural languages also suffer from ambiguity, a problem for a representation language. As Pinker (1995) puts it: “When people think about spring, surely they are not confused as to whether they are thinking about a season or something that goes boing—and if one word can correspond to two thoughts, thoughts can’t be words.”
The famous Sapir–Whorf hypothesis claims that our understanding of the world is strongly influenced by the language we speak. Whorf (1956) wrote “We cut nature up, organize it into concepts, and ascribe significances as we do, largely because we are parties to an agreement to organize it this way—an agreement that holds throughout our speech community and is codified in the patterns of our language.” It is certainly true that different speech communities divide up the world differently. The French have two words “chaise” and “fauteuil,” for a concept that English speakers cover with one: “chair.” But English speakers can easily recognize the category fauteuil and give it a name—roughly “open-arm chair”—so does language really make a difference? Whorf relied mainly on intuition and speculation, but in the intervening years we actually have real data from anthropological, psychological and neurological studies.
For example, can you remember which of the following two phrases formed the opening of Section 8.1?
“In this section, we discuss the nature of representation languages . . .”
“This section covers the topic of knowledge representation languages . . .”
Wanner (1974) did a similar experiment and found that subjects made the right choice at chance level—about 50% of the time—but remembered the content of what they read with better than 90% accuracy. This suggests that people process the words to form some kind of nonverbal representation.
More interesting is the case in which a concept is completely absent in a language. Speakers of the Australian aboriginal language Guugu Yimithirr have no words for relative directions, such as front, back, right, or left. Instead they use absolute directions, saying, for example, the equivalent of “I have a pain in my north arm.” This difference in language makes a difference in behavior: Guugu Yimithirr speakers are better at navigating in open terrain, while English speakers are better at placing the fork to the right of the plate.
Language also seems to influence thought through seemingly arbitrary grammatical features such as the gender of nouns. For example, “bridge” is masculine in Spanish and feminine in German. Boroditsky (2003) asked subjects to choose English adjectives to describe a photograph of a particular bridge. Spanish speakers chose big, dangerous, strong, and towering, whereas German speakers chose beautiful, elegant, fragile, and slender. Words can serve as anchor points that affect how we perceive the world. Loftus and Palmer (1974) showed experimental subjects a movie of an auto accident. Subjects who were asked “How fast were the cars going when they contacted each other?” reported an average of 32 mph, while subjects who were asked the question with the word “smashed” instead of “contacted” reported 41mph for the same cars in the same movie.
In a first-order logic reasoning system that uses CNF, we can see that the linguistic form “¬(A ∨ B)” and “¬A ∧ ¬B” are the same because we can look inside the system and see that the two sentences are stored as the same canonical CNF form. Can we do that with the human brain? Until recently the answer was “no,” but now it is “maybe.” Mitchell et al. (2008) put subjects in an fMRI (functional magnetic resonance imaging) machine, showed them words such as “celery,” and imaged their brains. The researchers were then able to train a computer program to predict, from a brain image, what word the subject had been presented with. Given two choices (e.g., “celery” or “airplane”), the system predicts correctly 77% of the time. The system can even predict at above-chance levels for words it has never seen an fMRI image of before (by considering the images of related words) and for people it has never seen before (proving that fMRI reveals some level of common representation across people). This type of work is still in its infancy, but fMRI (and other imaging technology such as intracranial electrophysiology (Sahin et al., 2009)) promises to give us much more concrete ideas of what human knowledge representations are like.
From the viewpoint of formal logic, representing the same knowledge in two different ways makes absolutely no difference; the same facts will be derivable from either representation. In practice, however, one representation might require fewer steps to derive a conclusion, meaning that a reasoner with limited resources could get to the conclusion using one representation but not the other. For nondeductive tasks such as learning from experience, outcomes are necessarily dependent on the form of the representations used. We show in Chapter 18 that when a learning program considers two possible theories of the world, both of which are consistent with all the data, the most common way of breaking the tie is to choose the most succinct theory—and that depends on the language used to represent theories. Thus, the influence of language on thought is unavoidable for any agent that does learning.
Combining the best of formal and natural languages
We can adopt the foundation of propositional logic—a declarative, compositional semantics that is context-independent and unambiguous—and build a more expressive logic on that foundation, borrowing representational ideas from natural language while avoiding its drawbacks. When we look at the syntax of natural language, the most obvious elements are nouns and noun phrases that refer to objects (squares, pits, wumpuses) and verbs and verb phrases that refer to relations among objects (is breezy, is adjacent to, shoots). Some of these relations are functions—relations in which there is only one “value” for a given “input.” It is easy to start listing examples of objects, relations, and functions:
-
Objects: people, houses, numbers, theories, Ronald McDonald, colors, baseball games, wars, centuries . . .
-
Relations: these can be unary relations or properties such as red, round, bogus, prime, multistoried . . ., or more general n-ary relations such as brother of, bigger than, inside, part of, has color, occurred after, owns, comes between, . . .
-
Functions: father of, best friend, third inning of, one more than, beginning of . . .
Indeed, almost any assertion can be thought of as referring to objects and properties or relations. Some examples follow:
-
“One plus two equals three.” Objects: one, two, three, one plus two; Relation: equals; Function: plus. (“One plus two” is a name for the object that is obtained by applying the function “plus” to the objects “one” and “two.” “Three” is another name for this object.)
-
“Squares neighboring the wumpus are smelly.” Objects: wumpus, squares; Property: smelly; Relation: neighboring.
-
“Evil King John ruled England in 1200.” Objects: John, England, 1200; Relation: ruled; Properties: evil, king.
The language of first-order logic, whose syntax and semantics we define in the next section, is built around objects and relations. It has been so important to mathematics, philosophy, and artificial intelligence precisely because those fields—and indeed, much of everyday human existence—can be usefully thought of as dealing with objects and the relations among them. First-order logic can also express facts about some or all of the objects in the universe. This enables one to represent general laws or rules, such as the statement “Squares neighboring the wumpus are smelly.”
The primary difference between propositional and first-order logic lies in the ontological commitment made by each language—that is, what it assumes about the nature of reality. Mathematically, this commitment is expressed through the nature of the formal models with respect to which the truth of sentences is defined. For example, propositional logic assumes that there are facts that either hold or do not hold in the world. Each fact can be in one of two states: true or false, and each model assigns true or false to each proposition symbol (see Section 7.4.2).2 First-order logic assumes more; namely, that the world consists of objects with certain relations among them that do or do not hold. The formal models are correspondingly more complicated than those for propositional logic. Special-purpose logics make still further ontological commitments; for example, temporal logic assumes that facts hold at particular times and that those times (which may be points or intervals) are ordered. Thus, special-purpose logics give certain kinds of objects (and the axioms about them) “first class” status within the logic, rather than simply defining them within the knowledge base. Higher-order logic views the relations and functions referred to by first-order logic as objects in themselves. This allows one to make assertions about all relations—for example, one could wish to define what it means for a relation to be transitive. Unlike most special-purpose logics, higher-order logic is strictly more expressive than first-order logic, in the sense that some sentences of higher-order logic cannot be expressed by any finite number of first-order logic sentences.
A logic can also be characterized by its epistemological commitments—the possible states of knowledge that it allows with respect to each fact. In both propositional and firstorder logic, a sentence represents a fact and the agent either believes the sentence to be true, believes it to be false, or has no opinion. These logics therefore have three possible states of knowledge regarding any sentence. Systems using probability theory, on the other hand,
2 In contrast, facts in fuzzy logic have a degree of truth between 0 and 1. For example, the sentence “Vienna is a large city” might be true in our world only to degree 0.6 in fuzzy logic.
can have any degree of belief, ranging from 0 (total disbelief) to 1 (total belief).^3^ For example, a probabilistic wumpus-world agent might believe that the wumpus is in [1,3] with probability 0.75. The ontological and epistemological commitments of five different logics are summarized in Figure 8.1.
| Language | Ontological Commitment (What exists in the world) | Epistemological Commitment (What an agent believes about facts) |
|---|---|---|
| Propositional logic | facts | true/false/unknown |
| First-order logic | facts, objects, relations | true/false/unknown |
| Temporal logic | facts, objects, relations, times | true/false/unknown |
| Probability theory | facts | degree of belief ∈ [0, 1] |
| Fuzzy logic | facts with degree of truth ∈ [0, 1] | known interval value |
Figure 8.1 Formal languages and their ontological and epistemological commitments.
In the next section, we will launch into the details of first-order logic. Just as a student of physics requires some familiarity with mathematics, a student of AI must develop a talent for working with logical notation. On the other hand, it is also important not to get too concerned with the specifics of logical notation—after all, there are dozens of different versions. The main things to keep hold of are how the language facilitates concise representations and how its semantics leads to sound reasoning procedures.
SYNTAX AND SEMANTICS OF FIRST-ORDER LOGIC
We begin this section by specifying more precisely the way in which the possible worlds of first-order logic reflect the ontological commitment to objects and relations. Then we introduce the various elements of the language, explaining their semantics as we go along.
Models for first-order logic
Recall from Chapter 7 that the models of a logical language are the formal structures that constitute the possible worlds under consideration. Each model links the vocabulary of the logical sentences to elements of the possible world, so that the truth of any sentence can be determined. Thus, models for propositional logic link proposition symbols to predefined truth values. Models for first-order logic are much more interesting. First, they have objects in them! The domain of a model is the set of objects or domain elements it contains. The domain is required to be nonempty—every possible world must contain at least one object. (See Exercise 8.7 for a discussion of empty worlds.) Mathematically speaking, it doesn’t matter what these objects are—all that matters is how many there are in each particular model—but for pedagogical purposes we’ll use a concrete example. Figure 8.2 shows a model with five
3 It is important not to confuse the degree of belief in probability theory with the degree of truth in fuzzy logic. Indeed, some fuzzy systems allow uncertainty (degree of belief) about degrees of truth.
objects: Richard the Lionheart, King of England from 1189 to 1199; his younger brother, the evil King John, who ruled from 1199 to 1215; the left legs of Richard and John; and a crown.
The objects in the model may be related in various ways. In the figure, Richard and John are brothers. Formally speaking, a relation is just the set of tuples of objects that areTUPLE
related. (A tuple is a collection of objects arranged in a fixed order and is written with angle brackets surrounding the objects.) Thus, the brotherhood relation in this model is the set
{ 〈Richard the Lionheart, King John〉, 〈King John, Richard the Lionheart〉 } . (8.1)
(Here we have named the objects in English, but you may, if you wish, mentally substitute the pictures for the names.) The crown is on King John’s head, so the “on head” relation contains just one tuple, 〈the crown, King John〉. The “brother” and “on head” relations are binary relations—that is, they relate pairs of objects. The model also contains unary relations, or properties: the “person” property is true of both Richard and John; the “king” property is true only of John (presumably because Richard is dead at this point); and the “crown” property is true only of the crown.
Certain kinds of relationships are best considered as functions, in that a given object must be related to exactly one object in this way. For example, each person has one left leg, so the model has a unary “left leg” function that includes the following mappings:
〈Richard the Lionheart〉 → Richard’s left leg 〈King John〉 → John’s left leg . (8.2)
Strictly speaking, models in first-order logic require total functions, that is, there must be a value for every input tuple. Thus, the crown must have a left leg and so must each of the left legs. There is a technical solution to this awkward problem involving an additional “invisible”
object that is the left leg of everything that has no left leg, including itself. Fortunately, as long as one makes no assertions about the left legs of things that have no left legs, these technicalities are of no import.
So far, we have described the elements that populate models for first-order logic. The other essential part of a model is the link between those elements and the vocabulary of the logical sentences, which we explain next.
Symbols and interpretations
We turn now to the syntax of first-order logic. The impatient reader can obtain a complete description from the formal grammar in Figure 8.3.
The basic syntactic elements of first-order logic are the symbols that stand for objects, relations, and functions. The symbols, therefore, come in three kinds: constant symbols, which stand for objects; predicate symbols, which stand for relations; and function symbols, which stand for functions. We adopt the convention that these symbols will begin with uppercase letters. For example, we might use the constant symbols Richard and John ; the predicate symbols Brother , OnHead , Person , King , and Crown ; and the function symbol LeftLeg . As with proposition symbols, the choice of names is entirely up to the user. Each predicate and function symbol comes with an arity that fixes the number of arguments.
As in propositional logic, every model must provide the information required to determine if any given sentence is true or false. Thus, in addition to its objects, relations, and functions, each model includes an interpretation that specifies exactly which objects, relations and functions are referred to by the constant, predicate, and function symbols. One possible interpretation for our example—which a logician would call the intended interpretation—is as follows:
-
Richard refers to Richard the Lionheart and John refers to the evil King John.
-
Brother refers to the brotherhood relation, that is, the set of tuples of objects given in Equation (8.1); OnHead refers to the “on head” relation that holds between the crown and King John; Person , King , and Crown refer to the sets of objects that are persons, kings, and crowns.
-
LeftLeg refers to the “left leg” function, that is, the mapping given in Equation (8.2).
There are many other possible interpretations, of course. For example, one interpretation maps Richard to the crown and John to King John’s left leg. There are five objects in the model, so there are 25 possible interpretations just for the constant symbols Richard and John . Notice that not all the objects need have a name—for example, the intended interpretation does not name the crown or the legs. It is also possible for an object to have several names; there is an interpretation under which both Richard and John refer to the crown.4 If you find this possibility confusing, remember that, in propositional logic, it is perfectly possible to have a model in which Cloudy and Sunny are both true; it is the job of the knowledge base to rule out models that are inconsistent with our knowledge.
4 Later, in Section 8.2.8, we examine a semantics in which every object has exactly one name.
Sentence → AtomicSentence | ComplexSentence
AtomicSentence → Predicate | Predicate(Term , . . .) | Term = Term ComplexSentence → ( Sentence ) | [ Sentence ]
| ¬ Sentence
| Sentence ∧ Sentence
| Sentence ∨ Sentence
| Sentence ⇒ Sentence
| Sentence ⇔ Sentence
| Quantifier Variable , . . . Sentence
Term → Function(Term, . . .)
| Constant
| Variable
Quantifier → ∀ | ∃
Constant → A | X~1~ | John | · · ·
Variable → a | x | s | · · ·
Predicate → True | False | After | Loves | Raining | · · ·
Function → Mother | LeftLeg | · · ·
OPERATOR PRECEDENCE : ¬, =,∧,∨,⇒,⇔
Figure 8.3 The syntax of first-order logic with equality, specified in Backus–Naur form (see page 1060 if you are not familiar with this notation). Operator precedences are specified, from highest to lowest. The precedence of quantifiers is such that a quantifier holds over everything to the right of it.
In summary, a model in first-order logic consists of a set of objects and an interpretation that maps constant symbols to objects, predicate symbols to relations on those objects, and function symbols to functions on those objects. Just as with propositional logic, entailment, validity, and so on are defined in terms of all possible models. To get an idea of what the set of all possible models looks like, see Figure 8.4. It shows that models vary in how many objects they contain—from one up to infinity—and in the way the constant symbols map to objects. If there are two constant symbols and one object, then both symbols must refer to the same object; but this can still happen even with more objects. When there are more objects than constant symbols, some of the objects will have no names. Because the number of possible models is unbounded, checking entailment by the enumeration of all possible models is not feasible for first-order logic (unlike propositional logic). Even if the number of objects is restricted, the number of combinations can be very large. (See Exercise 8.5.) For the example in Figure 8.4, there are 137,506,194,466 models with six or fewer objects.
Terms
A term is a logical expression that refers to an object. Constant symbols are therefore terms, but it is not always convenient to have a distinct symbol to name every object. For example, in English we might use the expression “King John’s left leg” rather than giving a name to his leg. This is what function symbols are for: instead of using a constant symbol, we use LeftLeg(John). In the general case, a complex term is formed by a function symbol followed by a parenthesized list of terms as arguments to the function symbol. It is important to remember that a complex term is just a complicated kind of name. It is not a “subroutine call” that “returns a value.” There is no LeftLeg subroutine that takes a person as input and returns a leg. We can reason about left legs (e.g., stating the general rule that everyone has one and then deducing that John must have one) without ever providing a definition of LeftLeg . This is something that cannot be done with subroutines in programming languages.^5^
The formal semantics of terms is straightforward. Consider a term f(t~1~, . . . , t~n~). The function symbol f refers to some function in the model (call it F ); the argument terms refer to objects in the domain (call them d~1~, . . . , d~n~); and the term as a whole refers to the object that is the value of the function F applied to d~1~, . . . , d~n~. For example, suppose the Left Leg function symbol refers to the function shown in Equation (8.2) and John refers to King John, then LeftLeg(John) refers to King John’s left leg. In this way, the interpretation fixes the referent of every term.
Atomic sentences
Now that we have both terms for referring to objects and predicate symbols for referring to relations, we can put them together to make atomic sentences that state facts. An atomic
5 λ**-expressions** provide a useful notation in which new function symbols are constructed “on the fly.” For example, the function that squares its argument can be written as (λx x×x) and can be applied to arguments just like any other function symbol. A λ-expression can also be defined and used as a predicate symbol. (See Chapter 22.) The lambda operator in Lisp plays exactly the same role. Notice that the use of λ in this way does not increase the formal expressive power of first-order logic, because any sentence that includes a λ-expression can be rewritten by “plugging in” its arguments to yield an equivalent sentence.
sentence (or atom for short) is formed from a predicate symbol optionally followed by a parenthesized list of terms, such as
Brother (Richard , John).
This states, under the intended interpretation given earlier, that Richard the Lionheart is the brother of King John.6 Atomic sentences can have complex terms as arguments. Thus,
Married(Father (Richard),Mother (John))
states that Richard the Lionheart’s father is married to King John’s mother (again, under a suitable interpretation).
An atomic sentence is true in a given model if the relation referred to by the predicate symbol holds among the objects referred to by the arguments.
Complex sentences
We can use logical connectives to construct more complex sentences, with the same syntax and semantics as in propositional calculus. Here are four sentences that are true in the model of Figure 8.2 under our intended interpretation:
¬Brother (LeftLeg(Richard), John)
Brother (Richard , John) ∧ Brother (John ,Richard)
King(Richard ) ∨ King(John)
¬King(Richard) ⇒ King(John) .
Quantifiers
Once we have a logic that allows objects, it is only natural to want to express properties of entire collections of objects, instead of enumerating the objects by name. Quantifiers let us do this. First-order logic contains two standard quantifiers, called universal and existential.
Universal quantification (∀)
Recall the difficulty we had in Chapter 7 with the expression of general rules in propositional logic. Rules such as “Squares neighboring the wumpus are smelly” and “All kings are persons” are the bread and butter of first-order logic. We deal with the first of these in Section 8.3. The second rule, “All kings are persons,” is written in first-order logic as
∀x King(x) ⇒ Person(x) .
∀ is usually pronounced “For all . . .”. (Remember that the upside-down A stands for “all.”) Thus, the sentence says, “For all x, if x is a king, then x is a person.” The symbol x is called a variable. By convention, variables are lowercase letters. A variable is a term all by itself, and as such can also serve as the argument of a function—for example, LeftLeg(x). A term with no variables is called a ground term.
Intuitively, the sentence ∀x P , where P is any logical expression, says that P is true for every object x. More precisely, ∀x P is true in a given model if P is true in all possible extended interpretations constructed from the interpretation given in the model, where each
6 We usually follow the argument-ordering convention that P (x, y) is read as “x is a P of y.”
extended interpretation specifies a domain element to which x refers. This sounds complicated, but it is really just a careful way of stating the intuitive meaning of universal quantification. Consider the model shown in Figure 8.2 and the intended interpretation that goes with it. We can extend the interpretation in five ways:
x→ Richard the Lionheart, x→ King John, x→ Richard’s left leg, x→ John’s left leg, x→ the crown.
The universally quantified sentence ∀x King(x) ⇒ Person(x) is true in the original model if the sentence King(x) ⇒ Person(x) is true under each of the five extended interpretations. That is, the universally quantified sentence is equivalent to asserting the following five sentences:
Richard the Lionheart is a king ⇒ Richard the Lionheart is a person. King John is a king ⇒ King John is a person. Richard’s left leg is a king ⇒ Richard’s left leg is a person. John’s left leg is a king ⇒ John’s left leg is a person. The crown is a king ⇒ the crown is a person.
Let us look carefully at this set of assertions. Since, in our model, King John is the only king, the second sentence asserts that he is a person, as we would hope. But what about the other four sentences, which appear to make claims about legs and crowns? Is that part of the meaning of “All kings are persons”? In fact, the other four assertions are true in the model, but make no claim whatsoever about the personhood qualifications of legs, crowns, or indeed Richard. This is because none of these objects is a king. Looking at the truth table for ⇒ (Figure 7.8 on page 246), we see that the implication is true whenever its premise is false—regardless of the truth of the conclusion. Thus, by asserting the universally quantified sentence, which is equivalent to asserting a whole list of individual implications, we end up asserting the conclusion of the rule just for those objects for whom the premise is true and saying nothing at all about those individuals for whom the premise is false. Thus, the truth-table definition of ⇒ turns out to be perfect for writing general rules with universal quantifiers.
A common mistake, made frequently even by diligent readers who have read this paragraph several times, is to use conjunction instead of implication. The sentence
∀x King(x) ∧ Person(x)
would be equivalent to asserting
Richard the Lionheart is a king ∧ Richard the Lionheart is a person, King John is a king ∧King John is a person, Richard’s left leg is a king ∧ Richard’s left leg is a person,
and so on. Obviously, this does not capture what we want.
Existential quantification (∃)
Universal quantification makes statements about every object. Similarly, we can make a statement about some object in the universe without naming it, by using an existential quantifier. To say, for example, that King John has a crown on his head, we write
∃x Crown(x) ∧OnHead(x, John) .
∃x is pronounced “There exists an x such that . . .” or “For some x . . .”.
Intuitively, the sentence ∃x P says that P is true for at least one object x. More precisely, ∃x P is true in a given model if P is true in at least one extended interpretation that assigns x to a domain element. That is, at least one of the following is true:
Richard the Lionheart is a crown ∧ Richard the Lionheart is on John’s head; King John is a crown ∧ King John is on John’s head; Richard’s left leg is a crown ∧ Richard’s left leg is on John’s head; John’s left leg is a crown ∧ John’s left leg is on John’s head; The crown is a crown ∧ the crown is on John’s head.
The fifth assertion is true in the model, so the original existentially quantified sentence is true in the model. Notice that, by our definition, the sentence would also be true in a model in which King John was wearing two crowns. This is entirely consistent with the original sentence “King John has a crown on his head.”^7^
Just as⇒ appears to be the natural connective to use with ∀, ∧ is the natural connective to use with ∃. Using ∧ as the main connective with ∀ led to an overly strong statement in the example in the previous section; using ⇒ with ∃ usually leads to a very weak statement, indeed. Consider the following sentence:
∃x Crown(x) ⇒ OnHead(x, John) .
On the surface, this might look like a reasonable rendition of our sentence. Applying the semantics, we see that the sentence says that at least one of the following assertions is true:
Richard the Lionheart is a crown ⇒ Richard the Lionheart is on John’s head; King John is a crown ⇒ King John is on John’s head; Richard’s left leg is a crown ⇒ Richard’s left leg is on John’s head;
and so on. Now an implication is true if both premise and conclusion are true, or if its premise is false. So if Richard the Lionheart is not a crown, then the first assertion is true and the existential is satisfied. So, an existentially quantified implication sentence is true whenever any object fails to satisfy the premise; hence such sentences really do not say much at all.
Nested quantifiers
We will often want to express more complex sentences using multiple quantifiers. The simplest case is where the quantifiers are of the same type. For example, “Brothers are siblings” can be written as
∀x ∀ y Brother (x, y) ⇒ Sibling(x, y) .
7 There is a variant of the existential quantifier, usually written ∃ 1 or ∃!, that means “There exists exactly one.” The same meaning can be expressed using equality statements.
Consecutive quantifiers of the same type can be written as one quantifier with several variables. For example, to say that siblinghood is a symmetric relationship, we can write
∀x, y Sibling(x, y) ⇔ Sibling(y, x) .
In other cases we will have mixtures. “Everybody loves somebody” means that for every person, there is someone that person loves:
∀x ∃ y Loves(x, y) .
On the other hand, to say “There is someone who is loved by everyone,” we write
∃ y ∀x Loves(x, y) .
The order of quantification is therefore very important. It becomes clearer if we insert parentheses. ∀x (∃ y Loves(x, y)) says that everyone has a particular property, namely, the property that they love someone. On the other hand, ∃ y (∀x Loves(x, y)) says that someone in the world has a particular property, namely the property of being loved by everybody.
Some confusion can arise when two quantifiers are used with the same variable name. Consider the sentence
∀x (Crown(x) ∨ (∃x Brother (Richard , x))) .
Here the x in Brother (Richard , x) is existentially quantified. The rule is that the variable belongs to the innermost quantifier that mentions it; then it will not be subject to any other quantification. Another way to think of it is this: ∃x Brother (Richard , x) is a sentence about Richard (that he has a brother), not about x; so putting a ∀x outside it has no effect. It could equally well have been written ∃ z Brother (Richard , z). Because this can be a source of confusion, we will always use different variable names with nested quantifiers.
Connections between ∀ and ∃
The two quantifiers are actually intimately connected with each other, through negation. Asserting that everyone dislikes parsnips is the same as asserting there does not exist someone who likes them, and vice versa:
∀x ¬Likes(x,Parsnips) is equivalent to ¬∃x Likes(x,Parsnips).
We can go one step further: “Everyone likes ice cream” means that there is no one who does not like ice cream:
∀x Likes(x, IceCream) is equivalent to ¬∃x ¬Likes(x, IceCream).
Because ∀ is really a conjunction over the universe of objects and ∃ is a disjunction, it should not be surprising that they obey De Morgan’s rules. The De Morgan rules for quantified and unquantified sentences are as follows:
∀x ¬P ≡ ¬∃x P ¬(P ∨ Q) ≡ ¬P ∧ ¬Q
¬∀x P ≡ ∃x ¬P ¬(P ∧ Q) ≡ ¬P ∨ ¬Q
∀x P ≡ ¬∃x ¬P P ∧ Q ≡ ¬(¬P ∨ ¬Q)
∃x P ≡ ¬∀x ¬P P ∨ Q ≡ ¬(¬P ∧ ¬Q) .
Thus, we do not really need both ∀ and ∃, just as we do not really need both ∧ and ∨. Still, readability is more important than parsimony, so we will keep both of the quantifiers.
Equality
First-order logic includes one more way to make atomic sentences, other than using a predicate and terms as described earlier. We can use the equality symbol to signify that two terms refer to the same object. For example,
Father (John)=Henry
says that the object referred to by Father (John) and the object referred to by Henry are the same. Because an interpretation fixes the referent of any term, determining the truth of an equality sentence is simply a matter of seeing that the referents of the two terms are the same object.
The equality symbol can be used to state facts about a given function, as we just did for the Father symbol. It can also be used with negation to insist that two terms are not the same object. To say that Richard has at least two brothers, we would write
∃x, y Brother (x,Richard ) ∧ Brother (y,Richard ) ∧ ¬(x= y) .
The sentence
∃x, y Brother (x,Richard ) ∧ Brother (y,Richard )
does not have the intended meaning. In particular, it is true in the model of Figure 8.2, where Richard has only one brother. To see this, consider the extended interpretation in which both x and y are assigned to King John. The addition of ¬(x= y) rules out such models. The notation x y is sometimes used as an abbreviation for ¬(x= y).
An alternative semantics?
Continuing the example from the previous section, suppose that we believe that Richard has two brothers, John and Geoffrey.8 Can we capture this state of affairs by asserting
Brother (John ,Richard ) ∧ Brother (Geoffrey ,Richard) ? (8.3)
Not quite. First, this assertion is true in a model where Richard has only one brother— we need to add John ≠ Geoffrey . Second, the sentence doesn’t rule out models in which Richard has many more brothers besides John and Geoffrey. Thus, the correct translation of “Richard’s brothers are John and Geoffrey” is as follows:
Brother (John ,Richard ) ∧ Brother (Geoffrey ,Richard) ∧ John ≠ Geoffrey
∧ ∀x Brother (x,Richard ) ⇒ (x= John ∨ x=Geoffrey) .
For many purposes, this seems much more cumbersome than the corresponding naturallanguage expression. As a consequence, humans may make mistakes in translating their knowledge into first-order logic, resulting in unintuitive behaviors from logical reasoning systems that use the knowledge. Can we devise a semantics that allows a more straightforward logical expression?
One proposal that is very popular in database systems works as follows. First, we insist that every constant symbol refer to a distinct object—the so-called unique-names assumption. Second, we assume that atomic sentences not known to be true are in fact false—the closed-world assumption. Finally, we invoke domain closure, meaning that each model
8 Actually he had four, the others being William and Henry.
contains no more domain elements than those named by the constant symbols. Under the resulting semantics, which we call database semantics to distinguish it from the standard semantics of first-order logic, the sentence Equation (8.3) does indeed state that Richard’s two brothers are John and Geoffrey. Database semantics is also used in logic programming systems, as explained in Section 9.4.5.
It is instructive to consider the set of all possible models under database semantics for the same case as shown in Figure 8.4. Figure 8.5 shows some of the models, ranging from the model with no tuples satisfying the relation to the model with all tuples satisfying the relation. With two objects, there are four possible two-element tuples, so there are 2^4^ = 16
different subsets of tuples that can satisfy the relation. Thus, there are 16 possible models in all—a lot fewer than the infinitely many models for the standard first-order semantics. On the other hand, the database semantics requires definite knowledge of what the world contains.
This example brings up an important point: there is no one “correct” semantics for logic. The usefulness of any proposed semantics depends on how concise and intuitive it makes the expression of the kinds of knowledge we want to write down, and on how easy and natural it is to develop the corresponding rules of inference. Database semantics is most useful when we are certain about the identity of all the objects described in the knowledge base and when we have all the facts at hand; in other cases, it is quite awkward. For the rest of this chapter, we assume the standard semantics while noting instances in which this choice leads to cumbersome expressions.
USING FIRST-ORDER LOGIC
Now that we have defined an expressive logical language, it is time to learn how to use it. The best way to do this is through examples. We have seen some simple sentences illustrating the various aspects of logical syntax; in this section, we provide more systematic representations of some simple domains. In knowledge representation, a domain is just some part of the world about which we wish to express some knowledge.
We begin with a brief description of the TELL/ASK interface for first-order knowledge bases. Then we look at the domains of family relationships, numbers, sets, and lists, and at the wumpus world. The next section contains a more substantial example (electronic circuits) and Chapter 12 covers everything in the universe.
Assertions and queries in first-order logic
Sentences are added to a knowledge base using TELL, exactly as in propositional logic. Such sentences are called assertions. For example, we can assert that John is a king, Richard is a person, and all kings are persons:
TELL(KB , King(John)) .
TELL(KB , Person(Richard)) .
TELL(KB , ∀x King(x) ⇒ Person(x)) .
We can ask questions of the knowledge base using ASK. For example,
ASK(KB , King(John))
returns true . Questions asked with ASK are called queries or goals. Generally speaking, any query that is logically entailed by the knowledge base should be answered affirmatively. For example, given the two preceding assertions, the query
ASK(KB , Person(John))
should also return true . We can ask quantified queries, such as
ASK(KB , ∃x Person(x)) .
The answer is true , but this is perhaps not as helpful as we would like. It is rather like answering “Can you tell me the time?” with “Yes.” If we want to know what value of x makes the sentence true, we will need a different function, ASKVARS, which we call with
ASKVARS(KB ,Person(x))
and which yields a stream of answers. In this case there will be two answers: {x/John} and {x/Richard}. Such an answer is called a substitution or binding list. ASKVARS is usually reserved for knowledge bases consisting solely of Horn clauses, because in such knowledge bases every way of making the query true will bind the variables to specific values. That is not the case with first-order logic; if KB has been told King(John) ∨King(Richard ), then there is no binding to x for the query ∃x King(x), even though the query is true.
The kinship domain
The first example we consider is the domain of family relationships, or kinship. This domain includes facts such as “Elizabeth is the mother of Charles” and “Charles is the father of William” and rules such as “One’s grandmother is the mother of one’s parent.”
Clearly, the objects in our domain are people. We have two unary predicates, Male and Female . Kinship relations—parenthood, brotherhood, marriage, and so on—are represented by binary predicates: Parent , Sibling , Brother , Sister , Child , Daughter , Son , Spouse , Wife, Husband , Grandparent , Grandchild , Cousin, Aunt , and Uncle . We use functions for Mother and Father , because every person has exactly one of each of these (at least according to nature’s design).
We can go through each function and predicate, writing down what we know in terms of the other symbols. For example,
one’s mother is one’s female parent:
∀m, c Mother (c)= m ⇔ Female(m) ∧ Parent(m, c) .
One’s husband is one’s male spouse:
∀w, h Husband(h,w) ⇔ Male(h) ∧ Spouse(h,w) .
Male and female are disjoint categories:
∀x Male(x) ⇔ ¬Female(x) .
Parent and child are inverse relations:
∀ p, c Parent(p, c) ⇔ Child(c, p) .
A grandparent is a parent of one’s parent:
∀ g, c Grandparent (g, c) ⇔ ∃ p Parent(g, p) ∧ Parent(p, c) .
A sibling is another child of one’s parents:
∀x, y Sibling(x, y) ⇔ x ≠ y ∧ ∃ p Parent(p, x) ∧ Parent(p, y) .
We could go on for several more pages like this, and Exercise 8.14 asks you to do just that.
Each of these sentences can be viewed as an axiom of the kinship domain, as explained in Section 7.1. Axioms are commonly associated with purely mathematical domains—we will see some axioms for numbers shortly—but they are needed in all domains. They provide the basic factual information from which useful conclusions can be derived. Our kinship axioms are also definitions; they have the form ∀x, y P (x, y) ⇔ . . .. The axioms define the Mother function and the Husband , Male , Parent , Grandparent , and Sibling predicates in terms of other predicates. Our definitions “bottom out” at a basic set of predicates (Child , Spouse , and Female) in terms of which the others are ultimately defined. This is a natural way in which to build up the representation of a domain, and it is analogous to the way in which software packages are built up by successive definitions of subroutines from primitive library functions. Notice that there is not necessarily a unique set of primitive predicates; we could equally well have used Parent , Spouse , and Male . In some domains, as we show, there is no clearly identifiable basic set.
Not all logical sentences about a domain are axioms. Some are theorems—that is, they are entailed by the axioms. For example, consider the assertion that siblinghood is symmetric:
∀x, y Sibling(x, y) ⇔ Sibling(y, x) .
Is this an axiom or a theorem? In fact, it is a theorem that follows logically from the axiom that defines siblinghood. If we ASK the knowledge base this sentence, it should return true .
From a purely logical point of view, a knowledge base need contain only axioms and no theorems, because the theorems do not increase the set of conclusions that follow from the knowledge base. From a practical point of view, theorems are essential to reduce the computational cost of deriving new sentences. Without them, a reasoning system has to start from first principles every time, rather like a physicist having to rederive the rules of calculus for every new problem.
Not all axioms are definitions. Some provide more general information about certain predicates without constituting a definition. Indeed, some predicates have no complete definition because we do not know enough to characterize them fully. For example, there is no obvious definitive way to complete the sentence
∀x Person(x) ⇔ . . .
Fortunately, first-order logic allows us to make use of the Person predicate without completely defining it. Instead, we can write partial specifications of properties that every person has and properties that make something a person:
∀x Person(x) ⇒ . . .
∀x . . . ⇒ Person(x) .
Axioms can also be “just plain facts,” such as Male(Jim) and Spouse(Jim,Laura). Such facts form the descriptions of specific problem instances, enabling specific questions to be answered. The answers to these questions will then be theorems that follow from the axioms. Often, one finds that the expected answers are not forthcoming—for example, from Spouse(Jim,Laura) one expects (under the laws of many countries) to be able to infer ¬Spouse(George ,Laura); but this does not follow from the axioms given earlier—even after we add Jim ≠ George as suggested in Section 8.2.8. This is a sign that an axiom is missing. Exercise 8.8 asks the reader to supply it.
Numbers, sets, and lists
Numbers are perhaps the most vivid example of how a large theory can be built up from a tiny kernel of axioms. We describe here the theory of natural numbers or non-negative integers. We need a predicate NatNum that will be true of natural numbers; we need one constant symbol, 0; and we need one function symbol, S (successor). The Peano axioms define natural numbers and addition.9 Natural numbers are defined recursively:
NatNum(0) .
∀n NatNum(n) ⇒ NatNum(S(n)) .
That is, 0 is a natural number, and for every object n, if n is a natural number, then S(n) is a natural number. So the natural numbers are 0, S(0), S(S(0)), and so on. (After reading Section 8.2.8, you will notice that these axioms allow for other natural numbers besides the usual ones; see Exercise 8.12.) We also need axioms to constrain the successor function:
∀n 0 ≠ S(n) .
∀m,n m ≠ n ⇒ S(m) ≠ S(n) .
Now we can define addition in terms of the successor function:
∀m NatNum(m) ⇒ + (0,m) = m .
∀m,n NatNum(m) ∧ NatNum(n) ⇒ + (S(m), n) = S(+(m,n)) .
The first of these axioms says that adding 0 to any natural number m gives m itself. Notice the use of the binary function symbol “+” in the term +(m, 0); in ordinary mathematics, the term would be written m + 0 using infix notation. (The notation we have used for first-orderINFIX
9 The Peano axioms also include the principle of induction, which is a sentence of second-order logic rather than of first-order logic. The importance of this distinction is explained in Chapter 9.
logic is called prefix.) To make our sentences about numbers easier to read, we allow the use of infix notation. We can also write S(n) as n + 1, so the second axiom becomes
∀m,n NatNum(m) ∧ NatNum(n) ⇒ (m + 1) + n = (m + n) + 1 .
This axiom reduces addition to repeated application of the successor function. The use of infix notation is an example of syntactic sugar, that is, an extension to or abbreviation of the standard syntax that does not change the semantics. Any sentence that uses sugar can be “desugared” to produce an equivalent sentence in ordinary first-order logic.
Once we have addition, it is straightforward to define multiplication as repeated addition, exponentiation as repeated multiplication, integer division and remainders, prime numbers, and so on. Thus, the whole of number theory (including cryptography) can be built up from one constant, one function, one predicate and four axioms.
The domain of sets is also fundamental to mathematics as well as to commonsense reasoning. (In fact, it is possible to define number theory in terms of set theory.) We want to be able to represent individual sets, including the empty set. We need a way to build up sets by adding an element to a set or taking the union or intersection of two sets. We will want to know whether an element is a member of a set and we will want to distinguish sets from objects that are not sets.
We will use the normal vocabulary of set theory as syntactic sugar. The empty set is a constant written as { }. There is one unary predicate, Set , which is true of sets. The binary predicates are x ∈ s (x is a member of set s) and s~1~ ⊆ s~2~ (set s~1~ is a subset, not necessarily proper, of set s~2~). The binary functions are s~1~ ∩ s~2~ (the intersection of two sets), s~1~ ∪ s~2~ (the union of two sets), and {x|s} (the set resulting from adjoining element x to set s). One possible set of axioms is as follows:
- The only sets are the empty set and those made by adjoining something to a set:
∀ s Set(s) ⇔ (s = { }) ∨ (∃x, s~2~ Set(s~2~) ∧ s = {x|s~2~}) .
- The empty set has no elements adjoined into it. In other words, there is no way to decompose { } into a smaller set and an element:
¬∃x, s {x|s}= { } .
- Adjoining an element already in the set has no effect:
∀x, s x ∈ s ⇔ s = {x|s} .
- The only members of a set are the elements that were adjoined into it. We express this recursively, saying that x is a member of s if and only if s is equal to some set s~2~
adjoined with some element y, where either y is the same as x or x is a member of s~2~:
∀x, s x ∈ s ⇔ ∃ y, s~2~ (s = {y|s~2~} ∧ (x= y ∨ x ∈ s~2~)) .
- A set is a subset of another set if and only if all of the first set’s members are members of the second set:
∀ s~1~, s~2~ s~1~ ⊆ s~2~ ⇔ (∀x x ∈ s~1~ ⇒ x ∈ s~2~) .
- Two sets are equal if and only if each is a subset of the other:
∀ s~1~, s~2~ (s~1~ = s~2~) ⇔ (s~1~ ⊆ s~2~ ∧ s~2~ ⊆ s~1~) .
- An object is in the intersection of two sets if and only if it is a member of both sets:
∀x, s~1~, s~2~ x ∈ (s~1~ ∩ s~2~) ⇔ (x ∈ s~1~ ∧ x ∈ s~2~) .
- An object is in the union of two sets if and only if it is a member of either set:
∀x, s~1~, s~2~ x ∈ (s~1~ ∪ s~2~) ⇔ (x ∈ s~1~ ∨ x ∈ s~2~) .
Lists are similar to sets. The differences are that lists are ordered and the same element can appear more than once in a list. We can use the vocabulary of Lisp for lists: Nil is the constant list with no elements; Cons , Append , First , and Rest are functions; and Find is the predicate that does for lists what Member does for sets. List? is a predicate that is true only of lists. As with sets, it is common to use syntactic sugar in logical sentences involving lists. The empty list is [ ]. The term Cons(x, y), where y is a nonempty list, is written [x|y]. The term Cons(x,Nil) (i.e., the list containing the element x) is written as [x]. A list of several elements, such as [A,B,C], corresponds to the nested term Cons(A,Cons(B,Cons(C,Nil))). Exercise 8.16 asks you to write out the axioms for lists.
The wumpus world
Some propositional logic axioms for the wumpus world were given in Chapter 7. The firstorder axioms in this section are much more concise, capturing in a natural way exactly what we want to say.
Recall that the wumpus agent receives a percept vector with five elements. The corresponding first-order sentence stored in the knowledge base must include both the percept and the time at which it occurred; otherwise, the agent will get confused about when it saw what. We use integers for time steps. A typical percept sentence would be
Percept([Stench,Breeze ,Glitter ,None,None], 5) .
Here, Percept is a binary predicate, and Stench and so on are constants placed in a list. The actions in the wumpus world can be represented by logical terms:
Turn(Right), Turn(Left), Forward , Shoot , Grab, Climb .
To determine which is best, the agent program executes the query
ASKVARS(∃ a BestAction(a, 5)) ,
which returns a binding list such as {a/Grab}. The agent program can then return Grab as the action to take. The raw percept data implies certain facts about the current state. For example:
∀ t, s, g,m, c Percept([s,Breeze , g,m, c], t) ⇒ Breeze(t) ,
∀ t, s, b,m, c Percept([s, b,Glitter ,m, c], t) ⇒ Glitter(t) ,
and so on. These rules exhibit a trivial form of the reasoning process called perception, which we study in depth in Chapter 24. Notice the quantification over time t. In propositional logic, we would need copies of each sentence for each time step.
Simple “reflex” behavior can also be implemented by quantified implication sentences. For example, we have
∀ t Glitter(t) ⇒ BestAction(Grab, t) .
Given the percept and rules from the preceding paragraphs, this would yield the desired conclusion BestAction(Grab, 5)—that is, Grab is the right thing to do.
We have represented the agent’s inputs and outputs; now it is time to represent the environment itself. Let us begin with objects. Obvious candidates are squares, pits, and the wumpus. We could name each square—Square1,2 and so on—but then the fact that Square1,2 and Square1,3 are adjacent would have to be an “extra” fact, and we would need one such fact for each pair of squares. It is better to use a complex term in which the row and column appear as integers; for example, we can simply use the list term [1, 2]. Adjacency of any two squares can be defined as
∀ x, y, a, b Adjacent([x, y], [a, b]) ⇔
(x = a ∧ (y = b− 1 ∨ y = b + 1)) ∨ (y = b ∧ (x = a− 1 ∨ x = a + 1)) .
We could name each pit, but this would be inappropriate for a different reason: there is no reason to distinguish among pits.10 It is simpler to use a unary predicate Pit that is true of squares containing pits. Finally, since there is exactly one wumpus, a constant Wumpus is just as good as a unary predicate (and perhaps more dignified from the wumpus’s viewpoint).
The agent’s location changes over time, so we write At(Agent , s, t) to mean that the agent is at square s at time t. We can fix the wumpus’s location with ∀tAt(Wumpus , [2, 2], t). We can then say that objects can only be at one location at a time:
∀ x, s~1~, s~2~, t At(x, s~1~, t) ∧ At(x, s~2~, t) ⇒ s~1~ = s~2~ .
Given its current location, the agent can infer properties of the square from properties of its current percept. For example, if the agent is at a square and perceives a breeze, then that square is breezy:
∀ s, t At(Agent , s, t) ∧ Breeze(t) ⇒ Breezy(s) .
It is useful to know that a square is breezy because we know that the pits cannot move about. Notice that Breezy has no time argument.
Having discovered which places are breezy (or smelly) and, very important, not breezy (or not smelly), the agent can deduce where the pits are (and where the wumpus is). Whereas propositional logic necessitates a separate axiom for each square (see R~2~ and R~3~ on page 247) and would need a different set of axioms for each geographical layout of the world, first-order logic just needs one axiom:
∀ s Breezy(s) ⇔ ∃ r Adjacent(r, s) ∧ Pit(r) . (8.4)
Similarly, in first-order logic we can quantify over time, so we need just one successor-state axiom for each predicate, rather than a different copy for each time step. For example, the axiom for the arrow (Equation (7.2) on page 267) becomes
∀ t HaveArrow (t + 1) ⇔ (HaveArrow (t) ∧ ¬Action(Shoot , t)) .
From these two example sentences, we can see that the first-order logic formulation is no less concise than the original English-language description given in Chapter 7. The reader
10 Similarly, most of us do not name each bird that flies overhead as it migrates to warmer regions in winter. An ornithologist wishing to study migration patterns, survival rates, and so on does name each bird, by means of a ring on its leg, because individual birds must be tracked.
is invited to construct analogous axioms for the agent’s location and orientation; in these cases, the axioms quantify over both space and time. As in the case of propositional state estimation, an agent can use logical inference with axioms of this kind to keep track of aspects of the world that are not directly observed. Chapter 10 goes into more depth on the subject of first-order successor-state axioms and their uses for constructing plans.
KNOWLEDGE ENGINEERING IN FIRST-ORDER LOGIC
The preceding section illustrated the use of first-order logic to represent knowledge in three simple domains. This section describes the general process of knowledge-base construction— a process called knowledge engineering. A knowledge engineer is someone who investigates a particular domain, learns what concepts are important in that domain, and creates a formal representation of the objects and relations in the domain. We illustrate the knowledge engineering process in an electronic circuit domain that should already be fairly familiar, so that we can concentrate on the representational issues involved. The approach we take is suitable for developing special-purpose knowledge bases whose domain is carefully circumscribed and whose range of queries is known in advance. General-purpose knowledge bases, which cover a broad range of human knowledge and are intended to support tasks such as natural language understanding, are discussed in Chapter 12.
The knowledge-engineering process
Knowledge engineering projects vary widely in content, scope, and difficulty, but all such projects include the following steps:
-
Identify the task. The knowledge engineer must delineate the range of questions that the knowledge base will support and the kinds of facts that will be available for each specific problem instance. For example, does the wumpus knowledge base need to be able to choose actions or is it required to answer questions only about the contents of the environment? Will the sensor facts include the current location? The task will determine what knowledge must be represented in order to connect problem instances to answers. This step is analogous to the PEAS process for designing agents in Chapter 2.
-
Assemble the relevant knowledge. The knowledge engineer might already be an expert in the domain, or might need to work with real experts to extract what they know—a process called knowledge acquisition. At this stage, the knowledge is not represented formally. The idea is to understand the scope of the knowledge base, as determined by the task, and to understand how the domain actually works.
For the wumpus world, which is defined by an artificial set of rules, the relevant knowledge is easy to identify. (Notice, however, that the definition of adjacency was not supplied explicitly in the wumpus-world rules.) For real domains, the issue of relevance can be quite difficult—for example, a system for simulating VLSI designs might or might not need to take into account stray capacitances and skin effects.
-
Decide on a vocabulary of predicates, functions, and constants. That is, translate the important domain-level concepts into logic-level names. This involves many questions of knowledge-engineering style. Like programming style, this can have a significant impact on the eventual success of the project. For example, should pits be represented by objects or by a unary predicate on squares? Should the agent’s orientation be a function or a predicate? Should the wumpus’s location depend on time? Once the choices have been made, the result is a vocabulary that is known as the ontology of the domain. The word ontology means a particular theory of the nature of being or existence. The ontology determines what kinds of things exist, but does not determine their specific properties and interrelationships.
-
Encode general knowledge about the domain. The knowledge engineer writes down the axioms for all the vocabulary terms. This pins down (to the extent possible) the meaning of the terms, enabling the expert to check the content. Often, this step reveals misconceptions or gaps in the vocabulary that must be fixed by returning to step 3 and iterating through the process.
-
Encode a description of the specific problem instance. If the ontology is well thought out, this step will be easy. It will involve writing simple atomic sentences about instances of concepts that are already part of the ontology. For a logical agent, problem instances are supplied by the sensors, whereas a “disembodied” knowledge base is supplied with additional sentences in the same way that traditional programs are supplied with input data.
-
Pose queries to the inference procedure and get answers. This is where the reward is: we can let the inference procedure operate on the axioms and problem-specific facts to derive the facts we are interested in knowing. Thus, we avoid the need for writing an application-specific solution algorithm.
-
Debug the knowledge base. Alas, the answers to queries will seldom be correct on the first try. More precisely, the answers will be correct for the knowledge base as written, assuming that the inference procedure is sound, but they will not be the ones that the user is expecting. For example, if an axiom is missing, some queries will not be answerable from the knowledge base. A considerable debugging process could ensue. Missing axioms or axioms that are too weak can be easily identified by noticing places where the chain of reasoning stops unexpectedly. For example, if the knowledge base includes a diagnostic rule (see Exercise 8.13) for finding the wumpus,
∀ s Smelly(s) ⇒ Adjacent(Home(Wumpus), s) ,
instead of the biconditional, then the agent will never be able to prove the absence of wumpuses. Incorrect axioms can be identified because they are false statements about the world. For example, the sentence
∀x NumOfLegs(x, 4) ⇒ Mammal(x)
is false for reptiles, amphibians, and, more importantly, tables. The falsehood of this sentence can be determined independently of the rest of the knowledge base. In contrast, a typical error in a program looks like this:
offset = position + 1 .
It is impossible to tell whether this statement is correct without looking at the rest of the program to see whether, for example, offset is used to refer to the current position, or to one beyond the current position, or whether the value of position is changed by another statement and so offset should also be changed again.
To understand this seven-step process better, we now apply it to an extended example—the domain of electronic circuits.
The electronic circuits domain
We will develop an ontology and knowledge base that allow us to reason about digital circuits of the kind shown in Figure 8.6. We follow the seven-step process for knowledge engineering.
Identify the task
There are many reasoning tasks associated with digital circuits. At the highest level, one analyzes the circuit’s functionality. For example, does the circuit in Figure 8.6 actually add properly? If all the inputs are high, what is the output of gate A~2~? Questions about the circuit’s structure are also interesting. For example, what are all the gates connected to the first input terminal? Does the circuit contain feedback loops? These will be our tasks in this section. There are more detailed levels of analysis, including those related to timing delays, circuit area, power consumption, production cost, and so on. Each of these levels would require additional knowledge.
Assemble the relevant knowledge
What do we know about digital circuits? For our purposes, they are composed of wires and gates. Signals flow along wires to the input terminals of gates, and each gate produces a
signal on the output terminal that flows along another wire. To determine what these signals will be, we need to know how the gates transform their input signals. There are four types of gates: AND, OR, and XOR gates have two input terminals, and NOT gates have one. All gates have one output terminal. Circuits, like gates, have input and output terminals.
To reason about functionality and connectivity, we do not need to talk about the wires themselves, the paths they take, or the junctions where they come together. All that matters is the connections between terminals—we can say that one output terminal is connected to another input terminal without having to say what actually connects them. Other factors such as the size, shape, color, or cost of the various components are irrelevant to our analysis.
If our purpose were something other than verifying designs at the gate level, the ontology would be different. For example, if we were interested in debugging faulty circuits, then it would probably be a good idea to include the wires in the ontology, because a faulty wire can corrupt the signal flowing along it. For resolving timing faults, we would need to include gate delays. If we were interested in designing a product that would be profitable, then the cost of the circuit and its speed relative to other products on the market would be important.
Decide on a vocabulary
We now know that we want to talk about circuits, terminals, signals, and gates. The next step is to choose functions, predicates, and constants to represent them. First, we need to be able to distinguish gates from each other and from other objects. Each gate is represented as an object named by a constant, about which we assert that it is a gate with, say, Gate(X~1~). The behavior of each gate is determined by its type: one of the constants AND,OR, XOR, or NOT . Because a gate has exactly one type, a function is appropriate: Type(X~1~)=XOR. Circuits, like gates, are identified by a predicate: Circuit(C~1~).
Next we consider terminals, which are identified by the predicate Terminal(x). A gate or circuit can have one or more input terminals and one or more output terminals. We use the function In(1,X~1~) to denote the first input terminal for gate X~1~. A similar function Out is used for output terminals. The function Arity(c, i, j) says that circuit c has i input and j output terminals. The connectivity between gates can be represented by a predicate, Connected , which takes two terminals as arguments, as in Connected(Out(1,X~1~), In(1,X~2~)).
Finally, we need to know whether a signal is on or off. One possibility is to use a unary predicate, On(t), which is true when the signal at a terminal is on. This makes it a little difficult, however, to pose questions such as “What are all the possible values of the signals at the output terminals of circuit C~1~ ?” We therefore introduce as objects two signal values, 1 and 0, and a function Signal(t) that denotes the signal value for the terminal t.
Encode general knowledge of the domain
One sign that we have a good ontology is that we require only a few general rules, which can be stated clearly and concisely. These are all the axioms we will need:
-
If two terminals are connected, then they have the same signal: ∀ t~1~, t~2~ Terminal(t~1~) ∧ Terminal(t~2~) ∧Connected(t~1~, t~2~) ⇒ Signal(t~1~)= Signal(t~2~) .
-
The signal at every terminal is either 1 or 0:
∀ t Terminal(t) ⇒ Signal(t)= 1 ∨ Signal(t)= 0 .
- Connected is commutative:
∀ t~1~, t~2~ Connected(t~1~, t~2~) ⇔ Connected(t~2~, t~1~) .
- There are four types of gates:
∀ g Gate(g) ∧ k = Type(g) ⇒ k = AND ∨ k = OR ∨ k = XOR ∨ k = NOT .
- An AND gate’s output is 0 if and only if any of its inputs is 0:
∀ g Gate(g) ∧ Type(g)= AND ⇒
Signal(Out(1, g))= 0 ⇔ ∃n Signal(In(n, g))= 0 .
- An OR gate’s output is 1 if and only if any of its inputs is 1:
∀ g Gate(g) ∧ Type(g)= OR ⇒
Signal(Out(1, g))= 1 ⇔ ∃n Signal(In(n, g))= 1 .
- An XOR gate’s output is 1 if and only if its inputs are different:
∀ g Gate(g) ∧ Type(g)= XOR ⇒
Signal(Out(1, g))= 1 ⇔ Signal(In(1, g)) ≠ Signal(In(2, g)) .
- A NOT gate’s output is different from its input:
∀ g Gate(g) ∧ (Type(g)= NOT ) ⇒
Signal(Out(1, g)) ≠ Signal(In(1, g)) .
- The gates (except for NOT) have two inputs and one output.
∀ g Gate(g) ∧ Type(g) = NOT ⇒ Arity(g, 1, 1) .
∀ g Gate(g) ∧ k = Type(g) ∧ (k = AND ∨ k = OR ∨ k = XOR) ⇒
Arity(g, 2, 1)
- A circuit has terminals, up to its input and output arity, and nothing beyond its arity:
∀ c, i, j Circuit(c) ∧Arity(c, i, j) ⇒
∀n (n ≤ i ⇒ Terminal(In(c, n))) ∧ (n > i ⇒ In(c, n) = Nothing) ∧
∀n (n ≤ j ⇒ Terminal(Out(c, n))) ∧ (n > j ⇒ Out(c, n) = Nothing)
- Gates, terminals, signals, gate types, and Nothing are all distinct.
∀ g, t Gate(g) ∧ Terminal(t) ⇒
g ≠ t ≠ 1 ≠ 0 ≠ OR ≠ AND ≠ XOR ≠ NOT ≠ Nothing .
- Gates are circuits.
∀ g Gate(g) ⇒ Circuit(g)
Encode the specific problem instance
The circuit shown in Figure 8.6 is encoded as circuit C~1~ with the following description. First, we categorize the circuit and its component gates:
Circuit(C~1~) ∧ Arity(C~1~, 3, 2)
Gate(X~1~) ∧ Type(X~1~)=XOR
Gate(X~2~) ∧ Type(X~2~)=XOR
Gate(A~1~) ∧ Type(A~1~)=AND
Gate(A~2~) ∧ Type(A~2~)=AND
Gate(O~1~) ∧ Type(O~1~)= OR .
Then, we show the connections between them:
Connected(Out(1,X~1~), In(1,X~2~)) Connected(In(1, C~1~), In(1,X~1~))
Connected(Out(1,X~1~), In(2, A~2~)) Connected(In(1, C~1~), In(1, A~1~))
Connected(Out(1, A~2~), In(1, O~1~)) Connected(In(2, C~1~), In(2,X~1~))
Connected(Out(1, A~1~), In(2, O~1~)) Connected(In(2, C~1~), In(2, A~1~))
Connected(Out(1,X~2~),Out(1, C~1~)) Connected(In(3, C~1~), In(2,X~2~))
Connected(Out(1, O~1~),Out(2, C~1~)) Connected(In(3, C~1~), In(1, A~2~)) .
Pose queries to the inference procedure
What combinations of inputs would cause the first output of C~1~ (the sum bit) to be 0 and the second output of C~1~ (the carry bit) to be 1?
∃ i~1~, i~2~, i~3~ Signal(In(1, C~1~))= i~1~ ∧ Signal (In(2, C~1~))= i~2~ ∧ Signal(In(3, C~1~))= i~3~
∧ Signal(Out(1, C~1~))=0 ∧ Signal(Out(2, C~1~))=1 .
The answers are substitutions for the variables i~1~, i~2~, and i~3~ such that the resulting sentence is entailed by the knowledge base. ASKVARS will give us three such substitutions:
{i~1~/1, i~2~/1, i~3~/0} {i~1~/1, i~2~/0, i~3~/1} {i~1~/0, i~2~/1, i~3~/1} .
What are the possible sets of values of all the terminals for the adder circuit?
∃ i~1~, i~2~, i~3~, O~1~, o~2~ Signal (In(1, C~1~))= i~1~ ∧ Signal(In(2, C~1~))= i~2~
∧ Signal(In(3, C~1~))= i~3~ ∧ Signal(Out(1, C~1~))= O~1~ ∧ Signal(Out(2, C~1~))= o~2~ .
This final query will return a complete input–output table for the device, which can be used to check that it does in fact add its inputs correctly. This is a simple example of circuit verification. We can also use the definition of the circuit to build larger digital systems, for which the same kind of verification procedure can be carried out. (See Exercise 8.26.) Many domains are amenable to the same kind of structured knowledge-base development, in which more complex concepts are defined on top of simpler concepts.
Debug the knowledge base
We can perturb the knowledge base in various ways to see what kinds of erroneous behaviors emerge. For example, suppose we fail to read Section 8.2.8 and hence forget to assert that 1 ≠ 0. Suddenly, the system will be unable to prove any outputs for the circuit, except for the input cases 000 and 110. We can pinpoint the problem by asking for the outputs of each gate. For example, we can ask
∃ i~1~, i~2~, o Signal(In(1, C~1~))= i~1~ ∧ Signal(In(2, C~1~))= i~2~ ∧ Signal(Out(1,X~1~)) ,
which reveals that no outputs are known at X~1~ for the input cases 10 and 01. Then, we look at the axiom for XOR gates, as applied to X~1~:
Signal(Out(1,X~1~))= 1 ⇔ Signal(In(1,X~1~)) ≠ Signal(In(2,X~1~)) .
If the inputs are known to be, say, 1 and 0, then this reduces to
Signal(Out(1,X~1~))= 1 ⇔ 1 ≠ 0 .
Now the problem is apparent: the system is unable to infer that Signal(Out(1,X~1~))= 1, so we need to tell it that 1 ≠ 0.
SUMMARY
This chapter has introduced first-order logic, a representation language that is far more powerful than propositional logic. The important points are as follows:
-
Knowledge representation languages should be declarative, compositional, expressive, context independent, and unambiguous.
-
Logics differ in their ontological commitments and epistemological commitments. While propositional logic commits only to the existence of facts, first-order logic commits to the existence of objects and relations and thereby gains expressive power.
-
The syntax of first-order logic builds on that of propositional logic. It adds terms to represent objects, and has universal and existential quantifiers to construct assertions about all or some of the possible values of the quantified variables.
-
A possible world, or model, for first-order logic includes a set of objects and an interpretation that maps constant symbols to objects, predicate symbols to relations among objects, and function symbols to functions on objects.
-
An atomic sentence is true just when the relation named by the predicate holds between the objects named by the terms. Extended interpretations, which map quantifier variables to objects in the model, define the truth of quantified sentences.
-
Developing a knowledge base in first-order logic requires a careful process of analyzing the domain, choosing a vocabulary, and encoding the axioms required to support the desired inferences.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
Although Aristotle’s logic deals with generalizations over objects, it fell far short of the expressive power of first-order logic. A major barrier to its further development was its concentration on one-place predicates to the exclusion of many-place relational predicates. The first systematic treatment of relations was given by Augustus De Morgan (1864), who cited the following example to show the sorts of inferences that Aristotle’s logic could not handle: “All horses are animals; therefore, the head of a horse is the head of an animal.” This inference is inaccessible to Aristotle because any valid rule that can support this inference must first analyze the sentence using the two-place predicate “x is the head of y.” The logic of relations was studied in depth by Charles Sanders Peirce (1870, 2004).
True first-order logic dates from the introduction of quantifiers in Gottlob Frege’s (1879) Begriffschrift (“Concept Writing” or “Conceptual Notation”). Peirce (1883) also developed first-order logic independently of Frege, although slightly later. Frege’s ability to nest quantifiers was a big step forward, but he used an awkward notation. The present notation for first-order logic is due substantially to Giuseppe Peano (1889), but the semantics is virtually identical to Frege’s. Oddly enough, Peano’s axioms were due in large measure to Grassmann (1861) and Dedekind (1888).
Leopold Löwenheim (1915) gave a systematic treatment of model theory for first-order logic, including the first proper treatment of the equality symbol. Löwenheim’s results were further extended by Thoralf Skolem (1920). Alfred Tarski (1935, 1956) gave an explicit definition of truth and model-theoretic satisfaction in first-order logic, using set theory.
McCarthy (1958) was primarily responsible for the introduction of first-order logic as a tool for building AI systems. The prospects for logic-based AI were advanced significantly by Robinson’s (1965) development of resolution, a complete procedure for first-order inference described in Chapter 9. The logicist approach took root at Stanford University. Cordell Green (1969a, 1969b) developed a first-order reasoning system, QA3, leading to the first attempts to build a logical robot at SRI (Fikes and Nilsson, 1971). First-order logic was applied by Zohar Manna and Richard Waldinger (1971) for reasoning about programs and later by Michael Genesereth (1984) for reasoning about circuits. In Europe, logic programming (a restricted form of first-order reasoning) was developed for linguistic analysis (Colmerauer et al., 1973) and for general declarative systems (Kowalski, 1974). Computational logic was also well entrenched at Edinburgh through the LCF (Logic for Computable Functions) project (Gordon et al., 1979). These developments are chronicled further in Chapters 9 and 12.
Practical applications built with first-order logic include a system for evaluating the manufacturing requirements for electronic products (Mannion, 2002), a system for reasoning about policies for file access and digital rights management (Halpern and Weissman, 2008), and a system for the automated composition of Web services (McIlraith and Zeng, 2001).
Reactions to the Whorf hypothesis (Whorf, 1956) and the problem of language and thought in general, appear in several recent books (Gumperz and Levinson, 1996; Bowerman and Levinson, 2001; Pinker, 2003; Gentner and Goldin-Meadow, 2003). The “theory” theory (Gopnik and Glymour, 2002; Tenenbaum et al., 2007) views children’s learning about the world as analogous to the construction of scientific theories. Just as the predictions of a machine learning algorithm depend strongly on the vocabulary supplied to it, so will the child’s formulation of theories depend on the linguistic environment in which learning occurs.
There are a number of good introductory texts on first-order logic, including some by leading figures in the history of logic: Alfred Tarski (1941), Alonzo Church (1956), and W.V. Quine (1982) (which is one of the most readable). Enderton (1972) gives a more mathematically oriented perspective. A highly formal treatment of first-order logic, along with many more advanced topics in logic, is provided by Bell and Machover (1977). Manna and Waldinger (1985) give a readable introduction to logic from a computer science perspective, as do Huth and Ryan (2004), who concentrate on program verification. Barwise and Etchemendy (2002) take an approach similar to the one used here. Smullyan (1995) presents results concisely, using the tableau format. Gallier (1986) provides an extremely rigorous mathematical exposition of first-order logic, along with a great deal of material on its use in automated reasoning. Logical Foundations of Artificial Intelligence (Genesereth and Nilsson, 1987) is both a solid introduction to logic and the first systematic treatment of logical agents with percepts and actions, and there are two good handbooks: van Bentham and ter Meulen (1997) and Robinson and Voronkov (2001). The journal of record for the field of pure mathematical logic is the Journal of Symbolic Logic, whereas the Journal of Applied Logic deals with concerns closer to those of artificial intelligence.
EXERCISES
8.1 A logical knowledge base represents the world using a set of sentences with no explicit structure. An analogical representation, on the other hand, has physical structure that corresponds directly to the structure of the thing represented. Consider a road map of your country as an analogical representation of facts about the country—it represents facts with a map language. The two-dimensional structure of the map corresponds to the two-dimensional surface of the area.
a. Give five examples of symbols in the map language.
b. An explicit sentence is a sentence that the creator of the representation actually writes down. An implicit sentence is a sentence that results from explicit sentences because of properties of the analogical representation. Give three examples each of implicit and explicit sentences in the map language.
c. Give three examples of facts about the physical structure of your country that cannot be represented in the map language.
d. Give two examples of facts that are much easier to express in the map language than in first-order logic.
e. Give two other examples of useful analogical representations. What are the advantages and disadvantages of each of these languages?
8.2 Consider a knowledge base containing just two sentences: P (a) and P (b). Does this knowledge base entail ∀x P (x)? Explain your answer in terms of models.
8.3 Is the sentence ∃x, y x= y valid? Explain.
8.4 Write down a logical sentence such that every world in which it is true contains exactly one object.
8.5 Consider a symbol vocabulary that contains c constant symbols, P~k~ predicate symbols of each arity k, and fk function symbols of each arity k, where 1 ≤ k ≤ A. Let the domain size be fixed at D. For any given model, each predicate or function symbol is mapped onto a relation or function, respectively, of the same arity. You may assume that the functions in the model allow some input tuples to have no value for the function (i.e., the value is the invisible object). Derive a formula for the number of possible models for a domain with D elements. Don’t worry about eliminating redundant combinations.
8.6 Which of the following are valid (necessarily true) sentences?
a. (∃x x= x) ⇒ (∀ y ∃z y = z).
b. ∀x P (x) ∨ ¬P (x).
c. ∀x Smart(x) ∨ (x= x).
8.7 Consider a version of the semantics for first-order logic in which models with empty domains are allowed. Give at least two examples of sentences that are valid according to the
standard semantics but not according to the new semantics. Discuss which outcome makes more intuitive sense for your examples.
8.8 Does the fact ¬Spouse(George ,Laura) follow from the facts Jim ≠ George and Spouse(Jim,Laura)? If so, give a proof; if not, supply additional axioms as needed. What happens if we use Spouse as a unary function symbol instead of a binary predicate?
8.9 This exercise uses the function MapColor and predicates In(x, y), Borders(x, y), and Country(x), whose arguments are geographical regions, along with constant symbols for various regions. In each of the following we give an English sentence and a number of candidate logical expressions. For each of the logical expressions, state whether it (1) correctly expresses the English sentence; (2) is syntactically invalid and therefore meaningless; or (3) is syntactically valid but does not express the meaning of the English sentence.
a. Paris and Marseilles are both in France.
(i) In(Paris ∧Marseilles,France). (ii) In(Paris ,France) ∧ In(Marseilles,France). (iii) In(Paris ,France) ∨ In(Marseilles,France).
b. There is a country that borders both Iraq and Pakistan.
(i) ∃ c Country(c) ∧ Border(c, Iraq) ∧ Border(c,Pakistan). (ii) ∃ c Country(c) ⇒ [Border (c, Iraq) ∧ Border(c,Pakistan)]. (iii) [∃ c Country(c)] ⇒ [Border (c, Iraq) ∧ Border (c,Pakistan)]. (iv) ∃ c Border (Country(c), Iraq ∧ Pakistan).
c. All countries that border Ecuador are in South America.
(i) ∀ c Country(c) ∧ Border (c,Ecuador ) ⇒ In(c,SouthAmerica). (ii) ∀ c Country(c) ⇒ [Border(c,Ecuador ) ⇒ In(c,SouthAmerica)]. (iii) ∀ c [Country(c) ⇒ Border(c,Ecuador )] ⇒ In(c,SouthAmerica). (iv) ∀ c Country(c) ∧ Border (c,Ecuador ) ∧ In(c,SouthAmerica).
d. No region in South America borders any region in Europe.
(i) ¬[∃ c, d In(c,SouthAmerica) ∧ In(d,Europe) ∧ Borders(c, d)]. (ii) ∀ c, d [In(c,SouthAmerica) ∧ In(d,Europe)] ⇒ ¬Borders(c, d)]. (iii) ¬∀ c In(c,SouthAmerica) ⇒ ∃ d In(d,Europe) ∧ ¬Borders(c, d). (iv) ∀ c In(c,SouthAmerica) ⇒ ∀ d In(d,Europe) ⇒ ¬Borders(c, d).
e. No two adjacent countries have the same map color.
(i) ∀x, y ¬Country(x) ∨ ¬Country(y) ∨ ¬Borders(x, y) ∨ ¬(MapColor (x) = MapColor (y)).
(ii) ∀x, y (Country(x) ∧ Country(y) ∧ Borders(x, y) ∧ ¬(x = y)) ⇒ ¬(MapColor (x) = MapColor (y)).
(iii) ∀x, y Country(x) ∧Country(y) ∧ Borders(x, y) ∧ ¬(MapColor (x) = MapColor (y)).
(iv) ∀x, y (Country(x) ∧ Country(y) ∧ Borders(x, y)) ⇒ MapColor (x ≠ y).
8.10 Consider a vocabulary with the following symbols:
Occupation(p, o): Predicate. Person p has occupation o. Customer(P~1~, p~2~): Predicate. Person P~1~ is a customer of person p~2~. Boss(P~1~, p~2~): Predicate. Person P~1~ is a boss of person p~2~. Doctor , Surgeon , Lawyer , Actor : Constants denoting occupations. Emily , Joe : Constants denoting people.
Use these symbols to write the following assertions in first-order logic:
a. Emily is either a surgeon or a lawyer. b. Joe is an actor, but he also holds another job. c. All surgeons are doctors. d. Joe does not have a lawyer (i.e., is not a customer of any lawyer). e. Emily has a boss who is a lawyer. f. There exists a lawyer all of whose customers are doctors. g. Every surgeon has a lawyer.
8.11 Complete the following exercises about logical senntences:
a. Translate into good, natural English (no xs or ys!):
∀x, y, l SpeaksLanguage(x, l) ∧ SpeaksLanguage(y, l)
⇒ Understands(x, y) ∧ Understands(y, x).
b. Explain why this sentence is entailed by the sentence
∀x, y, l SpeaksLanguage(x, l) ∧ SpeaksLanguage(y, l)
⇒ Understands(x, y).
c. Translate into first-order logic the following sentences:
(i) Understanding leads to friendship. (ii) Friendship is transitive.
Remember to define all predicates, functions, and constants you use.
8.12 Rewrite the first two Peano axioms in Section 8.3.3 as a single axiom that defines NatNum(x) so as to exclude the possibility of natural numbers except for those generated by the successor function.
8.13 Equation (8.4) on page 306 defines the conditions under which a square is breezy. Here we consider two other ways to describe this aspect of the wumpus world.
a. We can write diagnostic rules leading from observed effects to hidden causes. For find-DIAGNOSTIC RULE
ing pits, the obvious diagnostic rules say that if a square is breezy, some adjacent square must contain a pit; and if a square is not breezy, then no adjacent square contains a pit. Write these two rules in first-order logic and show that their conjunction is logically equivalent to Equation (8.4).
b. We can write causal rules leading from cause to effect. One obvious causal rule is that a pit causes all adjacent squares to be breezy. Write this rule in first-order logic, explain why it is incomplete compared to Equation (8.4), and supply the missing axiom.
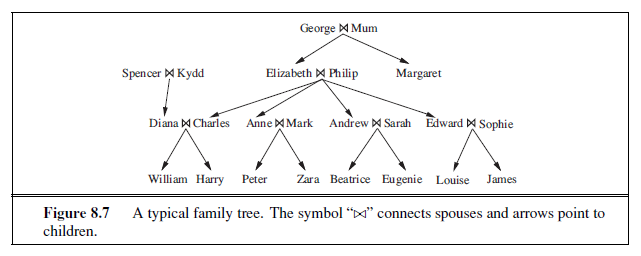
8.14 Write axioms describing the predicates Grandchild , Greatgrandparent , Ancestor , Brother , Sister , Daughter , Son , FirstCousin , BrotherInLaw , SisterInLaw , Aunt , and Uncle. Find out the proper definition of mth cousin n times removed, and write the definition in first-order logic. Now write down the basic facts depicted in the family tree in Figure 8.7. Using a suitable logical reasoning system, TELL it all the sentences you have written down, and ASK it who are Elizabeth’s grandchildren, Diana’s brothers-in-law, Zara’s great-grandparents, and Eugenie’s ancestors.
8.15 Explain what is wrong with the following proposed definition of the set membership predicate ∈ :
∀ x, s x ∈{x|s}
∀ x, s x ∈ s ⇒ ∀ y x ∈{y|s} .
8.16 Using the set axioms as examples, write axioms for the list domain, including all the constants, functions, and predicates mentioned in the chapter.
8.17 Explain what is wrong with the following proposed definition of adjacent squares in the wumpus world:
∀ x, y Adjacent([x, y], [x + 1, y]) ∧ Adjacent([x, y], [x, y + 1]) .
8.18 Write out the axioms required for reasoning about the wumpus’s location, using a constant symbol Wumpus and a binary predicate At(Wumpus ,Location). Remember that there is only one wumpus.
8.19 Assuming predicates Parent(p, q) and Female(p) and constants Joan and Kevin, with the obvious meanings, express each of the following sentences in first-order logic. (You may use the abbreviation ∃1 to mean “there exists exactly one.”)
a. Joan has a daughter (possibly more than one, and possibly sons as well).
b. Joan has exactly one daughter (but may have sons as well).
c. Joan has exactly one child, a daughter.
d. Joan and Kevin have exactly one child together.
e. Joan has at least one child with Kevin, and no children with anyone else.
8.20 Arithmetic assertions can be written in first-order logic with the predicate symbol <, the function symbols + and ×, and the constant symbols 0 and 1. Additional predicates can also be defined with biconditionals.
a. Represent the property “x is an even number.”
b. Represent the property “x is prime.”
c. Goldbach’s conjecture is the conjecture (unproven as yet) that every even number is equal to the sum of two primes. Represent this conjecture as a logical sentence.
8.21 In Chapter 6, we used equality to indicate the relation between a variable and its value. For instance, we wrote WA= red to mean that Western Australia is colored red. Representing this in first-order logic, we must write more verbosely ColorOf (WA)= red . What incorrect inference could be drawn if we wrote sentences such as WA= red directly as logical assertions?
8.22 Write in first-order logic the assertion that every key and at least one of every pair of socks will eventually be lost forever, using only the following vocabulary: Key(x), x is a key; Sock(x), x is a sock; Pair(x, y), x and y are a pair; Now , the current time; Before(t~1~, t~2~), time t~1~ comes before time t~2~; Lost(x, t), object x is lost at time t.
8.23 For each of the following sentences in English, decide if the accompanying first-order logic sentence is a good translation. If not, explain why not and correct it. (Some sentences may have more than one error!)
a. No two people have the same social security number.
¬∃x, y, n Person(x) ∧ Person(y) ⇒ [HasSS#(x, n) ∧ HasSS#(y, n)].
b. John’s social security number is the same as Mary’s.
∃n HasSS#(John , n) ∧ HasSS#(Mary , n).
c. Everyone’s social security number has nine digits.
∀x, n Person(x) ⇒ [HasSS#(x, n) ∧ Digits(n, 9)].
d. Rewrite each of the above (uncorrected) sentences using a function symbol SS# instead of the predicate HasSS#.
8.24 Represent the following sentences in first-order logic, using a consistent vocabulary (which you must define):
a. Some students took French in spring 2001.
b. Every student who takes French passes it.
c. Only one student took Greek in spring 2001.
d. The best score in Greek is always higher than the best score in French.
e. Every person who buys a policy is smart.
f. No person buys an expensive policy.
g. There is an agent who sells policies only to people who are not insured.
h. There is a barber who shaves all men in town who do not shave themselves.
i. A person born in the UK, each of whose parents is a UK citizen or a UK resident, is a UK citizen by birth.
j. A person born outside the UK, one of whose parents is a UK citizen by birth, is a UK citizen by descent.
k. Politicians can fool some of the people all of the time, and they can fool all of the people some of the time, but they can’t fool all of the people all of the time.
l. All Greeks speak the same language. (Use Speaks(x, l) to mean that person x speaks language l.)
8.25 Write a general set of facts and axioms to represent the assertion “Wellington heard about Napoleon’s death” and to correctly answer the question “Did Napoleon hear about Wellington’s death?”
8.26 Extend the vocabulary from Section 8.4 to define addition for n-bit binary numbers. Then encode the description of the four-bit adder in Figure 8.8, and pose the queries needed to verify that it is in fact correct.
8.27 Obtain a passport application for your country, identify the rules determining eligibility for a passport, and translate them into first-order logic, following the steps outlined in Section 8.4.
8.28 Consider a first-order logical knowledge base that describes worlds containing people, songs, albums (e.g., “Meet the Beatles”) and disks (i.e., particular physical instances of CDs). The vocabulary contains the following symbols:
CopyOf (d, a): Predicate. Disk d is a copy of album a. Owns(p, d): Predicate. Person p owns disk d. Sings(p, s, a): Album a includes a recording of song s sung by person p. Wrote(p, s): Person p wrote song s. McCartney , Gershwin , BHoliday , Joe , EleanorRigby , TheManILove , Revolver : Constants with the obvious meanings.
Express the following statements in first-order logic:
a. Gershwin wrote “The Man I Love.”
b. Gershwin did not write “Eleanor Rigby.”
c. Either Gershwin or McCartney wrote “The Man I Love.”
d. Joe has written at least one song.
e. Joe owns a copy of Revolver.
f. Every song that McCartney sings on Revolver was written by McCartney.
g. Gershwin did not write any of the songs on Revolver.
h. Every song that Gershwin wrote has been recorded on some album. (Possibly different songs are recorded on different albums.)
i. There is a single album that contains every song that Joe has written.
j. Joe owns a copy of an album that has Billie Holiday singing “The Man I Love.”
k. Joe owns a copy of every album that has a song sung by McCartney. (Of course, each different album is instantiated in a different physical CD.)
l. Joe owns a copy of every album on which all the songs are sung by Billie Holiday.
INFERENCE IN FIRST-ORDER LOGIC
In which we define effective procedures for answering questions posed in firstorder logic.
Chapter 7 showed how sound and complete inference can be achieved for propositional logic. In this chapter, we extend those results to obtain algorithms that can answer any answerable question stated in first-order logic. Section 9.1 introduces inference rules for quantifiers and shows how to reduce first-order inference to propositional inference, albeit at potentially great expense. Section 9.2 describes the idea of unification, showing how it can be used to construct inference rules that work directly with first-order sentences. We then discuss three major families of first-order inference algorithms. Forward chaining and its applications to deductive databases and production systems are covered in Section 9.3; backward chaining and logic programming systems are developed in Section 9.4. Forward and backward chaining can be very efficient, but are applicable only to knowledge bases that can be expressed as sets of Horn clauses. General first-order sentences require resolution-based theorem proving, which is described in Section 9.5.
PROPOSITIONAL VS. FIRST-ORDER INFERENCE
This section and the next introduce the ideas underlying modern logical inference systems. We begin with some simple inference rules that can be applied to sentences with quantifiers to obtain sentences without quantifiers. These rules lead naturally to the idea that first-order inference can be done by converting the knowledge base to propositional logic and using propositional inference, which we already know how to do. The next section points out an obvious shortcut, leading to inference methods that manipulate first-order sentences directly.
Inference rules for quantifiers
Let us begin with universal quantifiers. Suppose our knowledge base contains the standard folkloric axiom stating that all greedy kings are evil:
∀x King(x) ∧Greedy(x) ⇒ Evil(x) .
Then it seems quite permissible to infer any of the following sentences:
King(John) ∧ Greedy(John) ⇒ Evil(John)
King(Richard ) ∧ Greedy(Richard) ⇒ Evil(Richard)
King(Father (John)) ∧ Greedy(Father (John)) ⇒ Evil(Father (John)) . . . .
The rule of Universal Instantiation (UI for short) says that we can infer any sentence obtained by substituting a ground term (a term without variables) for the variable.1 To write out the inference rule formally, we use the notion of substitutions introduced in Section 8.3. Let SUBST(θ, α) denote the result of applying the substitution θ to the sentence α. Then the rule is written
∀ v α / SUBST({v/g}, α)
for any variable v and ground term g. For example, the three sentences given earlier are obtained with the substitutions {x/John}, {x/Richard}, and {x/Father (John)}.
In the rule for Existential Instantiation, the variable is replaced by a single new constant symbol. The formal statement is as follows: for any sentence α, variable v, and constant symbol k that does not appear elsewhere in the knowledge base,
∃ v α / SUBST({v/k}, α) .
For example, from the sentence
∃x Crown(x) ∧ OnHead(x, John)
we can infer the sentence
Crown(C~1~) ∧ OnHead(C~1~, John)
as long as C~1~ does not appear elsewhere in the knowledge base. Basically, the existential sentence says there is some object satisfying a condition, and applying the existential instantiation rule just gives a name to that object. Of course, that name must not already belong to another object. Mathematics provides a nice example: suppose we discover that there is a number that is a little bigger than 2.71828 and that satisfies the equation d(x^y^)/dy = x^y^ for x. We can give this number a name, such as e, but it would be a mistake to give it the name of an existing object, such as π. In logic, the new name is called a Skolem constant. Existential Instantiation is a special case of a more general process called skolemization, which we cover in Section 9.5.
Whereas Universal Instantiation can be applied many times to produce many different consequences, Existential Instantiation can be applied once, and then the existentially quantified sentence can be discarded. For example, we no longer need ∃x Kill(x,Victim) once we have added the sentence Kill(Murderer ,Victim). Strictly speaking, the new knowledge base is not logically equivalent to the old, but it can be shown to be inferentially equivalent in the sense that it is satisfiable exactly when the original knowledge base is satisfiable.
1 Do not confuse these substitutions with the extended interpretations used to define the semantics of quantifiers. The substitution replaces a variable with a term (a piece of syntax) to produce a new sentence, whereas an interpretation maps a variable to an object in the domain.
Reduction to propositional inference
Once we have rules for inferring nonquantified sentences from quantified sentences, it becomes possible to reduce first-order inference to propositional inference. In this section we give the main ideas; the details are given in Section 9.5.
The first idea is that, just as an existentially quantified sentence can be replaced by one instantiation, a universally quantified sentence can be replaced by the set of all possible instantiations. For example, suppose our knowledge base contains just the sentences
∀ x King(x) ∧ Greedy(x) ⇒ Evil(x)
King(John)
Greedy(John)
Brother (Richard , John) . (9.1)
Then we apply UI to the first sentence using all possible ground-term substitutions from the vocabulary of the knowledge base—in this case, {x/John} and {x/Richard}. We obtain
King(John) ∧ Greedy(John) ⇒ Evil(John)
King(Richard ) ∧ Greedy(Richard) ⇒ Evil(Richard) ,
and we discard the universally quantified sentence. Now, the knowledge base is essentially propositional if we view the ground atomic sentences—King (John), Greedy(John), and so on—as proposition symbols. Therefore, we can apply any of the complete propositional algorithms in Chapter 7 to obtain conclusions such as Evil(John).
This technique of propositionalization can be made completely general, as we show in Section 9.5; that is, every first-order knowledge base and query can be propositionalized in such a way that entailment is preserved. Thus, we have a complete decision procedure for entailment . . . or perhaps not. There is a problem: when the knowledge base includes a function symbol, the set of possible ground-term substitutions is infinite! For example, if the knowledge base mentions the Father symbol, then infinitely many nested terms such as Father (Father (Father (John))) can be constructed. Our propositional algorithms will have difficulty with an infinitely large set of sentences.
Fortunately, there is a famous theorem due to Jacques Herbrand (1930) to the effect that if a sentence is entailed by the original, first-order knowledge base, then there is a proof involving just a finite subset of the propositionalized knowledge base. Since any such subset has a maximum depth of nesting among its ground terms, we can find the subset by first generating all the instantiations with constant symbols (Richard and John), then all terms of depth 1 (Father (Richard ) and Father (John)), then all terms of depth 2, and so on, until we are able to construct a propositional proof of the entailed sentence.
We have sketched an approach to first-order inference via propositionalization that is complete—that is, any entailed sentence can be proved. This is a major achievement, given that the space of possible models is infinite. On the other hand, we do not know until the proof is done that the sentence is entailed! What happens when the sentence is not entailed? Can we tell? Well, for first-order logic, it turns out that we cannot. Our proof procedure can go on and on, generating more and more deeply nested terms, but we will not know whether it is stuck in a hopeless loop or whether the proof is just about to pop out. This is very much like the halting problem for Turing machines. Alan Turing (1936) and Alonzo Church (1936) both proved, in rather different ways, the inevitability of this state of affairs. The question of entailment for first-order logic is semidecidable—that is, algorithms exist that say yes to every entailed sentence, but no algorithm exists that also says no to every nonentailed sentence.
UNIFICATION AND LIFTING
The preceding section described the understanding of first-order inference that existed up to the early 1960s. The sharp-eyed reader (and certainly the computational logicians of the early 1960s) will have noticed that the propositionalization approach is rather inefficient. For example, given the query Evil(x) and the knowledge base in Equation (9.1), it seems perverse to generate sentences such as King(Richard ) ∧Greedy(Richard) ⇒ Evil(Richard ). Indeed, the inference of Evil(John) from the sentences
∀ x King(x) ∧Greedy(x) ⇒ Evil(x)
King(John)
Greedy(John)
seems completely obvious to a human being. We now show how to make it completely obvious to a computer.
A first-order inference rule
The inference that John is evil—that is, that {x/John} solves the query Evil(x)—works like this: to use the rule that greedy kings are evil, find some x such that x is a king and x is greedy, and then infer that this x is evil. More generally, if there is some substitution θ that makes each of the conjuncts of the premise of the implication identical to sentences already in the knowledge base, then we can assert the conclusion of the implication, after applying θ. In this case, the substitution θ = {x/John} achieves that aim.
We can actually make the inference step do even more work. Suppose that instead of knowing Greedy(John), we know that everyone is greedy:
∀ y Greedy(y) . (9.2)
Then we would still like to be able to conclude that Evil(John), because we know that John is a king (given) and John is greedy (because everyone is greedy). What we need for this to work is to find a substitution both for the variables in the implication sentence and for the variables in the sentences that are in the knowledge base. In this case, applying the substitution {x/John , y/John} to the implication premises King(x) and Greedy(x) and the knowledge-base sentences King(John) and Greedy(y) will make them identical. Thus, we can infer the conclusion of the implication.
This inference process can be captured as a single inference rule that we call Generalized Modus Ponens:2 For atomic sentences p~i~, p~i~′, and q, where there is a substitution θ GENERALIZED MODUS PONENS
such that SUBST(θ, p~i~ ′)= SUBST(θ, p~i~), for all i,
P~1~ ′, p~2~ ′, . . . , p~n~ ′, (P~1~ ∧ p~2~ ∧ . . . ∧ p~n~ ⇒ q)
/
SUBST(θ, q) .
There are n+1 premises to this rule: the n atomic sentences p~i~ ′ and the one implication. The
conclusion is the result of applying the substitution θ to the consequent q. For our example:
P~1~′ is King(John) P~1~ is King(x)
p~2~′ is Greedy(y) p~2~ is Greedy(x)
θ is {x/John , y/John} q is Evil(x)
SUBST(θ, q) is Evil(John) .
It is easy to show that Generalized Modus Ponens is a sound inference rule. First, we observe that, for any sentence p (whose variables are assumed to be universally quantified) and for any substitution θ,
p |= SUBST(θ, p)
holds by Universal Instantiation. It holds in particular for a θ that satisfies the conditions of the Generalized Modus Ponens rule. Thus, from P~1~′, . . . , p~n~ ′ we can infer
SUBST(θ, P~1~′) ∧ . . . ∧ SUBST(θ, p~n~′)
and from the implication P~1~ ∧ . . . ∧ p~n~ ⇒ q we can infer
SUBST(θ, P~1~) ∧ . . . ∧ SUBST(θ, p~n~) ⇒ SUBST(θ, q) .
Now, θ in Generalized Modus Ponens is defined so that SUBST(θ, p~i~ ′)= SUBST(θ, p~i~), for all i; therefore the first of these two sentences matches the premise of the second exactly. Hence, SUBST(θ, q) follows by Modus Ponens.
Generalized Modus Ponens is a lifted version of Modus Ponens—it raises Modus Ponens from ground (variable-free) propositional logic to first-order logic. We will see in the rest of this chapter that we can develop lifted versions of the forward chaining, backward chaining, and resolution algorithms introduced in Chapter 7. The key advantage of lifted inference rules over propositionalization is that they make only those substitutions that are required to allow particular inferences to proceed.
Unification
Lifted inference rules require finding substitutions that make different logical expressions look identical. This process is called unification and is a key component of all first-order inference algorithms. The UNIFY algorithm takes two sentences and returns a unifier for them if one exists:
UNIFY(p, q)= θ where SUBST(θ, p)= SUBST(θ, q) .
Let us look at some examples of how UNIFY should behave. Suppose we have a query AskVars(Knows(John , x)): whom does John know? Answers to this query can be found
2 Generalized Modus Ponens is more general than Modus Ponens (page 249) in the sense that the known facts and the premise of the implication need match only up to a substitution, rather than exactly. On the other hand, Modus Ponens allows any sentence α as the premise, rather than just a conjunction of atomic sentences.
by finding all sentences in the knowledge base that unify with Knows(John , x). Here are the results of unification with four different sentences that might be in the knowledge base:
UNIFY(Knows(John , x), Knows(John , Jane)) = {x/Jane}
UNIFY(Knows(John , x), Knows(y,Bill)) = {x/Bill , y/John}
UNIFY(Knows(John , x), Knows(y,Mother (y))) = {y/John , x/Mother (John)}
UNIFY(Knows(John , x), Knows(x,Elizabeth)) = fail .
The last unification fails because x cannot take on the values John and Elizabeth at the same time. Now, remember that Knows(x,Elizabeth) means “Everyone knows Elizabeth,” so we should be able to infer that John knows Elizabeth. The problem arises only because the two sentences happen to use the same variable name, x. The problem can be avoided by standardizing apart one of the two sentences being unified, which means renaming it variables to avoid name clashes. For example, we can rename x in Knows(x,Elizabeth) to X~1~7 (a new variable name) without changing its meaning. Now the unification will work:
UNIFY(Knows(John , x), Knows(X~17~,Elizabeth)) = {x/Elizabeth , X~17~/John} .
Exercise 9.12 delves further into the need for standardizing apart.
There is one more complication: we said that UNIFY should return a substitution that makes the two arguments look the same. But there could be more than one such unifier. For example, UNIFY(Knows(John , x),Knows(y, z)) could return {y/John , x/z} or {y/John , x/John , z/John}. The first unifier gives Knows(John , z) as the result of unification, whereas the second gives Knows(John , John). The second result could be obtained from the first by an additional substitution {z/John}; we say that the first unifier is more general than the second, because it places fewer restrictions on the values of the variables. It turns out that, for every unifiable pair of expressions, there is a single most general unifier (or MGU) that is unique up to renaming and substitution of variables. (For example, {x/John} and {y/John} are considered equivalent, as are {x/John , y/John} and {x/John , y/x}.) In this case it is {y/John , x/z}.
An algorithm for computing most general unifiers is shown in Figure 9.1. The process is simple: recursively explore the two expressions simultaneously “side by side,” building up a unifier along the way, but failing if two corresponding points in the structures do not match. There is one expensive step: when matching a variable against a complex term, one must check whether the variable itself occurs inside the term; if it does, the match fails because no consistent unifier can be constructed. For example, S(x) can’t unify with S(S(x)). This socalled occur check makes the complexity of the entire algorithm quadratic in the size of the expressions being unified. Some systems, including all logic programming systems, simply omit the occur check and sometimes make unsound inferences as a result; other systems use more complex algorithms with linear-time complexity.
Storage and retrieval
Underlying the TELL and ASK functions used to inform and interrogate a knowledge base are the more primitive STORE and FETCH functions. STORE(s) stores a sentence s into the knowledge base and FETCH(q) returns all unifiers such that the query q unifies with some
function UNIFY(x , y , θ) returns a substitution to make x and y identical inputs: x , a variable, constant, list, or compound expression y , a variable, constant, list, or compound expression θ, the substitution built up so far (optional, defaults to empty)
if θ = failure then return failure else if x = y then return θ else if VARIABLE?(x ) then return UNIFY-VAR(x , y , θ) else if VARIABLE?(y) then return UNIFY-VAR(y , x , θ) else if COMPOUND?(x ) and COMPOUND?(y) then
return UNIFY(x .ARGS, y .ARGS, UNIFY(x .OP, y .OP, θ)) else if LIST?(x ) and LIST?(y) then
return UNIFY(x .REST, y .REST, UNIFY(x .FIRST, y .FIRST, θ)) else return failure
function UNIFY-VAR(var , x , θ) returns a substitution
if {var/val} ∈ θ then return UNIFY(val , x , θ) else if {x/val} ∈ θ then return UNIFY(var , val , θ) else if OCCUR-CHECK?(var , x ) then return failure else return add {var /x} to θ
Figure 9.1 The unification algorithm. The algorithm works by comparing the structures of the inputs, element by element. The substitution θ that is the argument to UNIFY is built up along the way and is used to make sure that later comparisons are consistent with bindings that were established earlier. In a compound expression such as F (A, B), the OP field picks out the function symbol F and the ARGS field picks out the argument list (A, B).
sentence in the knowledge base. The problem we used to illustrate unification—finding all facts that unify with Knows(John , x)—is an instance of FETCHing.
The simplest way to implement STORE and FETCH is to keep all the facts in one long list and unify each query against every element of the list. Such a process is inefficient, but it works, and it’s all you need to understand the rest of the chapter. The remainder of this section outlines ways to make retrieval more efficient; it can be skipped on first reading.
We can make FETCH more efficient by ensuring that unifications are attempted only with sentences that have some chance of unifying. For example, there is no point in trying to unify Knows(John , x) with Brother (Richard , John). We can avoid such unifications by indexing the facts in the knowledge base. A simple scheme called predicate indexing puts all the Knows facts in one bucket and all the Brother facts in another. The buckets can be stored in a hash table for efficient access.
Predicate indexing is useful when there are many predicate symbols but only a few clauses for each symbol. Sometimes, however, a predicate has many clauses. For example, suppose that the tax authorities want to keep track of who employs whom, using a predicate Employs(x, y). This would be a very large bucket with perhaps millions of employers

and tens of millions of employees. Answering a query such as Employs(x,Richard ) with predicate indexing would require scanning the entire bucket.
For this particular query, it would help if facts were indexed both by predicate and by second argument, perhaps using a combined hash table key. Then we could simply construct the key from the query and retrieve exactly those facts that unify with the query. For other queries, such as Employs(IBM , y), we would need to have indexed the facts by combining the predicate with the first argument. Therefore, facts can be stored under multiple index keys, rendering them instantly accessible to various queries that they might unify with.
Given a sentence to be stored, it is possible to construct indices for all possible queries that unify with it. For the fact Employs(IBM ,Richard), the queries are
Employs(IBM ,Richard) Does IBM employ Richard? Employs(x,Richard ) Who employs Richard? Employs(IBM , y) Whom does IBM employ? Employs(x, y) Who employs whom?
These queries form a subsumption lattice, as shown in Figure 9.2(a). The lattice has some interesting properties. For example, the child of any node in the lattice is obtained from its parent by a single substitution; and the “highest” common descendant of any two nodes is the result of applying their most general unifier. The portion of the lattice above any ground fact can be constructed systematically (Exercise 9.5). A sentence with repeated constants has a slightly different lattice, as shown in Figure 9.2(b). Function symbols and variables in the sentences to be stored introduce still more interesting lattice structures.
The scheme we have described works very well whenever the lattice contains a small number of nodes. For a predicate with n arguments, however, the lattice contains O(2^n^) nodes. If function symbols are allowed, the number of nodes is also exponential in the size of the terms in the sentence to be stored. This can lead to a huge number of indices. At some point, the benefits of indexing are outweighed by the costs of storing and maintaining all the indices. We can respond by adopting a fixed policy, such as maintaining indices only on keys composed of a predicate plus each argument, or by using an adaptive policy that creates indices to meet the demands of the kinds of queries being asked. For most AI systems, the number of facts to be stored is small enough that efficient indexing is considered a solved problem. For commercial databases, where facts number in the billions, the problem has been the subject of intensive study and technology development..
FORWARD CHAINING
A forward-chaining algorithm for propositional definite clauses was given in Section 7.5. The idea is simple: start with the atomic sentences in the knowledge base and apply Modus Ponens in the forward direction, adding new atomic sentences, until no further inferences can be made. Here, we explain how the algorithm is applied to first-order definite clauses. Definite clauses such as Situation ⇒ Response are especially useful for systems that make inferences in response to newly arrived information. Many systems can be defined this way, and forward chaining can be implemented very efficiently.
First-order definite clauses
First-order definite clauses closely resemble propositional definite clauses (page 256): they are disjunctions of literals of which exactly one is positive. A definite clause either is atomic or is an implication whose antecedent is a conjunction of positive literals and whose consequent is a single positive literal. The following are first-order definite clauses:
King(x) ∧ Greedy(x) ⇒ Evil(x) .
King(John) .
Greedy(y) .
Unlike propositional literals, first-order literals can include variables, in which case those variables are assumed to be universally quantified. (Typically, we omit universal quantifiers when writing definite clauses.) Not every knowledge base can be converted into a set of definite clauses because of the single-positive-literal restriction, but many can. Consider the following problem:
The law says that it is a crime for an American to sell weapons to hostile nations. The country Nono, an enemy of America, has some missiles, and all of its missiles were sold to it by Colonel West, who is American.
We will prove that West is a criminal. First, we will represent these facts as first-order definite clauses. The next section shows how the forward-chaining algorithm solves the problem.
“. . . it is a crime for an American to sell weapons to hostile nations”:
American(x) ∧Weapon(y) ∧ Sells(x, y, z) ∧ Hostile(z) ⇒ Criminal(x) . (9.3)
“Nono . . . has some missiles.” The sentence ∃x Owns(Nono, x)∧ Missile(x) is transformed into two definite clauses by Existential Instantiation, introducing a new constant M~1~:
Owns(Nono,M~1~) (9.4)
Missile(M~1~). (9.5)
“All of its missiles were sold to it by Colonel West”:
Missile(x) ∧ Owns(Nono, x) ⇒ Sells(West , x,Nono) . (9.6)
We will also need to know that missiles are weapons:
Missile(x) ⇒Weapon(x) (9.7)
and we must know that an enemy of America counts as “hostile”:
Enemy(x,America) ⇒ Hostile(x) . (9.8)
“West, who is American . . .”:
American(West) . (9.9)
“The country Nono, an enemy of America . . .”:
Enemy(Nono,America) . (9.10)
This knowledge base contains no function symbols and is therefore an instance of the class of Datalog knowledge bases. Datalog is a language that is restricted to first-order definite clauses with no function symbols. Datalog gets its name because it can represent the type of statements typically made in relational databases. We will see that the absence of function symbols makes inference much easier.
A simple forward-chaining algorithm
The first forward-chaining algorithm we consider is a simple one, shown in Figure 9.3. Starting from the known facts, it triggers all the rules whose premises are satisfied, adding their conclusions to the known facts. The process repeats until the query is answered (assuming that just one answer is required) or no new facts are added. Notice that a fact is not “new” if it is just a renaming of a known fact. One sentence is a renaming of another if they are identical except for the names of the variables. For example, Likes(x, IceCream) and Likes(y, IceCream) are renamings of each other because they differ only in the choice of x or y; their meanings are identical: everyone likes ice cream.
We use our crime problem to illustrate how FOL-FC-ASK works. The implication sentences are (9.3), (9.6), (9.7), and (9.8). Two iterations are required:
-
On the first iteration, rule (9.3) has unsatisfied premises. Rule (9.6) is satisfied with {x/M~1~}, and Sells(West ,M~1~,Nono) is added. Rule (9.7) is satisfied with {x/M~1~}, and Weapon(M~1~) is added. Rule (9.8) is satisfied with {x/Nono}, and Hostile(Nono) is added.
-
On the second iteration, rule (9.3) is satisfied with {x/West , y/M~1,z~/Nono}, and Criminal(West) is added.
Figure 9.4 shows the proof tree that is generated. Notice that no new inferences are possible at this point because every sentence that could be concluded by forward chaining is already contained explicitly in the KB. Such a knowledge base is called a fixed point of the inference process. Fixed points reached by forward chaining with first-order definite clauses are similar to those for propositional forward chaining (page 258); the principal difference is that a first- order fixed point can include universally quantified atomic sentences.
FOL-FC-ASK is easy to analyze. First, it is sound, because every inference is just an application of Generalized Modus Ponens, which is sound. Second, it is complete for definite clause knowledge bases; that is, it answers every query whose answers are entailed by any knowledge base of definite clauses. For Datalog knowledge bases, which contain no function symbols, the proof of completeness is fairly easy. We begin by counting the number of
function FOL-FC-ASK(KB , α) returns a substitution or false
inputs: KB , the knowledge base, a set of first-order definite clauses α, the query, an atomic sentence
local variables: new , the new sentences inferred on each iteration
repeat until new is empty new←{} for each rule in KB do (P~1~ ∧ . . . ∧ p~n~ ⇒ q)← STANDARDIZE-VARIABLES(rule) for each θ such that SUBST(θ,P~1~ ∧ . . . ∧ p~n~) = SUBST(θ,p~1~ ∧ . . . ∧ p′~n~)
for some p′~1~ , . . . , p′~n~ in KB
q ′← SUBST(θ, q) if q ′ does not unify with some sentence already in KB or new then
add q ′ to new φ←UNIFY(q ′, α) if φ is not fail then return φ
add new to KB return false
Figure 9.3 A conceptually straightforward, but very inefficient, forward-chaining algorithm. On each iteration, it adds to KB all the atomic sentences that can be inferred in one step from the implication sentences and the atomic sentences already in KB . The function STANDARDIZE-VARIABLES replaces all variables in its arguments with new ones that have not been used before.
possible facts that can be added, which determines the maximum number of iterations. Let k be the maximum arity (number of arguments) of any predicate, p be the number of predicates, and n be the number of constant symbols. Clearly, there can be no more than pn^k^ distinct ground facts, so after this many iterations the algorithm must have reached a fixed point. Then we can make an argument very similar to the proof of completeness for propositional forward chaining. (See page 258.) The details of how to make the transition from propositional to first-order completeness are given for the resolution algorithm in Section 9.5.
For general definite clauses with function symbols, FOL-FC-ASK can generate infinitely many new facts, so we need to be more careful. For the case in which an answer to the query sentence q is entailed, we must appeal to Herbrand’s theorem to establish that the algorithm will find a proof. (See Section 9.5 for the resolution case.) If the query has no answer, the algorithm could fail to terminate in some cases. For example, if the knowledge base includes the Peano axioms
NatNum(0)
∀n NatNum(n) ⇒ NatNum(S(n)) ,
then forward chaining adds NatNum(S(0)), NatNum(S(S(0))), NatNum(S(S(S(0)))), and so on. This problem is unavoidable in general. As with general first-order logic, entailment with definite clauses is semidecidable.
Efficient forward chaining
The forward-chaining algorithm in Figure 9.3 is designed for ease of understanding rather than for efficiency of operation. There are three possible sources of inefficiency. First, the “inner loop” of the algorithm involves finding all possible unifiers such that the premise of a rule unifies with a suitable set of facts in the knowledge base. This is often called pattern matching and can be very expensive. Second, the algorithm rechecks every rule on every iteration to see whether its premises are satisfied, even if very few additions are made to the knowledge base on each iteration. Finally, the algorithm might generate many facts that are irrelevant to the goal. We address each of these issues in turn.
Matching rules against known facts
The problem of matching the premise of a rule against the facts in the knowledge base might seem simple enough. For example, suppose we want to apply the rule
Missile(x) ⇒Weapon(x) .
Then we need to find all the facts that unify with Missile(x); in a suitably indexed knowledge base, this can be done in constant time per fact. Now consider a rule such as
Missile(x) ∧Owns(Nono, x) ⇒ Sells(West , x,Nono) .
Again, we can find all the objects owned by Nono in constant time per object; then, for each object, we could check whether it is a missile. If the knowledge base contains many objects owned by Nono and very few missiles, however, it would be better to find all the missiles first and then check whether they are owned by Nono. This is the conjunct ordering problem: find an ordering to solve the conjuncts of the rule premise so that the total cost is minimized. It turns out that finding the optimal ordering is NP-hard, but good heuristics are available. For example, the minimum-remaining-values (MRV) heuristic used for CSPs in Chapter 6 would suggest ordering the conjuncts to look for missiles first if fewer missiles than objects are owned by Nono.
The connection between pattern matching and constraint satisfaction is actually very close. We can view each conjunct as a constraint on the variables that it contains—for example, Missile(x) is a unary constraint on x. Extending this idea, we can express every finite-domain CSP as a single definite clause together with some associated ground facts. Consider the map-coloring problem from Figure 6.1, shown again in Figure 9.5(a). An equivalent formulation as a single definite clause is given in Figure 9.5(b). Clearly, the conclusion Colorable() can be inferred only if the CSP has a solution. Because CSPs in general include 3-SAT problems as special cases, we can conclude that matching a definite clause against a set of facts is NP-hard.
It might seem rather depressing that forward chaining has an NP-hard matching problem in its inner loop. There are three ways to cheer ourselves up:
-
We can remind ourselves that most rules in real-world knowledge bases are small and simple (like the rules in our crime example) rather than large and complex (like the CSP formulation in Figure 9.5). It is common in the database world to assume that both the sizes of rules and the arities of predicates are bounded by a constant and to worry only about data complexity—that is, the complexity of inference as a function of the number of ground facts in the knowledge base. It is easy to show that the data complexity of forward chaining is polynomial.
-
We can consider subclasses of rules for which matching is efficient. Essentially every Datalog clause can be viewed as defining a CSP, so matching will be tractable just when the corresponding CSP is tractable. Chapter 6 describes several tractable families of CSPs. For example, if the constraint graph (the graph whose nodes are variables and whose links are constraints) forms a tree, then the CSP can be solved in linear time. Exactly the same result holds for rule matching. For instance, if we remove South Australia from the map in Figure 9.5, the resulting clause is
Diff (wa ,nt) ∧Diff (nt , q) ∧Diff (q,nsw) ∧Diff (nsw , v) ⇒ Colorable()
which corresponds to the reduced CSP shown in Figure 6.12 on page 224. Algorithms for solving tree-structured CSPs can be applied directly to the problem of rule matching.
- We can try to to eliminate redundant rule-matching attempts in the forward-chaining algorithm, as described next.
Incremental forward chaining
When we showed how forward chaining works on the crime example, we cheated; in particular, we omitted some of the rule matching done by the algorithm shown in Figure 9.3. For example, on the second iteration, the rule
Missile(x) ⇒Weapon(x)
matches against Missile(M~1~) (again), and of course the conclusion Weapon(M~1~) is already known so nothing happens. Such redundant rule matching can be avoided if we make the following observation: Every new fact inferred on iteration t must be derived from at least one new fact inferred on iteration t − 1_._ This is true because any inference that does not require a new fact from iteration t− 1 could have been done at iteration t− 1 already.
This observation leads naturally to an incremental forward-chaining algorithm where, at iteration t, we check a rule only if its premise includes a conjunct p~i~ that unifies with a fact p ′~i~ newly inferred at iteration t − 1. The rule-matching step then fixes p~i~ to match with p ′~i~, but allows the other conjuncts of the rule to match with facts from any previous iteration. This algorithm generates exactly the same facts at each iteration as the algorithm in Figure 9.3, but is much more efficient.
With suitable indexing, it is easy to identify all the rules that can be triggered by any given fact, and indeed many real systems operate in an “update” mode wherein forward chaining occurs in response to each new fact that is TELLed to the system. Inferences cascade through the set of rules until the fixed point is reached, and then the process begins again for the next new fact.
Typically, only a small fraction of the rules in the knowledge base are actually triggered by the addition of a given fact. This means that a great deal of redundant work is done in repeatedly constructing partial matches that have some unsatisfied premises. Our crime example is rather too small to show this effectively, but notice that a partial match is constructed on the first iteration between the rule
American(x) ∧Weapon(y) ∧ Sells(x, y, z) ∧ Hostile(z) ⇒ Criminal(x)
and the fact American(West). This partial match is then discarded and rebuilt on the second iteration (when the rule succeeds). It would be better to retain and gradually complete the partial matches as new facts arrive, rather than discarding them.
The rete algorithm3 was the first to address this problem. The algorithm preprocesses the set of rules in the knowledge base to construct a sort of dataflow network in which each
3 Rete is Latin for net. The English pronunciation rhymes with treaty.
node is a literal from a rule premise. Variable bindings flow through the network and are filtered out when they fail to match a literal. If two literals in a rule share a variable—for example, Sells(x, y, z) ∧ Hostile(z) in the crime example—then the bindings from each literal are filtered through an equality node. A variable binding reaching a node for an nary literal such as Sells(x, y, z) might have to wait for bindings for the other variables to be established before the process can continue. At any given point, the state of a rete network captures all the partial matches of the rules, avoiding a great deal of recomputation.
Rete networks, and various improvements thereon, have been a key component of socalled production systems, which were among the earliest forward-chaining systems in widespread use.4 The XCON system (originally called R~1~; McDermott, 1982) was built with a production-system architecture. XCON contained several thousand rules for designing configurations of computer components for customers of the Digital Equipment Corporation. It was one of the first clear commercial successes in the emerging field of expert systems. Many other similar systems have been built with the same underlying technology, which has been implemented in the general-purpose language OPS-5.
Production systems are also popular in cognitive architectures—that is, models of human reasoning—such as ACT (Anderson, 1983) and SOAR (Laird et al., 1987). In such systems, the “working memory” of the system models human short-term memory, and the productions are part of long-term memory. On each cycle of operation, productions are matched against the working memory of facts. A production whose conditions are satisfied can add or delete facts in working memory. In contrast to the typical situation in databases, production systems often have many rules and relatively few facts. With suitably optimized matching technology, some modern systems can operate in real time with tens of millions of rules.
Irrelevant facts
The final source of inefficiency in forward chaining appears to be intrinsic to the approach and also arises in the propositional context. Forward chaining makes all allowable inferences based on the known facts, even if they are irrelevant to the goal at hand. In our crime example, there were no rules capable of drawing irrelevant conclusions, so the lack of directedness was not a problem. In other cases (e.g., if many rules describe the eating habits of Americans and the prices of missiles), FOL-FC-ASK will generate many irrelevant conclusions.
One way to avoid drawing irrelevant conclusions is to use backward chaining, as described in Section 9.4. Another solution is to restrict forward chaining to a selected subset of rules, as in PL-FC-ENTAILS? (page 258). A third approach has emerged in the field of deductive databases, which are large-scale databases, like relational databases, but which use forward chaining as the standard inference tool rather than SQL queries. The idea is to rewrite the rule set, using information from the goal, so that only relevant variable bindings—those belonging to a so-called magic set—are considered during forward inference. For example, if the goal is Criminal(West), the rule that concludes Criminal(x) will be rewritten to include an extra conjunct that constrains the value of x:
Magic(x) ∧ American(x) ∧Weapon(y) ∧ Sells(x, y, z) ∧ Hostile(z) ⇒ Criminal(x) .
4 The word production in production systems denotes a condition–action rule.
The fact Magic(West) is also added to the KB. In this way, even if the knowledge base contains facts about millions of Americans, only Colonel West will be considered during the forward inference process. The complete process for defining magic sets and rewriting the knowledge base is too complex to go into here, but the basic idea is to perform a sort of “generic” backward inference from the goal in order to work out which variable bindings need to be constrained. The magic sets approach can therefore be thought of as a kind of hybrid between forward inference and backward preprocessing.
BACKWARD CHAINING
The second major family of logical inference algorithms uses the backward chaining approach introduced in Section 7.5 for definite clauses. These algorithms work backward from the goal, chaining through rules to find known facts that support the proof. We describe the basic algorithm, and then we describe how it is used in logic programming, which is the most widely used form of automated reasoning. We also see that backward chaining has some disadvantages compared with forward chaining, and we look at ways to overcome them. Finally, we look at the close connection between logic programming and constraint satisfaction problems.
A backward-chaining algorithm
Figure 9.6 shows a backward-chaining algorithm for definite clauses. FOL-BC-ASK(KB , goal ) will be proved if the knowledge base contains a clause of the form lhs ⇒ goal , where lhs (left-hand side) is a list of conjuncts. An atomic fact like American(West) is considered as a clause whose lhs is the empty list. Now a query that contains variables might be proved in multiple ways. For example, the query Person(x) could be proved with the substitution {x/John} as well as with {x/Richard}. So we implement FOL-BC-ASK as a generatora function that returns multiple times, each time giving one possible result.
Backward chaining is a kind of AND/OR search—the OR part because the goal query can be proved by any rule in the knowledge base, and the AND part because all the conjuncts in the lhs of a clause must be proved. FOL-BC-OR works by fetching all clauses that might unify with the goal, standardizing the variables in the clause to be brand-new variables, and then, if the rhs of the clause does indeed unify with the goal, proving every conjunct in the lhs , using FOL-BC-AND. That function in turn works by proving each of the conjuncts in turn, keeping track of the accumulated substitution as we go. Figure 9.7 is the proof tree for deriving Criminal(West) from sentences (9.3) through (9.10).
Backward chaining, as we have written it, is clearly a depth-first search algorithm. This means that its space requirements are linear in the size of the proof (neglecting, for now, the space required to accumulate the solutions). It also means that backward chaining (unlike forward chaining) suffers from problems with repeated states and incompleteness. We will discuss these problems and some potential solutions, but first we show how backward chaining is used in logic programming systems.
function FOL-BC-ASK(KB , query) returns a generator of substitutions return FOL-BC-OR(KB , query ,{ })
generator FOL-BC-OR(KB , goal , θ) yields a substitution
for each rule (lhs ⇒ rhs) in FETCH-RULES-FOR-GOAL(KB , goal ) do
(lhs , rhs)← STANDARDIZE-VARIABLES((lhs , rhs))
for each θ′ in FOL-BC-AND(KB , lhs , UNIFY(rhs , goal , θ)) do
yield θ′
generator FOL-BC-AND(KB , goals , θ) yields a substitution if θ = failure then return else if LENGTH(goals) = 0 then yield θ
else do first ,rest← FIRST(goals), REST(goals) for each θ′ in FOL-BC-OR(KB , SUBST(θ, first), θ) do for each** θ′′ in FOL-BC-AND(KB , rest , θ′) do yield** θ′′
Figure 9.6 A simple backward-chaining algorithm for first-order knowledge bases.
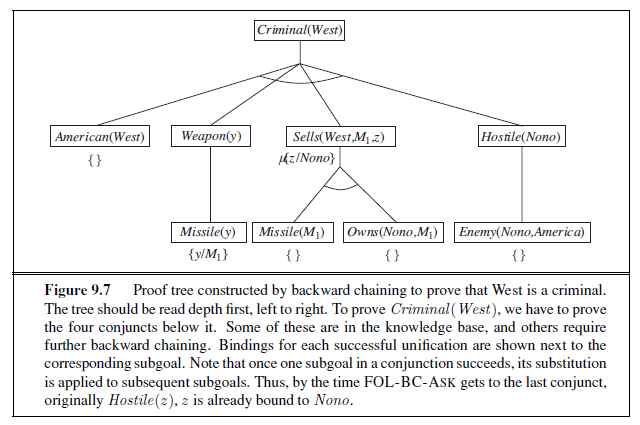
Logic programming
Logic programming is a technology that comes fairly close to embodying the declarative ideal described in Chapter 7: that systems should be constructed by expressing knowledge in a formal language and that problems should be solved by running inference processes on that knowledge. The ideal is summed up in Robert Kowalski’s equation,
Algorithm = Logic + Control .
Prolog is the most widely used logic programming language. It is used primarily as a rapidprototyping language and for symbol-manipulation tasks such as writing compilers (Van Roy, 1990) and parsing natural language (Pereira and Warren, 1980). Many expert systems have been written in Prolog for legal, medical, financial, and other domains.
Prolog programs are sets of definite clauses written in a notation somewhat different from standard first-order logic. Prolog uses uppercase letters for variables and lowercase for constants—the opposite of our convention for logic. Commas separate conjuncts in a clause, and the clause is written “backwards” from what we are used to; instead of A ∧ B ⇒ C in Prolog we have C :- A, B. Here is a typical example:
criminal(X) :- american(X), weapon(Y), sells(X,Y,Z), hostile(Z).
The notation [E|L] denotes a list whose first element is E and whose rest is L. Here is a Prolog program for append(X,Y,Z), which succeeds if list Z is the result of appending lists X and Y:
append([],Y,Y). append([A|X],Y,[A|Z]) :- append(X,Y,Z).
In English, we can read these clauses as (1) appending an empty list with a list Y produces the same list Y and (2) [A|Z] is the result of appending [A|X] onto Y, provided that Z is the result of appending X onto Y. In most high-level languages we can write a similar recursive function that describes how to append two lists. The Prolog definition is actually much more powerful, however, because it describes a relation that holds among three arguments, rather than a function computed from two arguments. For example, we can ask the query append(X,Y,[1,2]): what two lists can be appended to give [1,2]? We get back the solutions
X=[] Y=[1,2]; X=[1] Y=[2]; X=[1,2] Y=[]
The execution of Prolog programs is done through depth-first backward chaining, where clauses are tried in the order in which they are written in the knowledge base. Some aspects of Prolog fall outside standard logical inference:
-
Prolog uses the database semantics of Section 8.2.8 rather than first-order semantics, and this is apparent in its treatment of equality and negation (see Section 9.4.5).
-
There is a set of built-in functions for arithmetic. Literals using these function symbols are “proved” by executing code rather than doing further inference. For example, the goal “X is 4+3” succeeds with X bound to 7. On the other hand, the goal “5 is X+Y” fails, because the built-in functions do not do arbitrary equation solving.5
-
There are built-in predicates that have side effects when executed. These include input– output predicates and the assert/retract predicates for modifying the knowledge base. Such predicates have no counterpart in logic and can produce confusing results— for example, if facts are asserted in a branch of the proof tree that eventually fails.
-
The occur check is omitted from Prolog’s unification algorithm. This means that some unsound inferences can be made; these are almost never a problem in practice.
-
Prolog uses depth-first backward-chaining search with no checks for infinite recursion. This makes it very fast when given the right set of axioms, but incomplete when given the wrong ones.
Prolog’s design represents a compromise between declarativeness and execution efficiency— inasmuch as efficiency was understood at the time Prolog was designed.
Efficient implementation of logic programs
The execution of a Prolog program can happen in two modes: interpreted and compiled. Interpretation essentially amounts to running the FOL-BC-ASK algorithm from Figure 9.6, with the program as the knowledge base. We say “essentially” because Prolog interpreters contain a variety of improvements designed to maximize speed. Here we consider only two.
First, our implementation had to explicitly manage the iteration over possible results generated by each of the subfunctions. Prolog interpreters have a global data structure, a stack of choice points, to keep track of the multiple possibilities that we considered in FOL-BC-OR. This global stack is more efficient, and it makes debugging easier, because the debugger can move up and down the stack.
Second, our simple implementation of FOL-BC-ASK spends a good deal of time generating substitutions. Instead of explicitly constructing substitutions, Prolog has logic variables that remember their current binding. At any point in time, every variable in the program either is unbound or is bound to some value. Together, these variables and values implicitly define the substitution for the current branch of the proof. Extending the path can only add new variable bindings, because an attempt to add a different binding for an already bound variable results in a failure of unification. When a path in the search fails, Prolog will back up to a previous choice point, and then it might have to unbind some variables. This is done by keeping track of all the variables that have been bound in a stack called the trail. As each new variable is bound by UNIFY-VAR, the variable is pushed onto the trail. When a goal fails and it is time to back up to a previous choice point, each of the variables is unbound as it is removed from the trail.
Even the most efficient Prolog interpreters require several thousand machine instructions per inference step because of the cost of index lookup, unification, and building the recursive call stack. In effect, the interpreter always behaves as if it has never seen the program before; for example, it has to find clauses that match the goal. A compiled Prolog
5 Note that if the Peano axioms are provided, such goals can be solved by inference within a Prolog program.
procedure APPEND(ax , y ,az , continuation)
trail←GLOBAL-TRAIL-POINTER() if ax = [ ] and UNIFY(y ,az ) then CALL(continuation) RESET-TRAIL(trail) a, x , z ←NEW-VARIABLE(), NEW-VARIABLE(), NEW-VARIABLE() if UNIFY(ax , [a | x ]) and UNIFY(az , [a | z ]) then APPEND(x , y , z , continuation)
Figure 9.8 Pseudocode representing the result of compiling the Append predicate. The function NEW-VARIABLE returns a new variable, distinct from all other variables used so far. The procedure CALL(continuation) continues execution with the specified continuation.
program, on the other hand, is an inference procedure for a specific set of clauses, so it knows what clauses match the goal. Prolog basically generates a miniature theorem prover for each different predicate, thereby eliminating much of the overhead of interpretation. It is also possible to open-code the unification routine for each different call, thereby avoiding explicit analysis of term structure. (For details of open-coded unification, see Warren et al. (1977).)
The instruction sets of today’s computers give a poor match with Prolog’s semantics, so most Prolog compilers compile into an intermediate language rather than directly into machine language. The most popular intermediate language is the Warren Abstract Machine, or WAM, named after David H. D. Warren, one of the implementers of the first Prolog compiler. The WAM is an abstract instruction set that is suitable for Prolog and can be either interpreted or translated into machine language. Other compilers translate Prolog into a highlevel language such as Lisp or C and then use that language’s compiler to translate to machine language. For example, the definition of the Append predicate can be compiled into the code shown in Figure 9.8. Several points are worth mentioning:
Rather than having to search the knowledge base for Append clauses, the clauses become a procedure and the inferences are carried out simply by calling the procedure.
-
As described earlier, the current variable bindings are kept on a trail. The first step of the procedure saves the current state of the trail, so that it can be restored by if the first clause fails. This will undo any bindings generated by the first call to UNIFY.
-
The trickiest part is the use of continuations to implement choice points. You can think of a continuation as packaging up a procedure and a list of arguments that together define what should be done next whenever the current goal succeeds. It would not do just to return from a procedure like APPEND when the goal succeeds, because it could succeed in several ways, and each of them has to be explored. The continuation argument solves this problem because it can be called each time the goal succeeds. In the APPEND code, if the first argument is empty and the second argument unifies with the third, then the APPEND predicate has succeeded. We then CALL the continuation, with the appropriate bindings on the trail, to do whatever should be done next. For example, if the call to APPEND were at the top level, the continuation would print the bindings of the variables.
Before Warren’s work on the compilation of inference in Prolog, logic programming was too slow for general use. Compilers by Warren and others allowed Prolog code to achieve speeds that are competitive with C on a variety of standard benchmarks (Van Roy, 1990). Of course, the fact that one can write a planner or natural language parser in a few dozen lines of Prolog makes it somewhat more desirable than C for prototyping most small-scale AI research projects.
Parallelization can also provide substantial speedup. There are two principal sources of parallelism. The first, called OR-parallelism, comes from the possibility of a goal unifying with many different clauses in the knowledge base. Each gives rise to an independent branch in the search space that can lead to a potential solution, and all such branches can be solved in parallel. The second, called AND-parallelism, comes from the possibility of solving each conjunct in the body of an implication in parallel. AND-parallelism is more difficult to achieve, because solutions for the whole conjunction require consistent bindings for all the variables. Each conjunctive branch must communicate with the other branches to ensure a global solution.
Redundant inference and infinite loops
We now turn to the Achilles heel of Prolog: the mismatch between depth-first search and search trees that include repeated states and infinite paths. Consider the following logic program that decides if a path exists between two points on a directed graph:
path(X,Z) :- link(X,Z). path(X,Z) :- path(X,Y), link(Y,Z).
A simple three-node graph, described by the facts link(a,b) and link(b,c), is shown in Figure 9.9(a). With this program, the query path(a,c) generates the proof tree shown in Figure 9.10(a). On the other hand, if we put the two clauses in the order
path(X,Z) :- path(X,Y), link(Y,Z). path(X,Z) :- link(X,Z).
then Prolog follows the infinite path shown in Figure 9.10(b). Prolog is therefore incomplete as a theorem prover for definite clauses—even for Datalog programs, as this example shows— because, for some knowledge bases, it fails to prove sentences that are entailed. Notice that forward chaining does not suffer from this problem: once path(a,b), path(b,c), and path(a,c) are inferred, forward chaining halts.
Depth-first backward chaining also has problems with redundant computations. For example, when finding a path from A~1~ to J~4~ in Figure 9.9(b), Prolog performs 877 inferences, most of which involve finding all possible paths to nodes from which the goal is unreachable. This is similar to the repeated-state problem discussed in Chapter 3. The total amount of inference can be exponential in the number of ground facts that are generated. If we apply forward chaining instead, at most n^2^ path(X,Y) facts can be generated linking n nodes. For the problem in Figure 9.9(b), only 62 inferences are needed.
Forward chaining on graph search problems is an example of dynamic programming, in which the solutions to subproblems are constructed incrementally from those of smaller
subproblems and are cached to avoid recomputation. We can obtain a similar effect in a backward chaining system using memoization—that is, caching solutions to subgoals as they are found and then reusing those solutions when the subgoal recurs, rather than repeating the previous computation. This is the approach taken by tabled logic programming systems, which use efficient storage and retrieval mechanisms to perform memoization. Tabled logic programming combines the goal-directedness of backward chaining with the dynamicprogramming efficiency of forward chaining. It is also complete for Datalog knowledge bases, which means that the programmer need worry less about infinite loops. (It is still possible to get an infinite loop with predicates like father(X,Y) that refer to a potentially unbounded number of objects.)
Database semantics of Prolog
Prolog uses database semantics, as discussed in Section 8.2.8. The unique names assumption says that every Prolog constant and every ground term refers to a distinct object, and the closed world assumption says that the only sentences that are true are those that are entailed by the knowledge base. There is no way to assert that a sentence is false in Prolog. This makes Prolog less expressive than first-order logic, but it is part of what makes Prolog more efficient and more concise. Consider the following Prolog assertions about some course offerings:
Course(CS , 101), Course(CS , 102), Course(CS , 106), Course(EE , 101). (9.11)
Under the unique names assumption, CS and EE are different (as are 101, 102, and 106), so this means that there are four distinct courses. Under the closed-world assumption there are no other courses, so there are exactly four courses. But if these were assertions in FOL rather than in Prolog, then all we could say is that there are somewhere between one and infinity courses. That’s because the assertions (in FOL) do not deny the possibility that other unmentioned courses are also offered, nor do they say that the courses mentioned are different from each other. If we wanted to translate Equation (9.11) into FOL, we would get this:
Course(d, n) ⇔ (d= CS ∧ n = 101) ∨ (d=CS ∧ n = 102)
∨ (d= CS ∧ n = 106) ∨ (d=EE ∧ n = 101) . (9.12)
This is called the completion of Equation (9.11). It expresses in FOL the idea that there areCOMPLETION
at most four courses. To express in FOL the idea that there are at least four courses, we need to write the completion of the equality predicate:
x = y ⇔ (x = CS ∧ y = CS ) ∨ (x = EE ∧ y = EE) ∨ (x = 101 ∧ y = 101)
∨ (x = 102 ∧ y = 102) ∨ (x = 106 ∧ y = 106) .
The completion is useful for understanding database semantics, but for practical purposes, if your problem can be described with database semantics, it is more efficient to reason with Prolog or some other database semantics system, rather than translating into FOL and reasoning with a full FOL theorem prover.
Constraint logic programming
In our discussion of forward chaining (Section 9.3), we showed how constraint satisfaction problems (CSPs) can be encoded as definite clauses. Standard Prolog solves such problems in exactly the same way as the backtracking algorithm given in Figure 6.5.
Because backtracking enumerates the domains of the variables, it works only for finitedomain CSPs. In Prolog terms, there must be a finite number of solutions for any goal with unbound variables. (For example, the goal diff(Q,SA), which says that Queensland and South Australia must be different colors, has six solutions if three colors are allowed.) Infinite-domain CSPs—for example, with integer or real-valued variables—require quite different algorithms, such as bounds propagation or linear programming.
Consider the following example. We define triangle(X,Y,Z) as a predicate that holds if the three arguments are numbers that satisfy the triangle inequality:
triangle(X,Y,Z) :- X>0, Y>0, Z>0, X+Y>=Z, Y+Z>=X, X+Z>=Y.
If we ask Prolog the query triangle(3,4,5), it succeeds. On the other hand, if we ask triangle(3,4,Z), no solution will be found, because the subgoal Z>=0 cannot be handled by Prolog; we can’t compare an unbound value to 0.
Constraint logic programming (CLP) allows variables to be constrained rather than bound. A CLP solution is the most specific set of constraints on the query variables that can be derived from the knowledge base. For example, the solution to the triangle(3,4,Z) query is the constraint 7 >= Z >= 1. Standard logic programs are just a special case of CLP in which the solution constraints must be equality constraints—that is, bindings.
CLP systems incorporate various constraint-solving algorithms for the constraints allowed in the language. For example, a system that allows linear inequalities on real-valued variables might include a linear programming algorithm for solving those constraints. CLP systems also adopt a much more flexible approach to solving standard logic programming queries. For example, instead of depth-first, left-to-right backtracking, they might use any of the more efficient algorithms discussed in Chapter 6, including heuristic conjunct ordering, backjumping, cutset conditioning, and so on. CLP systems therefore combine elements of constraint satisfaction algorithms, logic programming, and deductive databases.
Several systems that allow the programmer more control over the search order for inference have been defined. The MRS language (Genesereth and Smith, 1981; Russell, 1985) allows the programmer to write metarules to determine which conjuncts are tried first. The user could write a rule saying that the goal with the fewest variables should be tried first or could write domain-specific rules for particular predicates.
RESOLUTION
The last of our three families of logical systems is based on resolution. We saw on page 250 that propositional resolution using refutation is a complete inference procedure for propositional logic. In this section, we describe how to extend resolution to first-order logic.
Conjunctive normal form for first-order logic
As in the propositional case, first-order resolution requires that sentences be in conjunctive normal form (CNF)—that is, a conjunction of clauses, where each clause is a disjunction of literals.6 Literals can contain variables, which are assumed to be universally quantified. For example, the sentence
∀ x American(x) ∧ Weapon(y) ∧ Sells(x, y, z) ∧ Hostile(z) ⇒ Criminal(x)
becomes, in CNF,
¬American(x) ∨ ¬Weapon(y) ∨ ¬Sells(x, y, z) ∨ ¬Hostile(z) ∨ Criminal(x) .
Every sentence of first-order logic can be converted into an inferentially equivalent CNF sentence. In particular, the CNF sentence will be unsatisfiable just when the original sentence is unsatisfiable, so we have a basis for doing proofs by contradiction on the CNF sentences.
6 A clause can also be represented as an implication with a conjunction of atoms in the premise and a disjunction of atoms in the conclusion (Exercise 7.13). This is called implicative normal form or Kowalski form (especially when written with a right-to-left implication symbol (Kowalski, 1979)) and is often much easier to read.
The procedure for conversion to CNF is similar to the propositional case, which we saw on page 253. The principal difference arises from the need to eliminate existential quantifiers. We illustrate the procedure by translating the sentence “Everyone who loves all animals is loved by someone,” or
∀ x [∀ y Animal(y) ⇒ Loves(x, y)] ⇒ [∃ y Loves(y, x)] .
The steps are as follows:
- Eliminate implications:
∀ x [¬∀ y ¬Animal(y) ∨ Loves(x, y)] ∨ [∃ y Loves(y, x)] .
- Move ¬ inwards: In addition to the usual rules for negated connectives, we need rules for negated quantifiers. Thus, we have
¬∀ x p becomes ∃ x ¬p
¬∃ x p becomes ∀ x ¬p .
Our sentence goes through the following transformations:
∀ x [∃ y ¬(¬Animal(y) ∨ Loves(x, y))] ∨ [∃ y Loves(y, x)] .
∀ x [∃ y ¬¬Animal(y) ∧ ¬Loves(x, y)] ∨ [∃ y Loves(y, x)] .
∀ x [∃ y Animal(y) ∧ ¬Loves(x, y)] ∨ [∃ y Loves(y, x)] .
Notice how a universal quantifier (∀ y) in the premise of the implication has become an existential quantifier. The sentence now reads “Either there is some animal that x doesn’t love, or (if this is not the case) someone loves x.” Clearly, the meaning of the original sentence has been preserved.
- Standardize variables: For sentences like (∃xP (x))∨(∃xQ(x)) which use the same variable name twice, change the name of one of the variables. This avoids confusion later when we drop the quantifiers. Thus, we have
∀ x [∃ y Animal(y) ∧ ¬Loves(x, y)] ∨ [∃ z Loves(z, x)] .
- Skolemize: Skolemization is the process of removing existential quantifiers by elimination. In the simple case, it is just like the Existential Instantiation rule of Section 9.1: translate ∃x P (x) into P (A), where A is a new constant. However, we can’t apply Existential Instantiation to our sentence above because it doesn’t match the pattern ∃ v α; only parts of the sentence match the pattern. If we blindly apply the rule to the two matching parts we get
∀ x [Animal(A) ∧ ¬Loves(x,A)] ∨ Loves(B,x) ,
which has the wrong meaning entirely: it says that everyone either fails to love a particular animal A or is loved by some particular entity B. In fact, our original sentence allows each person to fail to love a different animal or to be loved by a different person. Thus, we want the Skolem entities to depend on x and z:
∀x [Animal(F (x)) ∧ ¬Loves(x, F (x))] ∨ Loves(G(z), x) .
Here F and G are Skolem functions. The general rule is that the arguments of the Skolem function are all the universally quantified variables in whose scope the existential quantifier appears. As with Existential Instantiation, the Skolemized sentence is satisfiable exactly when the original sentence is satisfiable.
-Drop universal quantifiers: At this point, all remaining variables must be universally quantified. Moreover, the sentence is equivalent to one in which all the universal quantifiers have been moved to the left. We can therefore drop the universal quantifiers:
[Animal(F (x)) ∧ ¬Loves(x, F (x))] ∨ Loves(G(z), x) .
- Distribute ∨ over ∧:
[Animal(F (x)) ∨ Loves(G(z), x)] ∧ [¬Loves(x, F (x)) ∨ Loves(G(z), x)] .
This step may also require flattening out nested conjunctions and disjunctions.
The sentence is now in CNF and consists of two clauses. It is quite unreadable. (It may help to explain that the Skolem function F (x) refers to the animal potentially unloved by x, whereas G(z) refers to someone who might love x.) Fortunately, humans seldom need look at CNF sentences—the translation process is easily automated.
The resolution inference rule
The resolution rule for first-order clauses is simply a lifted version of the propositional resolution rule given on page 253. Two clauses, which are assumed to be standardized apart so that they share no variables, can be resolved if they contain complementary literals. Propositional literals are complementary if one is the negation of the other; first-order literals are complementary if one unifies with the negation of the other. Thus, we have

This rule is called the binary resolution rule because it resolves exactly two literals. The binary resolution rule by itself does not yield a complete inference procedure. The full resolution rule resolves subsets of literals in each clause that are unifiable. An alternative approach is to extend factoring—the removal of redundant literals—to the first-order case. Propositional factoring reduces two literals to one if they are identical; first-order factoring reduces two literals to one if they are unifiable. The unifier must be applied to the entire clause. The combination of binary resolution and factoring is complete.
Example proofs
Resolution proves that KB |= α by proving KB ∧ ¬α unsatisfiable, that is, by deriving the empty clause. The algorithmic approach is identical to the propositional case, described in
Figure 7.12, so we need not repeat it here. Instead, we give two example proofs. The first is the crime example from Section 9.3. The sentences in CNF are
¬American(x) ∨ ¬Weapon(y) ∨ ¬Sells(x, y, z) ∨ ¬Hostile(z) ∨ Criminal(x)
¬Missile(x) ∨ ¬Owns(Nono, x) ∨ Sells(West , x,Nono)
¬Enemy(x,America) ∨Hostile(x)
¬Missile(x) ∨Weapon(x)
Owns(Nono,M~1~) Missile(M~1~)
American(West) Enemy(Nono,America) .
We also include the negated goal ¬Criminal(West). The resolution proof is shown in Figure 9.11. Notice the structure: single “spine” beginning with the goal clause, resolving against clauses from the knowledge base until the empty clause is generated. This is characteristic of resolution on Horn clause knowledge bases. In fact, the clauses along the main spine correspond exactly to the consecutive values of the goals variable in the backward-chaining algorithm of Figure 9.6. This is because we always choose to resolve with a clause whose positive literal unified with the leftmost literal of the “current” clause on the spine; this is exactly what happens in backward chaining. Thus, backward chaining is just a special case of resolution with a particular control strategy to decide which resolution to perform next.
Our second example makes use of Skolemization and involves clauses that are not definite clauses. This results in a somewhat more complex proof structure. In English, the problem is as follows:
Everyone who loves all animals is loved by someone. Anyone who kills an animal is loved by no one. Jack loves all animals. Either Jack or Curiosity killed the cat, who is named Tuna. Did Curiosity kill the cat?
First, we express the original sentences, some background knowledge, and the negated goal G in first-order logic:
A. ∀ x [∀ y Animal(y) ⇒ Loves(x, y)] ⇒ [∃ y Loves(y, x)]
B. ∀ x [∃ z Animal(z) ∧ Kills(x, z)] ⇒ [∀ y ¬Loves(y, x)]
C. ∀ x Animal(x) ⇒ Loves(Jack , x)
D. Kills(Jack ,Tuna) ∨Kills(Curiosity ,Tuna)
E. Cat(Tuna)
F. ∀x Cat(x) ⇒ Animal(x)
¬G. ¬Kills(Curiosity ,Tuna)
Now we apply the conversion procedure to convert each sentence to CNF:
A1. Animal(F (x)) ∨ Loves(G(x), x)
A2. ¬Loves(x, F (x)) ∨ Loves(G(x), x)
B. ¬Loves(y, x) ∨ ¬Animal(z) ∨ ¬Kills(x, z)
C. ¬Animal(x) ∨ Loves(Jack , x)
D. Kills(Jack ,Tuna) ∨ Kills(Curiosity ,Tuna)
E. Cat(Tuna)
F. ¬Cat(x) ∨ Animal(x)
¬G. ¬Kills(Curiosity ,Tuna)
The resolution proof that Curiosity killed the cat is given in Figure 9.12. In English, the proof could be paraphrased as follows:
Suppose Curiosity did not kill Tuna. We know that either Jack or Curiosity did; thus Jack must have. Now, Tuna is a cat and cats are animals, so Tuna is an animal. Because anyone who kills an animal is loved by no one, we know that no one loves Jack. On the other hand, Jack loves all animals, so someone loves him; so we have a contradiction. Therefore, Curiosity killed the cat.
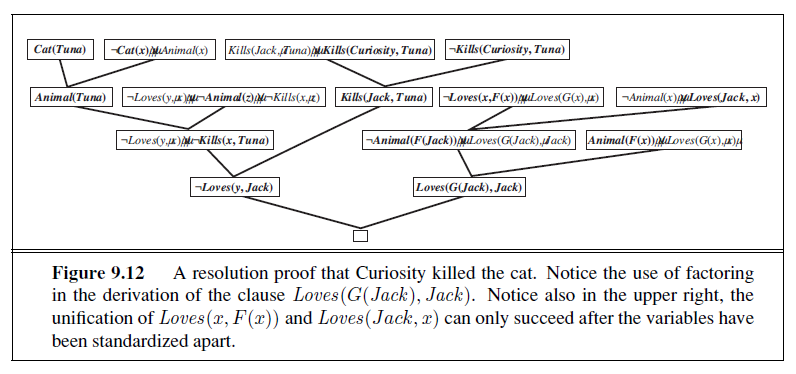
The proof answers the question “Did Curiosity kill the cat?” but often we want to pose more general questions, such as “Who killed the cat?” Resolution can do this, but it takes a little more work to obtain the answer. The goal is ∃w Kills(w,Tuna), which, when negated, becomes ¬Kills(w,Tuna) in CNF. Repeating the proof in Figure 9.12 with the new negated goal, we obtain a similar proof tree, but with the substitution {w/Curiosity} in one of the steps. So, in this case, finding out who killed the cat is just a matter of keeping track of the bindings for the query variables in the proof.
Unfortunately, resolution can produce nonconstructive proofs for existential goals. For example, ¬Kills(w,Tuna) resolves with Kills(Jack ,Tuna) ∨Kills(Curiosity ,Tuna) to give Kills(Jack ,Tuna), which resolves again with ¬Kills(w,Tuna) to yield the empty clause. Notice that w has two different bindings in this proof; resolution is telling us that, yes, someone killed Tuna—either Jack or Curiosity. This is no great surprise! One solution is to restrict the allowed resolution steps so that the query variables can be bound only once in a given proof; then we need to be able to backtrack over the possible bindings. Another solution is to add a special answer literal to the negated goal, which becomes ¬Kills(w,Tuna) ∨ Answer(w). Now, the resolution process generates an answer whenever a clause is generated containing just a single answer literal. For the proof in Figure 9.12, this is Answer(Curiosity). The nonconstructive proof would generate the clause Answer(Curiosity) ∨ Answer(Jack), which does not constitute an answer.
Completeness of resolution
This section gives a completeness proof of resolution. It can be safely skipped by those who are willing to take it on faith.
We show that resolution is refutation-complete, which means that if a set of sentences is unsatisfiable, then resolution will always be able to derive a contradiction. Resolution cannot be used to generate all logical consequences of a set of sentences, but it can be used to establish that a given sentence is entailed by the set of sentences. Hence, it can be used to find all answers to a given question, Q(x), by proving that KB ∧ ¬Q(x) is unsatisfiable.
We take it as given that any sentence in first-order logic (without equality) can be rewritten as a set of clauses in CNF. This can be proved by induction on the form of the sentence, using atomic sentences as the base case (Davis and Putnam, 1960). Our goal therefore is to prove the following: if S is an unsatisfiable set of clauses, then the application of a finite number of resolution steps to S will yield a contradiction.
Our proof sketch follows Robinson’s original proof with some simplifications from Genesereth and Nilsson (1987). The basic structure of the proof (Figure 9.13) is as follows:
-
First, we observe that if S is unsatisfiable, then there exists a particular set of ground instances of the clauses of S such that this set is also unsatisfiable (Herbrand’s theorem).
-
We then appeal to the ground resolution theorem given in Chapter 7, which states that propositional resolution is complete for ground sentences.
-
We then use a lifting lemma to show that, for any propositional resolution proof using the set of ground sentences, there is a corresponding first-order resolution proof using the first-order sentences from which the ground sentences were obtained.
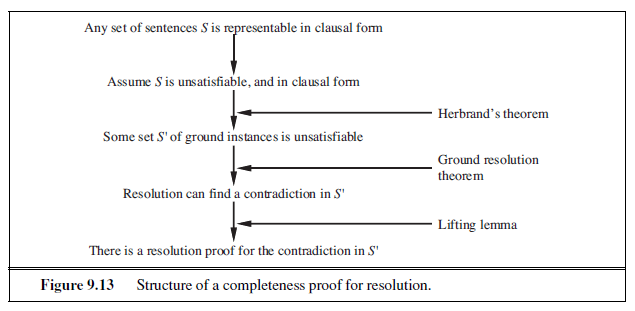
To carry out the first step, we need three new concepts:
- Herbrand universe: If S is a set of clauses, then HS , the Herbrand universe of S, is the set of all ground terms constructable from the following:
a. The function symbols in S, if any. b. The constant symbols in S, if any; if none, then the constant symbol A.
For example, if S contains just the clause ¬P (x, F (x,A))∨¬Q(x,A)∨ R(x,B), then H~S~ is the following infinite set of ground terms:
{A,B,F (A,A), F (A,B), F (B,A), F (B,B), F (A,F (A,A)), . . .} .
-
Saturation: If S is a set of clauses and P is a set of ground terms, then P (S), the saturation of S with respect to P , is the set of all ground clauses obtained by applying all possible consistent substitutions of ground terms in P with variables in S.
-
Herbrand base: The saturation of a set S of clauses with respect to its Herbrand universe is called the Herbrand base of S, written as HS(S). For example, if S contains solely the clause just given, then HS(S) is the infinite set of clauses
{¬P (A,F (A,A)) ∨ ¬Q(A,A) ∨ R(A,B),
¬P (B,F (B,A)) ∨ ¬Q(B,A) ∨ R(B,B),
¬P (F (A,A), F (F (A,A), A)) ∨ ¬Q(F (A,A), A) ∨ R(F (A,A), B),
¬P (F (A,B), F (F (A,B), A)) ∨ ¬Q(F (A,B), A) ∨ R(F (A,B), B), . . . }
These definitions allow us to state a form of Herbrand’s theorem (Herbrand, 1930):
If a set S of clauses is unsatisfiable, then there exists a finite subset of HS(S) that is also unsatisfiable.
Let S ′ be this finite subset of ground sentences. Now, we can appeal to the ground resolution theorem (page 255) to show that the resolution closure RC (S′) contains the empty clause. That is, running propositional resolution to completion on S′ will derive a contradiction. Now that we have established that there is always a resolution proof involving some finite subset of the Herbrand base of S, the next step is to show that there is a resolution
GÖDEL’S INCOMPLETENESS THEOREM
By slightly extending the language of first-order logic to allow for the mathematical induction schema in arithmetic, Kurt Gödel was able to show, in his incompleteness theorem, that there are true arithmetic sentences that cannot be proved.
The proof of the incompleteness theorem is somewhat beyond the scope of this book, occupying, as it does, at least 30 pages, but we can give a hint here. We begin with the logical theory of numbers. In this theory, there is a single constant, 0, and a single function, S (the successor function). In the intended model, S(0) denotes 1, S(S(0)) denotes 2, and so on; the language therefore has names for all the natural numbers. The vocabulary also includes the function symbols +, ×, and Expt (exponentiation) and the usual set of logical connectives and quantifiers. The first step is to notice that the set of sentences that we can write in this language can be enumerated. (Imagine defining an alphabetical order on the symbols and then arranging, in alphabetical order, each of the sets of sentences of length 1, 2, and so on.) We can then number each sentence α with a unique natural number #α (the Gödel number). This is crucial: number theory contains a name for each of its own sentences. Similarly, we can number each possible proof P with a Gödel number G(P ), because a proof is simply a finite sequence of sentences.
Now suppose we have a recursively enumerable set A of sentences that are true statements about the natural numbers. Recalling that A can be named by a given set of integers, we can imagine writing in our language a sentence α(j,A) of the following sort:
∀ i i is not the Gödel number of a proof of the sentence whose Gödel number is j, where the proof uses only premises in A.
Then let σ be the sentence α(#σ,A), that is, a sentence that states its own unprovability from A. (That this sentence always exists is true but not entirely obvious.)
Now we make the following ingenious argument: Suppose that σ is provable from A; then σ is false (because σ says it cannot be proved). But then we have a false sentence that is provable from A, so A cannot consist of only true sentences— a violation of our premise. Therefore, σ is not provable from A. But this is exactly what σ itself claims; hence σ is a true sentence.
So, we have shown (barring 29 1/2 pages) that for any set of true sentences of number theory, and in particular any set of basic axioms, there are other true sentences that cannot be proved from those axioms. This establishes, among other things, that we can never prove all the theorems of mathematics within any given system of axioms. Clearly, this was an important discovery for mathematics. Its significance for AI has been widely debated, beginning with speculations by Gödel himself. We take up the debate in Chapter 26.
proof using the clauses of S itself, which are not necessarily ground clauses. We start by considering a single application of the resolution rule. Robinson stated this lemma:
Let C~1~ and C~2~ be two clauses with no shared variables, and let C′~1~ and C′~2~ beground instances of C~1~ and C~2~. If C ′ is a resolvent of C′~1~ and C′~2~ , then there existsa clause C such that (1) C is a resolvent of C~1~ and C~2~ and (2) C ′ is a groundinstance of C .
This is called a lifting lemma, because it lifts a proof step from ground clauses up to general first-order clauses. In order to prove his basic lifting lemma, Robinson had to invent unification and derive all of the properties of most general unifiers. Rather than repeat the proof here, we simply illustrate the lemma:
C~1~ = ¬P (x, F (x,A)) ∨ ¬Q(x,A) ∨ R(x,B)
C~2~ = ¬N(G(y), z) ∨ P (H(y), z)
C′~1~ = ¬P (H(B), F (H(B), A)) ∨ ¬Q(H(B), A) ∨ R(H(B), B)
C′~2~ = ¬N(G(B), F (H(B), A)) ∨ P (H(B), F (H(B), A))
C′= ¬N(G(B), F (H(B), A)) ∨ ¬Q(H(B), A) ∨ R(H(B), B)
C = ¬N(G(y), F (H(y), A)) ∨ ¬Q(H(y), A) ∨ R(H(y), B) .
We see that indeed C ′ is a ground instance of C . In general, for C′~1~ and C′~2~ to have anyresolvents, they must be constructed by first applying to C~1~ and C~2~ the most general unifier of a pair of complementary literals in C~1~ and C~2~. From the lifting lemma, it is easy to derive a similar statement about any sequence of applications of the resolution rule:
For any clause C ′ in the resolution closure of S′ there is a clause C in the resolution closure of S such that C′ is a ground instance of C and the derivation of C is the same length as the derivation of C′.
From this fact, it follows that if the empty clause appears in the resolution closure of S ′, it must also appear in the resolution closure of S. This is because the empty clause cannot be a ground instance of any other clause. To recap: we have shown that if S is unsatisfiable, then there is a finite derivation of the empty clause using the resolution rule.
The lifting of theorem proving from ground clauses to first-order clauses provides a vast increase in power. This increase comes from the fact that the first-order proof need instantiate variables only as far as necessary for the proof, whereas the ground-clause methods were required to examine a huge number of arbitrary instantiations.
Equality
None of the inference methods described so far in this chapter handle an assertion of the form x = y. Three distinct approaches can be taken. The first approach is to axiomatize equality— to write down sentences about the equality relation in the knowledge base. We need to say that equality is reflexive, symmetric, and transitive, and we also have to say that we can substitute equals for equals in any predicate or function. So we need three basic axioms, and then one
for each predicate and function:
∀ x x= x
∀ x, y x= y ⇒ y = x
∀ x, y, z x= y ∧ y = z ⇒ x= z
∀ x, y x= y ⇒ (P~1~(x) ⇔ P~1~(y))
∀ x, y x= y ⇒ (p~2~(x) ⇔ p~2~(y)) . . .
∀ w, x, y, z w = y ∧ x= z ⇒ (F~1~(w, x)= F~1~(y, z))
∀ w, x, y, z w = y ∧ x= z ⇒ (F~2~(w, x)= F~2~(y, z)) . . .
Given these sentences, a standard inference procedure such as resolution can perform tasks requiring equality reasoning, such as solving mathematical equations. However, these axioms will generate a lot of conclusions, most of them not helpful to a proof. So there has been a search for more efficient ways of handling equality. One alternative is to add inference rules rather than axioms. The simplest rule, demodulation, takes a unit clause x= y and some clause α that contains the term x, and yields a new clause formed by substituting y for x within α. It works if the term within α unifies with x; it need not be exactly equal to x. Note that demodulation is directional; given x = y, the x always gets replaced with y, never vice versa. That means that demodulation can be used for simplifying expressions using demodulators such as x + 0= x or x^1^ = x. As another example, given
Father (Father (x)) = PaternalGrandfather (x) Birthdate(Father (Father (Bella)), 1926)
we can conclude by demodulation
Birthdate(PaternalGrandfather (Bella), 1926) .
More formally, we have

we have θ = UNIFY(F (A, y), F (x,B))= {x/A, y/B}, and we can conclude by paramodulation the sentence
P (B,A) ∨ Q(A) ∨R(B) .
Paramodulation yields a complete inference procedure for first-order logic with equality. A third approach handles equality reasoning entirely within an extended unification algorithm. That is, terms are unifiable if they are provably equal under some substitution, where “provably” allows for equality reasoning. For example, the terms 1 + 2 and 2 + 1 normally are not unifiable, but a unification algorithm that knows that x + y = y + x could unify them with the empty substitution. Equational unification of this kind can be done with efficient algorithms designed for the particular axioms used (commutativity, associativity, and so on) rather than through explicit inference with those axioms. Theorem provers using this technique are closely related to the CLP systems described in Section 9.4.
Resolution strategies
We know that repeated applications of the resolution inference rule will eventually find a proof if one exists. In this subsection, we examine strategies that help find proofs efficiently.
Unit preference: This strategy prefers to do resolutions where one of the sentences is a single literal (also known as a unit clause). The idea behind the strategy is that we are trying to produce an empty clause, so it might be a good idea to prefer inferences that produce shorter clauses. Resolving a unit sentence (such as P ) with any other sentence (such as ¬P∨¬Q∨R) always yields a clause (in this case, ¬Q ∨ R) that is shorter than the other clause. When the unit preference strategy was first tried for propositional inference in 1964, it led to a dramatic speedup, making it feasible to prove theorems that could not be handled without the preference. Unit resolution is a restricted form of resolution in which every resolution step must involve a unit clause. Unit resolution is incomplete in general, but complete for Horn clauses. Unit resolution proofs on Horn clauses resemble forward chaining.
The OTTER theorem prover (Organized Techniques for Theorem-proving and Effective Research, McCune, 1992), uses a form of best-first search. Its heuristic function measures the “weight” of each clause, where lighter clauses are preferred. The exact choice of heuristic is up to the user, but generally, the weight of a clause should be correlated with its size or difficulty. Unit clauses are treated as light; the search can thus be seen as a generalization of the unit preference strategy.
Set of support: Preferences that try certain resolutions first are helpful, but in general it is more effective to try to eliminate some potential resolutions altogether. For example, we can insist that every resolution step involve at least one element of a special set of clauses—the set of support. The resolvent is then added into the set of support. If the set of support is small relative to the whole knowledge base, the search space will be reduced dramatically.
We have to be careful with this approach because a bad choice for the set of support will make the algorithm incomplete. However, if we choose the set of support S so that the remainder of the sentences are jointly satisfiable, then set-of-support resolution is complete. For example, one can use the negated query as the set of support, on the assumption that the original knowledge base is consistent. (After all, if it is not consistent, then the fact that the query follows from it is vacuous.) The set-of-support strategy has the additional advantage of generating goal-directed proof trees that are often easy for humans to understand.
Input resolution: In this strategy, every resolution combines one of the input sentences (from the KB or the query) with some other sentence. The proof in Figure 9.11 on page 348 uses only input resolutions and has the characteristic shape of a single “spine” with single sentences combining onto the spine. Clearly, the space of proof trees of this shape is smaller than the space of all proof graphs. In Horn knowledge bases, Modus Ponens is a kind of input resolution strategy, because it combines an implication from the original KB with some other sentences. Thus, it is no surprise that input resolution is complete for knowledge bases that are in Horn form, but incomplete in the general case. The linear resolution strategy is a slight generalization that allows P and Q to be resolved together either if P is in the original KB or if P is an ancestor of Q in the proof tree. Linear resolution is complete.
Subsumption: The subsumption method eliminates all sentences that are subsumed by (that is, more specific than) an existing sentence in the KB. For example, if P (x) is in the KB, then there is no sense in adding P (A) and even less sense in adding P (A) ∨Q(B). Subsumption helps keep the KB small and thus helps keep the search space small.
Practical uses of resolution theorem provers
Theorem provers can be applied to the problems involved in the synthesis and verificationSYNTHESIS of both hardware and software. Thus, theorem-proving research is carried out in the fields of hardware design, programming languages, and software engineering—not just in AI.
In the case of hardware, the axioms describe the interactions between signals and circuit elements. (See Section 8.4.2 on page 309 for an example.) Logical reasoners designed specially for verification have been able to verify entire CPUs, including their timing properties (Srivas and Bickford, 1990). The AURA theorem prover has been applied to design circuits that are more compact than any previous design (Wojciechowski and Wojcik, 1983).
In the case of software, reasoning about programs is quite similar to reasoning about actions, as in Chapter 7: axioms describe the preconditions and effects of each statement. The formal synthesis of algorithms was one of the first uses of theorem provers, as outlined by Cordell Green (1969a), who built on earlier ideas by Herbert Simon (1963). The idea is to constructively prove a theorem to the effect that “there exists a program p satisfying a certain specification.” Although fully automated deductive synthesis, as it is called, has not yet become feasible for general-purpose programming, hand-guided deductive synthesis has been successful in designing several novel and sophisticated algorithms. Synthesis of specialpurpose programs, such as scientific computing code, is also an active area of research.
Similar techniques are now being applied to software verification by systems such as the SPIN model checker (Holzmann, 1997). For example, the Remote Agent spacecraft control program was verified before and after flight (Havelund et al., 2000). The RSA public key encryption algorithm and the Boyer–Moore string-matching algorithm have been verified this way (Boyer and Moore, 1984).
SUMMARY
We have presented an analysis of logical inference in first-order logic and a number of algorithms for doing it.
-
A first approach uses inference rules (universal instantiation and existential instantiation) to propositionalize the inference problem. Typically, this approach is slow, unless the domain is small.
-
The use of unification to identify appropriate substitutions for variables eliminates the instantiation step in first-order proofs, making the process more efficient in many cases.
-
A lifted version of Modus Ponens uses unification to provide a natural and powerful inference rule, generalized Modus Ponens. The forward-chaining and backwardchaining algorithms apply this rule to sets of definite clauses.
-
Generalized Modus Ponens is complete for definite clauses, although the entailment problem is semidecidable. For Datalog knowledge bases consisting of function-free definite clauses, entailment is decidable.
-
Forward chaining is used in deductive databases, where it can be combined with relational database operations. It is also used in production systems, which perform efficient updates with very large rule sets. Forward chaining is complete for Datalog and runs in polynomial time.
-
Backward chaining is used in logic programming systems, which employ sophisticated compiler technology to provide very fast inference. Backward chaining suffers from redundant inferences and infinite loops; these can be alleviated by memoization.
-
Prolog, unlike first-order logic, uses a closed world with the unique names assumption and negation as failure. These make Prolog a more practical programming language, but bring it further from pure logic.
-
The generalized resolution inference rule provides a complete proof system for firstorder logic, using knowledge bases in conjunctive normal form.
-
Several strategies exist for reducing the search space of a resolution system without compromising completeness. One of the most important issues is dealing with equality; we showed how demodulation and paramodulation can be used.
-
Efficient resolution-based theorem provers have been used to prove interesting mathematical theorems and to verify and synthesize software and hardware.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
Gottlob Frege, who developed full first-order logic in 1879, based his system of inference on a collection of valid schemas plus a single inference rule, Modus Ponens. Whitehead and Russell (1910) expounded the so-called rules of passage (the actual term is from Herbrand (1930)) that are used to move quantifiers to the front of formulas. Skolem constants and Skolem functions were introduced, appropriately enough, by Thoralf Skolem (1920). Oddly enough, it was Skolem who introduced the Herbrand universe (Skolem, 1928).
Herbrand’s theorem (Herbrand, 1930) has played a vital role in the development of automated reasoning. Herbrand is also the inventor of unification. Gödel (1930) built on the ideas of Skolem and Herbrand to show that first-order logic has a complete proof procedure. Alan Turing (1936) and Alonzo Church (1936) simultaneously showed, using very different proofs, that validity in first-order logic was not decidable. The excellent text by Enderton (1972) explains all of these results in a rigorous yet understandable fashion.
Abraham Robinson proposed that an automated reasoner could be built using propositionalization and Herbrand’s theorem, and Paul Gilmore (1960) wrote the first program. Davis and Putnam (1960) introduced the propositionalization method of Section 9.1. Prawitz (1960) developed the key idea of letting the quest for propositional inconsistency drive the search, and generating terms from the Herbrand universe only when they were necessary to establish propositional inconsistency. After further development by other researchers, this idea led J. A. Robinson (no relation) to develop resolution (Robinson, 1965).
In AI, resolution was adopted for question-answering systems by Cordell Green and Bertram Raphael (1968). Early AI implementations put a good deal of effort into data structures that would allow efficient retrieval of facts; this work is covered in AI programming texts (Charniak et al., 1987; Norvig, 1992; Forbus and de Kleer, 1993). By the early 1970s, forward chaining was well established in AI as an easily understandable alternative to resolution. AI applications typically involved large numbers of rules, so it was important to develop efficient rule-matching technology, particularly for incremental updates. The technology for production systems was developed to support such applications. The production system language OPS-5 (Forgy, 1981; Brownston et al., 1985), incorporating the efficient rete match process (Forgy, 1982), was used for applications such as the R~1~ expert system for minicomputer configuration (McDermott, 1982). The SOAR cognitive architecture (Laird et al., 1987; Laird, 2008) was designed to handle very large rule sets—up to a million rules (Doorenbos, 1994). Example applications of SOAR include controlling simulated fighter aircraft (Jones et al., 1998), airspace management (Taylor et al., 2007), AI characters for computer games (Wintermute et al., 2007), and training tools for soldiers (Wray and Jones, 2005).
The field of deductive databases began with a workshop in Toulouse in 1977 that brought together experts in logical inference and database systems (Gallaire and Minker, 1978). Influential work by Chandra and Harel (1980) and Ullman (1985) led to the adoption of Datalog as a standard language for deductive databases. The development of the magic sets technique for rule rewriting by Bancilhon et al. (1986) allowed forward chaining to borrow the advantage of goal-directedness from backward chaining. Current work includes the idea of integrating multiple databases into a consistent dataspace (Halevy, 2007).
Backward chaining for logical inference appeared first in Hewitt’s PLANNER language (1969). Meanwhile, in 1972, Alain Colmerauer had developed and implemented Prolog for the purpose of parsing natural language—Prolog’s clauses were intended initially as context-free grammar rules (Roussel, 1975; Colmerauer et al., 1973). Much of the theoretical background for logic programming was developed by Robert Kowalski, working with Colmerauer; see Kowalski (1988) and Colmerauer and Roussel (1993) for a historical overview. Efficient Prolog compilers are generally based on the Warren Abstract Machine (WAM) model of computation developed by David H. D. Warren (1983). Van Roy (1990) showed that Prolog programs can be competitive with C programs in terms of speed.
Methods for avoiding unnecessary looping in recursive logic programs were developed independently by Smith et al. (1986) and Tamaki and Sato (1986). The latter paper also included memoization for logic programs, a method developed extensively as tabled logic programming by David S. Warren. Swift and Warren (1994) show how to extend the WAM to handle tabling, enabling Datalog programs to execute an order of magnitude faster than forward-chaining deductive database systems.
Early work on constraint logic programming was done by Jaffar and Lassez (1987). Jaffar et al. (1992) developed the CLP(R) system for handling real-valued constraints. There are now commercial products for solving large-scale configuration and optimization problems with constraint programming; one of the best known is ILOG (Junker, 2003). Answer set programming (Gelfond, 2008) extends Prolog, allowing disjunction and negation.
Texts on logic programming and Prolog, including Shoham (1994), Bratko (2001), Clocksin (2003), and Clocksin and Mellish (2003). Prior to 2000, the Journal of Logic Programming was the journal of record; it has now been replaced by Theory and Practice of Logic Programming. Logic programming conferences include the International Conference on Logic Programming (ICLP) and the International Logic Programming Symposium (ILPS).
Research into mathematical theorem proving began even before the first complete first-order systems were developed. Herbert Gelernter’s Geometry Theorem Prover (Gelernter, 1959) used heuristic search methods combined with diagrams for pruning false subgoals and was able to prove some quite intricate results in Euclidean geometry. The demodulation and paramodulation rules for equality reasoning were introduced by Wos et al. (1967) and Wos and Robinson (1968), respectively. These rules were also developed independently in the context of term-rewriting systems (Knuth and Bendix, 1970). The incorporation of equality reasoning into the unification algorithm is due to Gordon Plotkin (1972). Jouannaud and Kirchner (1991) survey equational unification from a term-rewriting perspective. An overview of unification is given by Baader and Snyder (2001).
A number of control strategies have been proposed for resolution, beginning with the unit preference strategy (Wos et al., 1964). The set-of-support strategy was proposed by Wos et al. (1965) to provide a degree of goal-directedness in resolution. Linear resolution first appeared in Loveland (1970). Genesereth and Nilsson (1987, Chapter 5) provide a short but thorough analysis of a wide variety of control strategies.
A Computational Logic (Boyer and Moore, 1979) is the basic reference on the BoyerMoore theorem prover. Stickel (1992) covers the Prolog Technology Theorem Prover (PTTP), which combines the advantages of Prolog compilation with the completeness of model elimination. SETHEO (Letz et al., 1992) is another widely used theorem prover based on this approach. LEANTAP (Beckert and Posegga, 1995) is an efficient theorem prover implemented in only 25 lines of Prolog. Weidenbach (2001) describes SPASS, one of the strongest current theorem provers. The most successful theorem prover in recent annual competitions has been VAMPIRE (Riazanov and Voronkov, 2002). The COQ system (Bertot et al., 2004) and the E equational solver (Schulz, 2004) have also proven to be valuable tools for proving correctness. Theorem provers have been used to automatically synthesize and verify software for controlling spacecraft (Denney et al., 2006), including NASA’s new Orion capsule (Lowry, 2008). The design of the FM9001 32-bit microprocessor was proved correct by the system (Hunt and Brock, 1992). The Conference on Automated Deduction (CADE) runs an annual contest for automated theorem provers. From 2002 through 2008, the most successful system has been VAMPIRE (Riazanov and Voronkov, 2002). Wiedijk (2003) compares the strength of 15 mathematical provers. TPTP (Thousands of Problems for Theorem Provers) is a library of theorem-proving problems, useful for comparing the performance of systems (Sutcliffe and Suttner, 1998; Sutcliffe et al., 2006).
Theorem provers have come up with novel mathematical results that eluded human mathematicians for decades, as detailed in the book Automated Reasoning and the Discovery of Missing Elegant Proofs (Wos and Pieper, 2003). The SAM (Semi-Automated Mathematics) program was the first, proving a lemma in lattice theory (Guard et al., 1969). The AURA program has also answered open questions in several areas of mathematics (Wos and Winker, 1983). The Boyer–Moore theorem prover (Boyer and Moore, 1979) was used by Natarajan Shankar to give the first fully rigorous formal proof of Gödel’s Incompleteness Theorem (Shankar, 1986). The NUPRL system proved Girard’s paradox (Howe, 1987) and Higman’s Lemma (Murthy and Russell, 1990). In 1933, Herbert Robbins proposed a simple set of axioms—the Robbins algebra—that appeared to define Boolean algebra, but no proof could be found (despite serious work by Alfred Tarski and others). On October 10, 1996, after eight days of computation, EQP (a version of OTTER) found a proof (McCune, 1997).
Many early papers in mathematical logic are to be found in From Frege to Gödel: A Source Book in Mathematical Logic (van Heijenoort, 1967). Textbooks geared toward automated deduction include the classic Symbolic Logic and Mechanical Theorem Proving (Chang and Lee, 1973), as well as more recent works by Duffy (1991), Wos et al. (1992), Bibel (1993), and Kaufmann et al. (2000). The principal journal for theorem proving is the Journal of Automated Reasoning; the main conferences are the annual Conference on Automated Deduction (CADE) and the International Joint Conference on Automated Reasoning (IJCAR). The Handbook of Automated Reasoning (Robinson and Voronkov, 2001) collects papers in the field. MacKenzie’s Mechanizing Proof (2004) covers the history and technology of theorem proving for the popular audience.
EXERCISES
9.1 Prove that Universal Instantiation is sound and that Existential Instantiation produces an inferentially equivalent knowledge base.
9.2 From Likes(Jerry , IceCream) it seems reasonable to infer ∃x Likes(x, IceCream). Write down a general inference rule, Existential Introduction, that sanctions this inference. State carefully the conditions that must be satisfied by the variables and terms involved.
9.3 Suppose a knowledge base contains just one sentence, ∃x AsHighAs(x,Everest). Which of the following are legitimate results of applying Existential Instantiation?
a. AsHighAs(Everest ,Everest).
b. AsHighAs(Kilimanjaro ,Everest).
c. AsHighAs(Kilimanjaro ,Everest) ∧ AsHighAs(BenNevis,Everest)
(after two applications).
9.4 For each pair of atomic sentences, give the most general unifier if it exists:
a. P (A,B,B), P (x, y, z).
b. Q(y,G(A,B)), Q(G(x, x), y).
c. Older(Father (y), y), Older(Father (x), John).
d. Knows(Father (y), y), Knows(x, x).
9.5 Consider the subsumption lattices shown in Figure 9.2 (page 329).
a. Construct the lattice for the sentence Employs(Mother (John),Father (Richard)).
b. Construct the lattice for the sentence Employs(IBM , y) (“Everyone works for IBM”). Remember to include every kind of query that unifies with the sentence.
c. Assume that STORE indexes each sentence under every node in its subsumption lattice. Explain how FETCH should work when some of these sentences contain variables; use as examples the sentences in (a) and (b) and the query Employs(x,Father (x)).
9.6 Write down logical representations for the following sentences, suitable for use with Generalized Modus Ponens:
a. Horses, cows, and pigs are mammals.
b. An offspring of a horse is a horse.
c. Bluebeard is a horse.
d. Bluebeard is Charlie’s parent.
e. Offspring and parent are inverse relations.
f. Every mammal has a parent.
9.7 These questions concern concern issues with substitution and Skolemization.
a. Given the premise ∀x ∃ y P (x, y), it is not valid to conclude that ∃ q P (q, q). Give an example of a predicate P where the first is true but the second is false.
b. Suppose that an inference engine is incorrectly written with the occurs check omitted, so that it allows a literal like P (x, F (x)) to be unified with P (q, q). (As mentioned, most standard implementations of Prolog actually do allow this.) Show that such an inference engine will allow the conclusion ∃ y P (q, q) to be inferred from the premise ∀x ∃ y P (x, y).
c. Suppose that a procedure that converts first-order logic to clausal form incorrectly Skolemizes ∀x ∃ y P (x, y) to P (x, Sk0)—that is, it replaces y by a Skolem constant rather than by a Skolem function of x. Show that an inference engine that uses such a procedure will likewise allow ∃ q P (q, q) to be inferred from the premise ∀x ∃ y P (x, y).
d. A common error among students is to suppose that, in unification, one is allowed to substitute a term for a Skolem constant instead of for a variable. For instance, they will say that the formulas P (Sk1) and P (A) can be unified under the substitution {Sk1/A}. Give an example where this leads to an invalid inference.
9.8 Explain how to write any given 3-SAT problem of arbitrary size using a single first-order definite clause and no more than 30 ground facts.
9.9 Suppose you are given the following axioms:
- 0 ≤ 3.
- 7 ≤ 9.
- ∀x x ≤ x.
- ∀x x ≤ x + 0.
- ∀x x + 0 ≤ x.
- ∀x, y x + y ≤ y + x.
- ∀w, x, y, z w ≤ y ∧ x ≤ z ⇒ w + x ≤ y + z.
- ∀x, y, z x ≤ y ∧ y ≤ z ⇒ x ≤ z
a. Give a backward-chaining proof of the sentence 7 ≤ 3 + 9. (Be sure, of course, to use only the axioms given here, not anything else you may know about arithmetic.) Show only the steps that leads to success, not the irrelevant steps.
b. Give a forward-chaining proof of the sentence 7 ≤ 3 + 9. Again, show only the steps that lead to success.
9.10 A popular children’s riddle is “Brothers and sisters have I none, but that man’s father is my father’s son.” Use the rules of the family domain (Section 8.3.2 on page 301) to show who that man is. You may apply any of the inference methods described in this chapter. Why do you think that this riddle is difficult?
9.11 Suppose we put into a logical knowledge base a segment of the U.S. census data listing the age, city of residence, date of birth, and mother of every person, using social security numbers as identifying constants for each person. Thus, George’s age is given by Age(443-65-1282, 56). Which of the following indexing schemes s~1~–S5 enable an efficient solution for which of the queries Q~1~–Q4 (assuming normal backward chaining)?
-
s~1~: an index for each atom in each position.
-
s~2~: an index for each first argument.
-
S~3~: an index for each predicate atom.
-
S~4~: an index for each combination of predicate and first argument.
-
S~5~: an index for each combination of predicate and second argument and an index for each first argument.
-
Q~1~: Age(443-44-4321, x)
-
Q~2~: ResidesIn(x,Houston)
-
Q~3~: Mother (x, y)
-
Q~4~: Age(x, 34) ∧ ResidesIn(x,TinyTownUSA)
9.12 One might suppose that we can avoid the problem of variable conflict in unification during backward chaining by standardizing apart all of the sentences in the knowledge base once and for all. Show that, for some sentences, this approach cannot work. (Hint: Consider a sentence in which one part unifies with another.)
9.13 In this exercise, use the sentences you wrote in Exercise 9.6 to answer a question by using a backward-chaining algorithm.
a. Draw the proof tree generated by an exhaustive backward-chaining algorithm for the query ∃h Horse(h), where clauses are matched in the order given.
b. What do you notice about this domain?
c. How many solutions for h actually follow from your sentences?
d. Can you think of a way to find all of them? (Hint: See Smith et al. (1986).)
9.14 Trace the execution of the backward-chaining algorithm in Figure 9.6 (page 338) when it is applied to solve the crime problem (page 330). Show the sequence of values taken on by the goals variable, and arrange them into a tree.
9.15 The following Prolog code defines a predicate P. (Remember that uppercase terms are variables, not constants, in Prolog.)
P(X,[X|Y]). P(X,[Y|Z]) :- P(X,Z).
a. Show proof trees and solutions for the queries P(A,[2,1,3]) and P(2,[1,A,3]).
b. What standard list operation does P represent?
9.16 This exercise looks at sorting in Prolog.
a. Write Prolog clauses that define the predicate sorted(L), which is true if and only if list L is sorted in ascending order.
b. Write a Prolog definition for the predicate perm(L,M), which is true if and only if L is a permutation of M.
c. Define sort(L,M) (M is a sorted version of L) using perm and sorted.
d. Run sort on longer and longer lists until you lose patience. What is the time complexity of your program?
e. Write a faster sorting algorithm, such as insertion sort or quicksort, in Prolog.
9.17 This exercise looks at the recursive application of rewrite rules, using logic programming. A rewrite rule (or demodulator in OTTER terminology) is an equation with a specified direction. For example, the rewrite rule x + 0 → x suggests replacing any expression that matches x+0 with the expression x. Rewrite rules are a key component of equational reasoning systems. Use the predicate rewrite(X,Y) to represent rewrite rules. For example, the earlier rewrite rule is written as rewrite(X+0,X). Some terms are primitive and cannot be further simplified; thus, we write primitive(0) to say that 0 is a primitive term.
a. Write a definition of a predicate simplify(X,Y), that is true when Y is a simplified version of X—that is, when no further rewrite rules apply to any subexpression of Y.
b. Write a collection of rules for the simplification of expressions involving arithmetic operators, and apply your simplification algorithm to some sample expressions.
c. Write a collection of rewrite rules for symbolic differentiation, and use them along with your simplification rules to differentiate and simplify expressions involving arithmetic expressions, including exponentiation.
9.18 This exercise considers the implementation of search algorithms in Prolog. Suppose that successor(X,Y) is true when state Y is a successor of state X; and that goal(X) is true when X is a goal state. Write a definition for solve(X,P), which means that P is a path (list of states) beginning with X, ending in a goal state, and consisting of a sequence of legal steps as defined by successor. You will find that depth-first search is the easiest way to do this. How easy would it be to add heuristic search control?
9.19 Suppose a knowledge base contains just the following first-order Horn clauses:
Ancestor(Mother(x), x) Ancestor(x, y) ∧ Ancestor(y, z) ⇒ Ancestor(x, z)
Consider a forward chaining algorithm that, on the jth iteration, terminates if the KB contains a sentence that unifies with the query, else adds to the KB every atomic sentence that can be inferred from the sentences already in the KB after iteration j − 1.
a. For each of the following queries, say whether the algorithm will (1) give an answer (if so, write down that answer); or (2) terminate with no answer; or (3) never terminate.
(i) Ancestor(Mother(y), John)
(ii) Ancestor(Mother(Mother(y)), John)
(iii) Ancestor(Mother(Mother(Mother(y))),Mother(y))
(iv) Ancestor(Mother(John),Mother(Mother(John)))
b. Can a resolution algorithm prove the sentence ¬Ancestor(John, John) from the original knowledge base? Explain how, or why not.
c. Suppose we add the assertion that ¬(Mother(x)= x) and augment the resolution algorithm with inference rules for equality. Now what is the answer to (b)?
9.20 LetL be the first-order language with a single predicate S(p, q), meaning “p shaves q.” Assume a domain of people.
a. Consider the sentence “There exists a person P who shaves every one who does not shave themselves, and only people that do not shave themselves.” Express this in L.
b. Convert the sentence in (a) to clausal form.
c. Construct a resolution proof to show that the clauses in (b) are inherently inconsistent. (Note: you do not need any additional axioms.)
9.21 How can resolution be used to show that a sentence is valid? Unsatisfiable?
9.22 Construct an example of two clauses that can be resolved together in two different ways giving two different outcomes.
9.23 From “Horses are animals,” it follows that “The head of a horse is the head of an animal.” Demonstrate that this inferencis valid by carrying out the following steps:
a. Translate the premise and the conclusion into the language of first-order logic. Use three predicates: HeadOf (h, x) (meaning “h is the head of x”), Horse(x), and Animal(x).
b. Negate the conclusion, and convert the premise and the negated conclusion into conjunctive normal form.
c. Use resolution to show that the conclusion follows from the premise.
9.24 Here are two sentences in the language of first-order logic:
(A) ∀ x ∃ y (x ≥ y)
(B) ∃ y ∀ x (x ≥ y)
a. Assume that the variables range over all the natural numbers 0, 1, 2, . . . ,∞ and that the “≥” predicate means “is greater than or equal to.” Under this interpretation, translate (A) and (B) into English.
b. Is (A) true under this interpretation?
c. Is (B) true under this interpretation?
d. Does (A) logically entail (B)?
e. Does (B) logically entail (A)?
f. Using resolution, try to prove that (A) follows from (B). Do this even if you think that (B) does not logically entail (A); continue until the proof breaks down and you cannot proceed (if it does break down). Show the unifying substitution for each resolution step. If the proof fails, explain exactly where, how, and why it breaks down.
g. Now try to prove that (B) follows from (A).
9.25 Resolution can produce nonconstructive proofs for queries with variables, so we had to introduce special mechanisms to extract definite answers. Explain why this issue does not arise with knowledge bases containing only definite clauses.
9.26 We said in this chapter that resolution cannot be used to generate all logical consequences of a set of sentences. Can any algorithm do this?
CLASSICAL PLANNING
In which we see how an agent can take advantage of the structure of a problem to construct complex plans of action.
We have defined AI as the study of rational action, which means that planning—devising a plan of action to achieve one’s goals—is a critical part of AI. We have seen two examples of planning agents so far: the search-based problem-solving agent of Chapter 3 and the hybrid logical agent of Chapter 7. In this chapter we introduce a representation for planning problems that scales up to problems that could not be handled by those earlier approaches.
Section 10.1 develops an expressive yet carefully constrained language for representing planning problems. Section 10.2 shows how forward and backward search algorithms can take advantage of this representation, primarily through accurate heuristics that can be derived automatically from the structure of the representation. (This is analogous to the way in which effective domain-independent heuristics were constructed for constraint satisfaction problems in Chapter 6.) Section 10.3 shows how a data structure called the planning graph can make the search for a plan more efficient. We then describe a few of the other approaches to planning, and conclude by comparing the various approaches.
This chapter covers fully observable, deterministic, static environments with single agents. Chapters 11 and 17 cover partially observable, stochastic, dynamic environments with multiple agents.
DEFINITION OF CLASSICAL PLANNING
The problem-solving agent of Chapter 3 can find sequences of actions that result in a goal state. But it deals with atomic representations of states and thus needs good domain-specific heuristics to perform well. The hybrid propositional logical agent of Chapter 7 can find plans without domain-specific heuristics because it uses domain-independent heuristics based on the logical structure of the problem. But it relies on ground (variable-free) propositional inference, which means that it may be swamped when there are many actions and states. For example, in the wumpus world, the simple action of moving a step forward had to be repeated for all four agent orientations, T time steps, and n^2^ current locations.
In response to this, planning researchers have settled on a factored representation— one in which a state of the world is represented by a collection of variables. We use a language called PDDL, the Planning Domain Definition Language, that allows us to express all 4Tn^2^ actions with one action schema. There have been several versions of PDDL; we select a simple version and alter its syntax to be consistent with the rest of the book.1 We now show how PDDL describes the four things we need to define a search problem: the initial state, the actions that are available in a state, the result of applying an action, and the goal test.
Each state is represented as a conjunction of fluents that are ground, functionless atoms. For example, Poor ∧ Unknown might represent the state of a hapless agent, and a state in a package delivery problem might be At(Truck~1~,Melbourne) ∧ At(Truck~2~,Sydney). Database semantics is used: the closed-world assumption means that any fluents that are not mentioned are false, and the unique names assumption means that Truck~1~ and Truck~2~ are distinct. The following fluents are not allowed in a state: At(x, y) (because it is non-ground), ¬Poor (because it is a negation), and At(Father (Fred ),Sydney) (because it uses a function symbol). The representation of states is carefully designed so that a state can be treated either as a conjunction of fluents, which can be manipulated by logical inference, or as a set of fluents, which can be manipulated with set operations. The set semantics is sometimes easier to deal with.
Actions are described by a set of action schemas that implicitly define the ACTIONS(s) and RESULT(s, a) functions needed to do a problem-solving search. We saw in Chapter 7 that any system for action description needs to solve the frame problem—to say what changes and what stays the same as the result of the action. Classical planning concentrates on problems where most actions leave most things unchanged. Think of a world consisting of a bunch of objects on a flat surface. The action of nudging an object causes that object to change its location by a vector Δ. A concise description of the action should mention only Δ; it shouldn’t have to mention all the objects that stay in place. PDDL does that by specifying the result of an action in terms of what changes; everything that stays the same is left unmentioned.
A set of ground (variable-free) actions can be represented by a single action schema. The schema is a lifted representation—it lifts the level of reasoning from propositional logic to a restricted subset of first-order logic. For example, here is an action schema for flying a plane from one location to another:
Action(Fly(p, from , to),
PRECOND:At(p, from) ∧ Plane(p) ∧ Airport(from) ∧ Airport(to)
EFFECT:¬At(p, from) ∧ At(p, to))
The schema consists of the action name, a list of all the variables used in the schema, a precondition and an effect. Although we haven’t said yet how the action schema converts into logical sentences, think of the variables as being universally quantified. We are free to choose whatever values we want to instantiate the variables. For example, here is one ground
1 PDDL was derived from the original STRIPS planning language(Fikes and Nilsson, 1971). which is slightly more restricted than PDDL: STRIPS preconditions and goals cannot contain negative literals.
action that results from substituting values for all the variables:
Action(Fly(P~1~,SFO , JFK ),
PRECOND:At(P~1~,SFO) ∧ Plane(P~1~) ∧ Airport(SFO) ∧ Airport(JFK )
EFFECT:¬At(P~1~,SFO) ∧ At(P~1~, JFK ))
The precondition and effect of an action are each conjunctions of literals (positive or negated atomic sentences). The precondition defines the states in which the action can be executed, and the effect defines the result of executing the action. An action a can be executed in state s if s entails the precondition of a. Entailment can also be expressed with the set semantics: s |= q iff every positive literal in q is in s and every negated literal in q is not. In formal notation we say
(a ∈ ACTIONS(s)) ⇔ s |= PRECOND(a) ,
where any variables in a are universally quantified. For example,
∀ p, from, to (Fly(p, from , to) ∈ ACTIONS(s)) ⇔
s |= (At(p, from) ∧ Plane(p) ∧Airport(from) ∧ Airport(to))
We say that action a is applicable in state s if the preconditions are satisfied by s. WhenAPPLICABLE
an action schema a contains variables, it may have multiple applicable instantiations. For example, with the initial state defined in Figure 10.1, the Fly action can be instantiated as Fly(P~1~,SFO , JFK ) or as Fly(p~2~, JFK ,SFO), both of which are applicable in the initial state. If an action a has v variables, then, in a domain with k unique names of objects, it takes O(v^k^) time in the worst case to find the applicable ground actions.
Sometimes we want to propositionalize a PDDL problem—replace each action scheme with a set of ground actions and then use a propositional solver such as SATP~LAN~ to find a solution. However, this is impractical when v and k are large.
The result of executing action a in state s is defined as a state s ′ which is represented by the set of fluents formed by starting with s, removing the fluents that appear as negative literals in the action’s effects (what we call the delete list or DEL(a)), and adding the fluentsDELETE LIST
that are positive literals in the action’s effects (what we call the add list or ADD(a)):
RESULT(s, a) = (s− DEL(a))∪ ADD(a) . (10.1)
For example, with the action Fly(P~1~,SFO , JFK ), we would remove At(P~1~,SFO) and add At(P~1~, JFK ). It is a requirement of action schemas that any variable in the effect must also appear in the precondition. That way, when the precondition is matched against the state s, all the variables will be bound, and RESULT(s, a) will therefore have only ground atoms. In other words, ground states are closed under the RESULT operation.
Also note that the fluents do not explicitly refer to time, as they did in Chapter 7. There we needed superscripts for time, and successor-state axioms of the form
F^t+1^ ⇔ ActionCausesF^t^ ∨ (F^t^ ∧ ¬ActionCausesNotF^t^ ) .
In PDDL the times and states are implicit in the action schemas: the precondition always refers to time t and the effect to time t + 1.
A set of action schemas serves as a definition of a planning domain. A specific problem within the domain is defined with the addition of an initial state and a goal. The initial
Init(At(C~1~, SFO) ∧ At(C~2~, JFK ) ∧ At(P~1~, SFO) ∧ At(p~2~, JFK )
∧ Cargo(C~1~) ∧ Cargo(C~2~) ∧ Plane(P~1~) ∧ Plane(p~2~)
∧ Airport(JFK ) ∧ Airport(SFO))
Goal (At(C~1~, JFK ) ∧ At(C~2~, SFO))
Action(Load(c, p, a),
PRECOND: At(c, a) ∧ At(p, a) ∧ Cargo(c) ∧ Plane(p) ∧ Airport(a)
EFFECT: ¬ At(c, a) ∧ In(c, p))
Action(Unload(c, p, a),
PRECOND: In(c, p) ∧ At(p, a) ∧ Cargo(c) ∧ Plane(p) ∧ Airport(a)
EFFECT: At(c, a) ∧ ¬ In(c, p))
Action(Fly(p, from , to),
PRECOND: At(p, from) ∧ Plane(p) ∧ Airport(from) ∧ Airport(to)
EFFECT: ¬ At(p, from) ∧ At(p, to))
Figure 10.1 A PDDL description of an air cargo transportation planning problem.
state is a conjunction of ground atoms. (As with all states, the closed-world assumption is used, which means that any atoms that are not mentioned are false.) The goal is just like a precondition: a conjunction of literals (positive or negative) that may contain variables, such as At(p,SFO) ∧ Plane(p). Any variables are treated as existentially quantified, so this goal is to have any plane at SFO. The problem is solved when we can find a sequence of actions that end in a state s that entails the goal. For example, the state Rich ∧ Famous ∧ Miserable entails the goal Rich ∧ Famous , and the state Plane(Plane~1~) ∧ At(Plane~1~,SFO) entails the goal At(p,SFO) ∧ Plane(p).
Now we have defined planning as a search problem: we have an initial state, an function, a RESULT function, and a goal test. We’ll look at some example problems before investigating efficient search algorithms.
Example: Air cargo transport
Figure 10.1 shows an air cargo transport problem involving loading and unloading cargo and flying it from place to place. The problem can be defined with three actions: Load , Unload , and Fly . The actions affect two predicates: In(c, p) means that cargo c is inside plane p, and At(x, a) means that object x (either plane or cargo) is at airport a. Note that some care must be taken to make sure the At predicates are maintained properly. When a plane flies from one airport to another, all the cargo inside the plane goes with it. In first-order logic it would be easy to quantify over all objects that are inside the plane. But basic PDDL does not have a universal quantifier, so we need a different solution. The approach we use is to say that a piece of cargo ceases to be At anywhere when it is In a plane; the cargo only becomes At the new airport when it is unloaded. So At really means “available for use at a given location.” The following plan is a solution to the problem:
[Load (C~1~, P~1~,SFO),Fly(P~1~,SFO , JFK ),Unload (C~1~, P~1~, JFK ), Load (C~2~, p~2~, JFK ),Fly(p~2~, JFK ,SFO),Unload (C~2~, p~2~,SFO)] .
Finally, there is the problem of spurious actions such as Fly(P~1~, JFK , JFK ), which should be a no-op, but which has contradictory effects (according to the definition, the effect would include At(P~1~, JFK ) ∧ ¬At(P~1~, JFK )). It is common to ignore such problems, because they seldom cause incorrect plans to be produced. The correct approach is to add inequality preconditions saying that the from and to airports must be different; see another example of this in Figure 10.3.
Example: The spare tire problem
Consider the problem of changing a flat tire (Figure 10.2). The goal is to have a good spare tire properly mounted onto the car’s axle, where the initial state has a flat tire on the axle and a good spare tire in the trunk. To keep it simple, our version of the problem is an abstract one, with no sticky lug nuts or other complications. There are just four actions: removing the spare from the trunk, removing the flat tire from the axle, putting the spare on the axle, and leaving the car unattended overnight. We assume that the car is parked in a particularly bad neighborhood, so that the effect of leaving it overnight is that the tires disappear. A solution to the problem is [Remove(Flat ,Axle),Remove(Spare ,Trunk ),PutOn(Spare ,Axle)].
Init(Tire(Flat) ∧ Tire(Spare) ∧ At(Flat ,Axle) ∧ At(Spare,Trunk))
Goal(At(Spare,Axle))
Action(Remove(obj , loc),
PRECOND: At(obj , loc)
EFFECT: ¬ At(obj , loc) ∧ At(obj ,Ground))
Action(PutOn(t , Axle),
PRECOND: Tire(t) ∧ At(t ,Ground) ∧ ¬ At(Flat ,Axle)
EFFECT: ¬ At(t ,Ground) ∧ At(t ,Axle))
Action(LeaveOvernight ,
PRECOND: EFFECT: ¬ At(Spare,Ground) ∧ ¬ At(Spare,Axle) ∧ ¬ At(Spare,Trunk)
∧ ¬ At(Flat ,Ground) ∧ ¬ At(Flat ,Axle) ∧ ¬ At(Flat , Trunk))
Figure 10.2 The simple spare tire problem.
Example: The blocks world
One of the most famous planning domains is known as the blocks world. This domain consists of a set of cube-shaped blocks sitting on a table.2 The blocks can be stacked, but only one block can fit directly on top of another. A robot arm can pick up a block and move it to another position, either on the table or on top of another block. The arm can pick up only one block at a time, so it cannot pick up a block that has another one on it. The goal will always be to build one or more stacks of blocks, specified in terms of what blocks are on top
2 The blocks world used in planning research is much simpler than SHRDLU’s version, shown on page 20.
Init(On(A,Table) ∧ On(B,Table) ∧ On(C, A)
∧ Block (A) ∧ Block (B) ∧ Block (C) ∧ Clear (B) ∧ Clear (C))
Goal (On(A, B) ∧ On(B, C))
Action(Move(b, x, y),
PRECOND: On(b, x) ∧ Clear (b) ∧ Clear (y) ∧ Block (b) ∧ Block (y) ∧
(b ≠x) ∧ (b ≠y) ∧ (x≠y),
EFFECT: On(b, y) ∧ Clear (x) ∧ ¬On(b, x) ∧ ¬Clear (y))
Action(MoveToTable(b, x),
PRECOND: On(b, x) ∧ Clear (b) ∧ Block (b) ∧ (b ≠x),
EFFECT: On(b,Table) ∧ Clear (x) ∧ ¬On(b, x))
Figure 10.3 A planning problem in the blocks world: building a three-block tower. One solution is the sequence [MoveToTable(C, A),Move(B,Table , C),Move(A,Table , B)].
of what other blocks. For example, a goal might be to get block A on B and block B on C (see Figure 10.4).
We use On(b, x) to indicate that block b is on x, where x is either another block or the table. The action for moving block b from the top of x to the top of y will be Move(b, x, y). Now, one of the preconditions on moving b is that no other block be on it. In first-order logic, this would be ¬∃x On(x, b) or, alternatively, ∀x ¬On(x, b). Basic PDDL does not allow quantifiers, so instead we introduce a predicate Clear(x) that is true when nothing is on x. (The complete problem description is in Figure 10.3.)
The action Move moves a block b from x to y if both b and y are clear. After the move is made, b is still clear but y is not. A first attempt at the Move schema is
Action(Move(b, x, y),
PRECOND:On(b, x) ∧ Clear(b) ∧ Clear(y),
EFFECT:On(b, y) ∧ Clear(x) ∧ ¬On(b, x) ∧ ¬Clear(y)) .
Unfortunately, this does not maintain Clear properly when x or y is the table. When x is the Table , this action has the effect Clear(Table), but the table should not become clear; and when y =Table , it has the precondition Clear(Table), but the table does not have to be clear for us to move a block onto it. To fix this, we do two things. First, we introduce another action to move a block b from x to the table:
Action(MoveToTable(b, x),
PRECOND:On(b, x) ∧ Clear(b),
EFFECT:On(b,Table) ∧ Clear(x) ∧ ¬On(b, x)) .
Second, we take the interpretation of Clear(x) to be “there is a clear space on x to hold a block.” Under this interpretation, Clear(Table) will always be true. The only problem is that nothing prevents the planner from using Move(b, x,Table) instead of MoveToTable(b, x). We could live with this problem—it will lead to a larger-than-necessary search space, but will not lead to incorrect answers—or we could introduce the predicate Block and add Block(b) ∧ Block(y) to the precondition of Move.
The complexity of classical planning
In this subsection we consider the theoretical complexity of planning and distinguish two decision problems. PlanSAT is the question of whether there exists any plan that solves a planning problem. Bounded PlanSAT asks whether there is a solution of length k or less; this can be used to find an optimal plan. \
The first result is that both decision problems are decidable for classical planning. The proof follows from the fact that the number of states is finite. But if we add function symbols to the language, then the number of states becomes infinite, and PlanSAT becomes only semidecidable: an algorithm exists that will terminate with the correct answer for any solvable problem, but may not terminate on unsolvable problems. The Bounded PlanSAT problem remains decidable even in the presence of function symbols. For proofs of the assertions in this section, see Ghallab et al. (2004).
Both PlanSAT and Bounded PlanSAT are in the complexity class PSPACE, a class that is larger (and hence more difficult) than NP and refers to problems that can be solved by a deterministic Turing machine with a polynomial amount of space. Even if we make some rather severe restrictions, the problems remain quite difficult. For example, if we disallow negative effects, both problems are still NP-hard. However, if we also disallow negative preconditions, PlanSAT reduces to the class P.
These worst-case results may seem discouraging. We can take solace in the fact that agents are usually not asked to find plans for arbitrary worst-case problem instances, but rather are asked for plans in specific domains (such as blocks-world problems with n blocks), which can be much easier than the theoretical worst case. For many domains (including the blocks world and the air cargo world), Bounded PlanSAT is NP-complete while PlanSAT is in P; in other words, optimal planning is usually hard, but sub-optimal planning is sometimes easy. To do well on easier-than-worst-case problems, we will need good search heuristics. That’s the true advantage of the classical planning formalism: it has facilitated the development of very accurate domain-independent heuristics, whereas systems based on successorstate axioms in first-order logic have had less success in coming up with good heuristics.
ALGORITHMS FOR PLANNING AS STATE-SPACE SEARCH
Now we turn our attention to planning algorithms. We saw how the description of a planning problem defines a search problem: we can search from the initial state through the space of states, looking for a goal. One of the nice advantages of the declarative representation of action schemas is that we can also search backward from the goal, looking for the initial state. Figure 10.5 compares forward and backward searches.
Forward (progression) state-space search
Now that we have shown how a planning problem maps into a search problem, we can solve planning problems with any of the heuristic search algorithms from Chapter 3 or a local search algorithm from Chapter 4 (provided we keep track of the actions used to reach the goal). From the earliest days of planning research (around 1961) until around 1998 it was assumed that forward state-space search was too inefficient to be practical. It is not hard to come up with reasons why.
First, forward search is prone to exploring irrelevant actions. Consider the noble task of buying a copy of AI: A Modern Approach from an online bookseller. Suppose there is an
action schema Buy(isbn) with effect Own(isbn). ISBNs are 10 digits, so this action schema represents 10 billion ground actions. An uninformed forward-search algorithm would have to start enumerating these 10 billion actions to find one that leads to the goal.
Second, planning problems often have large state spaces. Consider an air cargo problem with 10 airports, where each airport has 5 planes and 20 pieces of cargo. The goal is to move all the cargo at airport A to airport B. There is a simple solution to the problem: load the 20 pieces of cargo into one of the planes at A, fly the plane to B, and unload the cargo. Finding the solution can be difficult because the average branching factor is huge: each of the 50 planes can fly to 9 other airports, and each of the 200 packages can be either unloaded (if it is loaded) or loaded into any plane at its airport (if it is unloaded). So in any state there is a minimum of 450 actions (when all the packages are at airports with no planes) and a maximum of 10,450 (when all packages and planes are at the same airport). On average, let’s say there are about 2000 possible actions per state, so the search graph up to the depth of the obvious solution has about 2000^41^ nodes.
Clearly, even this relatively small problem instance is hopeless without an accurate heuristic. Although many real-world applications of planning have relied on domain-specific heuristics, it turns out (as we see in Section 10.2.3) that strong domain-independent heuristics can be derived automatically; that is what makes forward search feasible.
Backward (regression) relevant-states search
In regression search we start at the goal and apply the actions backward until we find a sequence of steps that reaches the initial state. It is called relevant-states search because we only consider actions that are relevant to the goal (or current state). As in belief-state search (Section 4.4), there is a set of relevant states to consider at each step, not just a single state.
We start with the goal, which is a conjunction of literals forming a description of a set of states—for example, the goal ¬Poor ∧Famous describes those states in which Poor is false, Famous is true, and any other fluent can have any value. If there are n ground fluents in a domain, then there are 2^n^ ground states (each fluent can be true or false), but 3n descriptions of sets of goal states (each fluent can be positive, negative, or not mentioned).
In general, backward search works only when we know how to regress from a state description to the predecessor state description. For example, it is hard to search backwards for a solution to the n-queens problem because there is no easy way to describe the states that are one move away from the goal. Happily, the PDDL representation was designed to make it easy to regress actions—if a domain can be expressed in PDDL, then we can do regression search on it. Given a ground goal description g and a ground action a, the regression from g over a gives us a state description g ′ defined by
g′ = (g − ADD(a)) ∪ Precond(a) .
That is, the effects that were added by the action need not have been true before, and also the preconditions must have held before, or else the action could not have been executed. Note that DEL(a) does not appear in the formula; that’s because while we know the fluents in DEL(a) are no longer true after the action, we don’t know whether or not they were true before, so there’s nothing to be said about them.
To get the full advantage of backward search, we need to deal with partially uninstantiated actions and states, not just ground ones. For example, suppose the goal is to deliver a specific piece of cargo to SFO: At(C~2~,SFO). That suggests the action Unload(C~2~, p′ ,SFO):
Action(Unload(C~2~, p ′,SFO)), PRECOND:In(C~2~, p ′) ∧ At(p′,SFO) ∧ Cargo(C~2~) ∧ Plane(p′) ∧ Airport(SFO) EFFECT:At(C~2~,SFO) ∧ ¬In(C~2~, p ′) .
(Note that we have standardized variable names (changing p to p ′ in this case) so that there will be no confusion between variable names if we happen to use the same action schema twice in a plan. The same approach was used in Chapter 9 for first-order logical inference.) This represents unloading the package from an unspecified plane at SFO; any plane will do, but we need not say which one now. We can take advantage of the power of first-order representations: a single description summarizes the possibility of using any of the planes by implicitly quantifying over p′. The regressed state description is
g′ = In(C~2~, p′ ) ∧ At(p′,SFO) ∧ Cargo(C~2~) ∧ Plane(p′ ) ∧ Airport(SFO) .
The final issue is deciding which actions are candidates to regress over. In the forward direction we chose actions that were applicable—those actions that could be the next step in the plan. In backward search we want actions that are relevant—those actions that could be the last step in a plan leading up to the current goal state. For an action to be relevant to a goal it obviously must contribute to the goal: at least
one of the action’s effects (either positive or negative) must unify with an element of the goal. What is less obvious is that the action must not have any effect (positive or negative) that negates an element of the goal. Now, if the goal is A ∧ B ∧ C and an action has the effect A∧B∧¬C then there is a colloquial sense in which that action is very relevant to the goal—it gets us two-thirds of the way there. But it is not relevant in the technical sense defined here, because this action could not be the final step of a solution—we would always need at least one more step to achieve C .
Given the goal At(C~2~,SFO), several instantiations of Unload are relevant: we could chose any specific plane to unload from, or we could leave the plane unspecified by using the action Unload(C~2~ p′,SFO). We can reduce the branching factor without ruling out any solutions by always using the action formed by substituting the most general unifier into the (standardized) action schema.
As another example, consider the goal Own(0136042597), given an initial state with 10 billion ISBNs, and the single action schema
A = Action(Buy(i), PRECOND:ISBN (i), EFFECT:Own(i)) .
As we mentioned before, forward search without a heuristic would have to start enumerating the 10 billion ground Buy actions. But with backward search, we would unify the goal Own(0136042597) with the (standardized) effect Own(i′), yielding the substitution θ = {i′/0136042597}. Then we would regress over the action Subst(θ,A′) to yield the predecessor state description ISBN (0136042597). This is part of, and thus entailed by, the initial state, so we are done.
We can make this more formal. Assume a goal description g which contains a goal literal gi and an action schema A that is standardized to produce A′. If A ′ has an effect literal e′j where Unify(gi, e′j)= θ and where we define a ′ = SUBST(θ,A′) and if there is no effect in a′ that is the negation of a literal in g, then a ′ is a relevant action towards g.
Backward search keeps the branching factor lower than forward search, for most problem domains. However, the fact that backward search uses state sets rather than individual states makes it harder to come up with good heuristics. That is the main reason why the majority of current systems favor forward search.
Heuristics for planning
Neither forward nor backward search is efficient without a good heuristic function. Recall from Chapter 3 that a heuristic function h(s) estimates the distance from a state s to the goal and that if we can derive an admissible heuristic for this distance—one that does not overestimate—then we can use A∗ search to find optimal solutions. An admissible heuristic can be derived by defining a relaxed problem that is easier to solve. The exact cost of a solution to this easier problem then becomes the heuristic for the original problem.
By definition, there is no way to analyze an atomic state, and thus it it requires some ingenuity by a human analyst to define good domain-specific heuristics for search problems with atomic states. Planning uses a factored representation for states and action schemas. That makes it possible to define good domain-independent heuristics and for programs to automatically apply a good domain-independent heuristic for a given problem.
Think of a search problem as a graph where the nodes are states and the edges are actions. The problem is to find a path connecting the initial state to a goal state. There are two ways we can relax this problem to make it easier: by adding more edges to the graph, making it strictly easier to find a path, or by grouping multiple nodes together, forming an abstraction of the state space that has fewer states, and thus is easier to search.
We look first at heuristics that add edges to the graph. For example, the ignore preconditions heuristic drops all preconditions from actions. Every action becomes applicable in every state, and any single goal fluent can be achieved in one step (if there is an applicable action—if not, the problem is impossible). This almost implies that the number of steps required to solve the relaxed problem is the number of unsatisfied goals—almost but not quite, because (1) some action may achieve multiple goals and (2) some actions may undo the effects of others. For many problems an accurate heuristic is obtained by considering (1) and ignoring (2). First, we relax the actions by removing all preconditions and all effects except those that are literals in the goal. Then, we count the minimum number of actions required such that the union of those actions’ effects satisfies the goal. This is an instance of the set-cover problem. There is one minor irritation: the set-cover problem is NP-hard.
Fortunately a simple greedy algorithm is guaranteed to return a set covering whose size is within a factor of log n of the true minimum covering, where n is the number of literals in the goal. Unfortunately, the greedy algorithm loses the guarantee of admissibility.
It is also possible to ignore only selected preconditions of actions. Consider the slidingblock puzzle (8-puzzle or 15-puzzle) from Section 3.2. We could encode this as a planning
problem involving tiles with a single schema Slide:
Action(Slide(t, s~1~, s~2~),
PRECOND:On(t, s~1~) ∧ Tile(t) ∧ Blank (s~2~) ∧ Adjacent(s~1~, s~2~)
EFFECT:On(t, s~2~) ∧ Blank(s~1~) ∧ ¬On(t, s~1~) ∧ ¬Blank(s~2~))
As we saw in Section 3.6, if we remove the preconditions Blank (s~2~) ∧ Adjacent(s~1~, s~2~) then any tile can move in one action to any space and we get the number-of-misplaced-tiles heuristic. If we remove Blank(s~2~) then we get the Manhattan-distance heuristic. It is easy to see how these heuristics could be derived automatically from the action schema description. The ease of manipulating the schemas is the great advantage of the factored representation of planning problems, as compared with the atomic representation of search problems.
Another possibility is the ignore delete lists heuristic. Assume for a moment that allgoals and preconditions contain only positive literals3 We want to create a relaxed version of the original problem that will be easier to solve, and where the length of the solution will serve as a good heuristic. We can do that by removing the delete lists from all actions (i.e., removing all negative literals from effects). That makes it possible to make monotonic progress towards the goal—no action will ever undo progress made by another action. It turns out it is still NPhard to find the optimal solution to this relaxed problem, but an approximate solution can be found in polynomial time by hill-climbing. Figure 10.6 diagrams part of the state space for two planning problems using the ignore-delete-lists heuristic. The dots represent states and the edges actions, and the height of each dot above the bottom plane represents the heuristic value. States on the bottom plane are solutions. In both these problems, there is a wide path to the goal. There are no dead ends, so no need for backtracking; a simple hillclimbing search will easily find a solution to these problems (although it may not be an optimal solution).
The relaxed problems leave us with a simplified—but still expensive—planning problem just to calculate the value of the heuristic function. Many planning problems have 10^100^ states or more, and relaxing the actions does nothing to reduce the number of states. Therefore, we now look at relaxations that decrease the number of states by forming a state abstraction—a many-to-one mapping from states in the ground representation of the problem to the abstract representation.
The easiest form of state abstraction is to ignore some fluents. For example, consider an air cargo problem with 10 airports, 50 planes, and 200 pieces of cargo. Each plane can be at one of 10 airports and each package can be either in one of the planes or unloaded at one of the airports. So there are 50^10^ × 200^50+10^ ≈ 10^155^ states. Now consider a particular problem in that domain in which it happens that all the packages are at just 5 of the airports, and all packages at a given airport have the same destination. Then a useful abstraction of the problem is to drop all the At fluents except for the ones involving one plane and one package at each of the 5 airports. Now there are only 5^10^ × 5^5+10^ ≈ 10^17^ states. A solution in this abstract state space will be shorter than a solution in the original space (and thus will be an admissible heuristic), and the abstract solution is easy to extend to a solution to the original problem (by adding additional Load and Unload actions).
3 Many problems are written with this convention. For problems that aren’t, replace every negative literal ¬P
in a goal or precondition with a new positive literal, P ′.
A key idea in defining heuristics is decomposition: dividing a problem into parts, solving each part independently, and then combining the parts. The subgoal independence assumption is that the cost of solving a conjunction of subgoals is approximated by the sum of the costs of solving each subgoal independently. The subgoal independence assumption can be optimistic or pessimistic. It is optimistic when there are negative interactions between the subplans for each subgoal—for example, when an action in one subplan deletes a goal achieved by another subplan. It is pessimistic, and therefore inadmissible, when subplans contain redundant actions—for instance, two actions that could be replaced by a single action in the merged plan.
Suppose the goal is a set of fluents G, which we divide into disjoint subsets G~1~, . . . , G~n~. We then find plans P~1~, . . . , p~n~ that solve the respective subgoals. What is an estimate of the cost of the plan for achieving all of G? We can think of each Cost(p~i~) as a heuristic estimate, and we know that if we combine estimates by taking their maximum value, we always get an admissible heuristic. So maxi COST(p~i~) is admissible, and sometimes it is exactly correct: it could be that P~1~ serendipitously achieves all the G~i~. But in most cases, in practice the estimate is too low. Could we sum the costs instead? For many problems that is a reasonable estimate, but it is not admissible. The best case is when we can determine that G~i~ and G~j~ are independent. If the effects of p~i~ leave all the preconditions and goals of P~j~ unchanged, then the estimate COST(p~i~) + COST(P~j~) is admissible, and more accurate than the max estimate. We show in Section 10.3.1 that planning graphs can help provide better heuristic estimates.
It is clear that there is great potential for cutting down the search space by forming abstractions. The trick is choosing the right abstractions and using them in a way that makes the total cost—defining an abstraction, doing an abstract search, and mapping the abstraction back to the original problem—less than the cost of solving the original problem. The techniques of pattern databases from Section 3.6.3 can be useful, because the cost of creating the pattern database can be amortized over multiple problem instances.
An example of a system that makes use of effective heuristics is FF, or FASTFORWARD (Hoffmann, 2005), a forward state-space searcher that uses the ignore-delete-lists heuristic, estimating the heuristic with the help of a planning graph (see Section 10.3). FF then uses hill-climbing search (modified to keep track of the plan) with the heuristic to find a solution. When it hits a plateau or local maximum—when no action leads to a state with better heuristic score—then FF uses iterative deepening search until it finds a state that is better, or it gives up and restarts hill-climbing.
PLANNING GRAPHS
All of the heuristics we have suggested can suffer from inaccuracies. This section shows how a special data structure called a planning graph can be used to give better heuristic estimates. These heuristics can be applied to any of the search techniques we have seen so far. Alternatively, we can search for a solution over the space formed by the planning graph, using an algorithm called GRAPHPLAN.
A planning problem asks if we can reach a goal state from the initial state. Suppose we are given a tree of all possible actions from the initial state to successor states, and their successors, and so on. If we indexed this tree appropriately, we could answer the planning question “can we reach state G from state S~0~” immediately, just by looking it up. Of course, the tree is of exponential size, so this approach is impractical. A planning graph is polynomialsize approximation to this tree that can be constructed quickly. The planning graph can’t answer definitively whether G is reachable from S~0~, but it can estimate how many steps it takes to reach G. The estimate is always correct when it reports the goal is not reachable, and it never overestimates the number of steps, so it is an admissible heuristic.
A planning graph is a directed graph organized into levels: first a level S~0~ for the initial state, consisting of nodes representing each fluent that holds in S~0~; then a level A~0~ consisting of nodes for each ground action that might be applicable in S~0~; then alternating levels S~i~
followed by A~i~; until we reach a termination condition (to be discussed later). Roughly speaking, S~i~ contains all the literals that could hold at time i, depending on
the actions executed at preceding time steps. If it is possible that either P or ¬P could hold, then both will be represented in S~i~. Also roughly speaking, A~i~ contains all the actions that could have their preconditions satisfied at time i. We say “roughly speaking” because the planning graph records only a restricted subset of the possible negative interactions among actions; therefore, a literal might show up at level S~j~ when actually it could not be true until a later level, if at all. (A literal will never show up too late.) Despite the possible error, the level j at which a literal first appears is a good estimate of how difficult it is to achieve the literal from the initial state.
Planning graphs work only for propositional planning problems—ones with no variables. As we mentioned on page 368, it is straightforward to propositionalize a set of ac
Init(Have(Cake))
Goal (Have(Cake) ∧ Eaten(Cake))
Action(Eat(Cake)
PRECOND: Have(Cake)
EFFECT: ¬ Have(Cake) ∧ Eaten(Cake))
Action(Bake(Cake)
PRECOND: ¬ Have(Cake)
EFFECT: Have(Cake))
Figure 10.7 The “have cake and eat cake too” problem.
tion schemas. Despite the resulting increase in the size of the problem description, planning graphs have proved to be effective tools for solving hard planning problems.
Figure 10.7 shows a simple planning problem, and Figure 10.8 shows its planning graph. Each action at level A~i~ is connected to its preconditions at S~i~ and its effects at S~i+1~. So a literal appears because an action caused it, but we also want to say that a literal can persist if no action negates it. This is represented by a persistence action (sometimes called a no-op). For every literal C , we add to the problem a persistence action with precondition C and effect C . Level A~0~ in Figure 10.8 shows one “real” action, Eat(Cake), along with two persistence actions drawn as small square boxes.
Level A~0~ contains all the actions that could occur in state S~0~, but just as important it records conflicts between actions that would prevent them from occurring together. The gray lines in Figure 10.8 indicate mutual exclusion (or mutex) links. For example, Eat(Cake) is mutually exclusive with the persistence of either Have(Cake) or ¬Eaten(Cake). We shall see shortly how mutex links are computed.
Level s~1~ contains all the literals that could result from picking any subset of the actions in A~0~, as well as mutex links (gray lines) indicating literals that could not appear together, regardless of the choice of actions. For example, Have(Cake) and Eaten(Cake) are mutex:
depending on the choice of actions in A~0~, either, but not both, could be the result. In other words, s~1~ represents a belief state: a set of possible states. The members of this set are all subsets of the literals such that there is no mutex link between any members of the subset.
We continue in this way, alternating between state level Si and action level Ai until we reach a point where two consecutive levels are identical. At this point, we say that the graph has leveled off. The graph in Figure 10.8 levels off at s~2~.
What we end up with is a structure where every A~i~ level contains all the actions that are applicable in S~i~, along with constraints saying that two actions cannot both be executed at the same level. Every S~i~ level contains all the literals that could result from any possible choice of actions in A~i−1~, along with constraints saying which pairs of literals are not possible. It is important to note that the process of constructing the planning graph does not require choosing among actions, which would entail combinatorial search. Instead, it just records the impossibility of certain choices using mutex links.
We now define mutex links for both actions and literals. A mutex relation holds between two actions at a given level if any of the following three conditions holds:
-
Inconsistent effects: one action negates an effect of the other. For example, Eat(Cake) and the persistence of Have(Cake) have inconsistent effects because they disagree on the effect Have(Cake).
-
Interference: one of the effects of one action is the negation of a precondition of the other. For example Eat(Cake) interferes with the persistence of Have(Cake) by negating its precondition.
-
Competing needs: one of the preconditions of one action is mutually exclusive with a precondition of the other. For example, Bake(Cake) and Eat(Cake) are mutex because they compete on the value of the Have(Cake) precondition.
A mutex relation holds between two literals at the same level if one is the negation of the other or if each possible pair of actions that could achieve the two literals is mutually exclusive. This condition is called inconsistent support. For example, Have(Cake) and Eaten(Cake) are mutex in s~1~ because the only way of achieving Have(Cake), the persistence action, is mutex with the only way of achieving Eaten(Cake), namely Eat(Cake). In s~2~ the two literals are not mutex, because there are new ways of achieving them, such as Bake(Cake) and the persistence of Eaten(Cake), that are not mutex.
A planning graph is polynomial in the size of the planning problem. For a planning problem with l literals and a actions, each Si has no more than l nodes and l^2^ mutex links, and each Ai has no more than a + l nodes (including the no-ops), (a + l)^2^ mutex links, and 2(al + l) precondition and effect links. Thus, an entire graph with n levels has a size of O(n(a + l)^2^). The time to build the graph has the same complexity.
Planning graphs for heuristic estimation
A planning graph, once constructed, is a rich source of information about the problem. First, if any goal literal fails to appear in the final level of the graph, then the problem is unsolvable. Second, we can estimate the cost of achieving any goal literal gi from state s as the level at which gi first appears in the planning graph constructed from initial state s. We call this the level cost of gi. In Figure 10.8, Have(Cake) has level cost 0 and Eaten(Cake) has level costLEVEL COST
- It is easy to show (Exercise 10.10) that these estimates are admissible for the individual goals. The estimate might not always be accurate, however, because planning graphs allow several actions at each level, whereas the heuristic counts just the level and not the number of actions. For this reason, it is common to use a serial planning graph for computing heuristics. A serial graph insists that only one action can actually occur at any given time step; this is done by adding mutex links between every pair of nonpersistence actions. Level costs extracted from serial graphs are often quite reasonable estimates of actual costs.
To estimate the cost of a conjunction of goals, there are three simple approaches. The max-level heuristic simply takes the maximum level cost of any of the goals; this is admissible, but not necessarily accurate.
The level sum heuristic, following the subgoal independence assumption, returns the sum of the level costs of the goals; this can be inadmissible but works well in practice for problems that are largely decomposable. It is much more accurate than the numberof-unsatisfied-goals heuristic from Section 10.2. For our problem, the level-sum heuristic estimate for the conjunctive goal Have(Cake) ∧ Eaten(Cake) will be 0 + 1 = 1, whereas the correct answer is 2, achieved by the plan [Eat(Cake),Bake(Cake)]. That doesn’t seem so bad. A more serious error is that if Bake(Cake) were not in the set of actions, then the estimate would still be 1, when in fact the conjunctive goal would be impossible.
Finally, the set-level heuristic finds the level at which all the literals in the conjunctive goal appear in the planning graph without any pair of them being mutually exclusive. This heuristic gives the correct values of 2 for our original problem and infinity for the problem without Bake(Cake). It is admissible, it dominates the max-level heuristic, and it works extremely well on tasks in which there is a good deal of interaction among subplans. It is not perfect, of course; for example, it ignores interactions among three or more literals.
As a tool for generating accurate heuristics, we can view the planning graph as a relaxed problem that is efficiently solvable. To understand the nature of the relaxed problem, we need to understand exactly what it means for a literal g to appear at level Si in the planning graph. Ideally, we would like it to be a guarantee that there exists a plan with i action levels that achieves g, and also that if g does not appear, there is no such plan. Unfortunately, making that guarantee is as difficult as solving the original planning problem. So the planning graph makes the second half of the guarantee (if g does not appear, there is no plan), but if g does appear, then all the planning graph promises is that there is a plan that possibly achieves g and has no “obvious” flaws. An obvious flaw is defined as a flaw that can be detected by considering two actions or two literals at a time—in other words, by looking at the mutex relations. There could be more subtle flaws involving three, four, or more actions, but experience has shown that it is not worth the computational effort to keep track of these possible flaws. This is similar to a lesson learned from constraint satisfaction problems—that it is often worthwhile to compute 2-consistency before searching for a solution, but less often worthwhile to compute 3-consistency or higher. (See page 211.)
One example of an unsolvable problem that cannot be recognized as such by a planning graph is the blocks-world problem where the goal is to get block A on B, B on C , and C on A. This is an impossible goal; a tower with the bottom on top of the top. But a planning graph cannot detect the impossibility, because any two of the three subgoals are achievable. There are no mutexes between any pair of literals, only between the three as a whole. To detect that this problem is impossible, we would have to search over the planning graph.
The GRAPHPLAN algorithm
This subsection shows how to extract a plan directly from the planning graph, rather than just using the graph to provide a heuristic. The GRAPHPLAN algorithm (Figure 10.9) repeatedly adds a level to a planning graph with EXPAND-GRAPH. Once all the goals show up as nonmutex in the graph, GRAPHPLAN calls EXTRACT-SOLUTION to search for a plan that solves the problem. If that fails, it expands another level and tries again, terminating with failure when there is no reason to go on.
function GRAPHPLAN(problem) returns solution or failure
graph← INITIAL-PLANNING-GRAPH(problem) goals←CONJUNCTS(problem .GOAL) nogoods← an empty hash table for tl = 0 to∞ do
if goals all non-mutex in St of graph then solution←EXTRACT-SOLUTION(graph , goals , NUMLEVELS(graph), nogoods) if solution ≠ failure then return solution
if graph and nogoods have both leveled off then return failure
graph← EXPAND-GRAPH(graph , problem)
Figure 10.9 The GRAPHPLAN algorithm. GRAPHPLAN calls EXPAND-GRAPH to add a level until either a solution is found by EXTRACT-SOLUTION, or no solution is possible.
Let us now trace the operation of GRAPHPLAN on the spare tire problem from page 370. The graph is shown in Figure 10.10. The first line of GRAPHPLAN initializes the planning graph to a one-level (S~0~) graph representing the initial state. The positive fluents from the problem description’s initial state are shown, as are the relevant negative fluents. Not shown are the unchanging positive literals (such as Tire(Spare)) and the irrelevant negative literals. The goal At(Spare ,Axle) is not present in S~0~, so we need not call EXTRACT-SOLUTION— we are certain that there is no solution yet. Instead, EXPAND-GRAPH adds into A~0~ the three actions whose preconditions exist at level S~0~ (i.e., all the actions except PutOn(Spare ,Axle)), along with persistence actions for all the literals in S~0~. The effects of the actions are added at level s~1~. EXPAND-GRAPH then looks for mutex relations and adds them to the graph.
At(Spare ,Axle) is still not present in s~1~, so again we do not call EXTRACT-SOLUTION. We call EXPAND-GRAPH again, adding A~1~ and s~1~ and giving us the planning graph shown in Figure 10.10. Now that we have the full complement of actions, it is worthwhile to look at some of the examples of mutex relations and their causes:
- Inconsistent effects: Remove(Spare ,Trunk ) is mutex with LeaveOvernight because one has the effect At(Spare ,Ground) and the other has its negation.
-
Interference: Remove(Flat ,Axle) is mutex with LeaveOvernight because one has the precondition At(Flat ,Axle) and the other has its negation as an effect.
-
Competing needs: PutOn(Spare ,Axle) is mutex with Remove(Flat ,Axle) because one has At(Flat ,Axle) as a precondition and the other has its negation.
-
Inconsistent support: At(Spare ,Axle) is mutex with At(Flat ,Axle) in s~2~ because the only way of achieving At(Spare ,Axle) is by PutOn(Spare ,Axle), and that is mutex with the persistence action that is the only way of achieving At(Flat ,Axle). Thus, the mutex relations detect the immediate conflict that arises from trying to put two objects in the same place at the same time.
This time, when we go back to the start of the loop, all the literals from the goal are present in s~2~, and none of them is mutex with any other. That means that a solution might exist, and EXTRACT-SOLUTION will try to find it. We can formulate EXTRACT-SOLUTION as a Boolean constraint satisfaction problem (CSP) where the variables are the actions at each level, the values for each variable are in or out of the plan, and the constraints are the mutexes and the need to satisfy each goal and precondition.
Alternatively, we can define EXTRACT-SOLUTION as a backward search problem, where each state in the search contains a pointer to a level in the planning graph and a set of unsatisfied goals. We define this search problem as follows:
-
The initial state is the last level of the planning graph, S~n~, along with the set of goals from the planning problem.
-
The actions available in a state at level S~i~ are to select any conflict-free subset of the actions in A~i−1~ whose effects cover the goals in the state. The resulting state has level S~i−1~ and has as its set of goals the preconditions for the selected set of actions. By “conflict free,” we mean a set of actions such that no two of them are mutex and no two of their preconditions are mutex.
-
The goal is to reach a state at level S~0~ such that all the goals are satisfied.
-
The cost of each action is 1.
For this particular problem, we start at s~2~ with the goal At(Spare ,Axle). The only choice we have for achieving the goal set is PutOn(Spare ,Axle). That brings us to a search state at s~1~ with goals At(Spare ,Ground) and ¬At(Flat ,Axle). The former can be achieved only by Remove(Spare ,Trunk), and the latter by either Remove(Flat ,Axle) or LeaveOvernight . But LeaveOvernight is mutex with Remove(Spare ,Trunk ), so the only solution is to choose Remove(Spare ,Trunk) and Remove(Flat ,Axle). That brings us to a search state at S~0~ with the goals At(Spare ,Trunk) and At(Flat ,Axle). Both of these are present in the state, so we have a solution: the actions Remove(Spare , Trunk) and Remove(Flat , Axle) in level A~0~, followed by PutOn(Spare , Axle) in A~1~.
In the case where EXTRACT-SOLUTION fails to find a solution for a set of goals at a given level, we record the (level , goals) pair as a no-good, just as we did in constraint learning for CSPs (page 220). Whenever EXTRACT-SOLUTION is called again with the same level and goals, we can find the recorded no-good and immediately return failure rather than searching again. We see shortly that no-goods are also used in the termination test.
We know that planning is PSPACE-complete and that constructing the planning graph takes polynomial time, so it must be the case that solution extraction is intractable in the worst case. Therefore, we will need some heuristic guidance for choosing among actions during the backward search. One approach that works well in practice is a greedy algorithm based on the level cost of the literals. For any set of goals, we proceed in the following order:
- Pick first the literal with the highest level cost.
- To achieve that literal, prefer actions with easier preconditions. That is, choose an action such that the sum (or maximum) of the level costs of its preconditions is smallest.
Termination of GRAPHPLAN
So far, we have skated over the question of termination. Here we show that GRAPHPLAN will in fact terminate and return failure when there is no solution.
The first thing to understand is why we can’t stop expanding the graph as soon as it has leveled off. Consider an air cargo domain with one plane and n pieces of cargo at airport A, all of which have airport B as their destination. In this version of the problem, only one piece of cargo can fit in the plane at a time. The graph will level off at level 4, reflecting the fact that for any single piece of cargo, we can load it, fly it, and unload it at the destination in three steps. But that does not mean that a solution can be extracted from the graph at level 4; in fact a solution will require 4n − 1 steps: for each piece of cargo we load, fly, and unload, and for all but the last piece we need to fly back to airport A to get the next piece.
How long do we have to keep expanding after the graph has leveled off? If the function EXTRACT-SOLUTION fails to find a solution, then there must have been at least one set of goals that were not achievable and were marked as a no-good. So if it is possible that there might be fewer no-goods in the next level, then we should continue. As soon as the graph itself and the no-goods have both leveled off, with no solution found, we can terminate with failure because there is no possibility of a subsequent change that could add a solution.
Now all we have to do is prove that the graph and the no-goods will always level off. The key to this proof is that certain properties of planning graphs are monotonically increasing or decreasing. “X increases monotonically” means that the set of Xs at level i + 1 is a superset (not necessarily proper) of the set at level i. The properties are as follows:
-
Literals increase monotonically: Once a literal appears at a given level, it will appear at all subsequent levels. This is because of the persistence actions; once a literal shows up, persistence actions cause it to stay forever.
-
Actions increase monotonically: Once an action appears at a given level, it will appear at all subsequent levels. This is a consequence of the monotonic increase of literals; if the preconditions of an action appear at one level, they will appear at subsequent levels, and thus so will the action.
-
Mutexes decrease monotonically: If two actions are mutex at a given level Ai, then they will also be mutex for all previous levels at which they both appear. The same holds for mutexes between literals. It might not always appear that way in the figures, because the figures have a simplification: they display neither literals that cannot hold at level S~i~ nor actions that cannot be executed at level A~i~. We can see that “mutexes decrease monotonically” is true if you consider that these invisible literals and actions are mutex with everything.
The proof can be handled by cases: if actions A and B are mutex at level A~i~, it must be because of one of the three types of mutex. The first two, inconsistent effects and interference, are properties of the actions themselves, so if the actions are mutex at A~i~, they will be mutex at every level. The third case, competing needs, depends on conditions at level S~i~: that level must contain a precondition of A that is mutex with a precondition of B. Now, these two preconditions can be mutex if they are negations of each other (in which case they would be mutex in every level) or if all actions for achieving one are mutex with all actions for achieving the other. But we already know that the available actions are increasing monotonically, so, by induction, the mutexes must be decreasing.
- No-goods decrease monotonically: If a set of goals is not achievable at a given level, then they are not achievable in any previous level. The proof is by contradiction: if they were achievable at some previous level, then we could just add persistence actions to make them achievable at a subsequent level.
Because the actions and literals increase monotonically and because there are only a finite number of actions and literals, there must come a level that has the same number of actions and literals as the previous level. Because mutexes and no-goods decrease, and because there can never be fewer than zero mutexes or no-goods, there must come a level that has the same number of mutexes and no-goods as the previous level. Once a graph has reached this state, then if one of the goals is missing or is mutex with another goal, then we can stop the GRAPHPLAN algorithm and return failure. That concludes a sketch of the proof; for more details see Ghallab et al. (2004).

OTHER CLASSICAL PLANNING APPROACHES
Currently the most popular and effective approaches to fully automated planning are:
-
Translating to a Boolean satisfiability (SAT) problem
-
Forward state-space search with carefully crafted heuristics (Section 10.2)
-
Search using a planning graph (Section 10.3)
These three approaches are not the only ones tried in the 40-year history of automated planning. Figure 10.11 shows some of the top systems in the International Planning Competitions, which have been held every even year since 1998. In this section we first describe the translation to a satisfiability problem and then describe three other influential approaches: planning as first-order logical deduction; as constraint satisfaction; and as plan refinement.
Classical planning as Boolean satisfiability
In Section 7.7.4 we saw how SATP~LAN~ solves planning problems that are expressed in propositional logic. Here we show how to translate a PDDL description into a form that can be processed by SATP~LAN~. The translation is a series of straightforward steps:
-
Propositionalize the actions: replace each action schema with a set of ground actions formed by substituting constants for each of the variables. These ground actions are not part of the translation, but will be used in subsequent steps.
-
Define the initial state: assert F^0^ for every fluent F in the problem’s initial state, and ¬F for every fluent not mentioned in the initial state.
-
Propositionalize the goal: for every variable in the goal, replace the literals that contain the variable with a disjunction over constants. For example, the goal of having block A on another block, On(A,x) ∧ Block(x) in a world with objects A,B and C , would be replaced by the goal
(On(A,A) ∧ Block (A)) ∨ (On(A,B) ∧ Block (B)) ∨ (On(A,C) ∧ Block (C)) .
- Add successor-state axioms: For each fluent F , add an axiom of the form
F^t+1^ ⇔ ActionCausesF^t^ ∨ (F^t^ ∧ ¬ActionCausesNotF^t^ ) ,
where ActionCausesF is a disjunction of all the ground actions that have F in their add list, and ActionCausesNotF is a disjunction of all the ground actions that have F
in their delete list.
-
Add precondition axioms: For each ground action A, add the axiom A^t^ ⇒ PRE(A)^t^, that is, if an action is taken at time t, then the preconditions must have been true.
-
Add action exclusion axioms: say that every action is distinct from every other action.
The resulting translation is in the form that we can hand to SATP~LAN~ to find a solution.
Planning as first-order logical deduction: Situation calculus
PDDL is a language that carefully balances the expressiveness of the language with the com- plexity of the algorithms that operate on it. But some problems remain difficult to express in PDDL. For example, we can’t express the goal “move all the cargo from A to B regardless of how many pieces of cargo there are” in PDDL, but we can do it in first-order logic, using a universal quantifier. Likewise, first-order logic can concisely express global constraints such as “no more than four robots can be in the same place at the same time.” PDDL can only say this with repetitious preconditions on every possible action that involves a move.
The propositional logic representation of planning problems also has limitations, such as the fact that the notion of time is tied directly to fluents. For example, South~2~ means “the agent is facing south at time 2.” With that representation, there is no way to say “the agent would be facing south at time 2 if it executed a right turn at time 1; otherwise it would be facing east.” First-order logic lets us get around this limitation by replacing the notion of linear time with a notion of branching situations, using a representation called situation calculus that works like this:
-
The initial state is called a situation. If s is a situation and a is an action, then RESULT(s, a) is also a situation. There are no other situations. Thus, a situation corresponds to a sequence, or history, of actions. You can also think of a situation as the result of applying the actions, but note that two situations are the same only if their start and actions are the same: (RESULT(s, a) = RESULT(s′, a′)) ⇔ (s = s′ ∧ a = a ′). Some examples of actions and situations are shown in Figure 10.12.
-
A function or relation that can vary from one situation to the next is a fluent. By convention, the situation s is always the last argument to the fluent, for example At(x, l, s) is a relational fluent that is true when object x is at location l in situation s, and Location is a functional fluent such that Location(x, s) = l holds in the same situations as At(x, l, s).
-
Each action’s preconditions are described with a possibility axiom that says when the action can be taken. It has the form Φ(s) ⇒ Poss(a, s) where Φ(s) is some formula
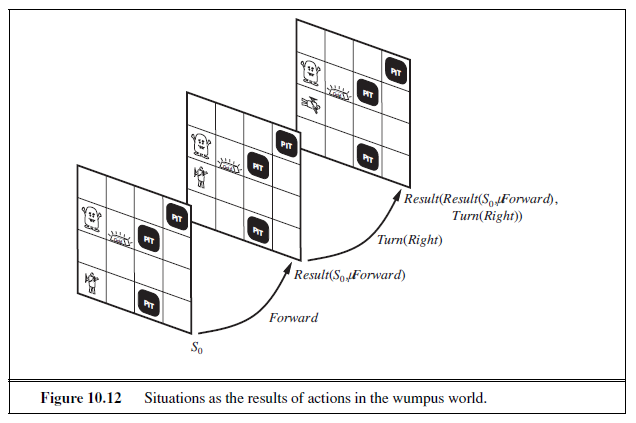
involving s that describes the preconditions. An example from the wumpus world says that it is possible to shoot if the agent is alive and has an arrow:
Alive(Agent , s) ∧ Have(Agent ,Arrow , s) ⇒ Poss(Shoot , s)
- Each fluent is described with a successor-state axiom that says what happens to the fluent, depending on what action is taken. This is similar to the approach we took for propositional logic. The axiom has the form
Action is possible ⇒ (Fluent is true in result state ⇔ Action’s effect made it true
∨ It was true before and action left it alone) .
For example, the axiom for the relational fluent Holding says that the agent is holding some gold g after executing a possible action if and only if the action was a Grab of g or if the agent was already holding g and the action was not releasing it:
Poss(a, s) ⇒
(Holding(Agent , g,Result (a, s)) ⇔
a= Grab(g) ∨ (Holding(Agent , g, s) ∧ a ≠ Release(g))) .
- We need unique action axioms so that the agent can deduce that, for example, a ≠ Release(g). For each distinct pair of action names A~i~ and A~j~ we have an axiom that says the actions are different:
A~i~(x, . . .) ≠ A~j~(y, . . .)
and for each action name A~i~ we have an axiom that says two uses of that action name are equal if and only if all their arguments are equal:
A~i~(X~1~, . . . , X~n~)= A~i~(y~1~, . . . , y~n~) ⇔ X~1~ = y~1~ ∧ . . . ∧ X~n~ = y~n~ .
- A solution is a situation (and hence a sequence of actions) that satisfies the goal.
Work in situation calculus has done a lot to define the formal semantics of planning and to open up new areas of investigation. But so far there have not been any practical large-scale planning programs based on logical deduction over the situation calculus. This is in part because of the difficulty of doing efficient inference in FOL, but is mainly because the field has not yet developed effective heuristics for planning with situation calculus.
Planning as constraint satisfaction
We have seen that constraint satisfaction has a lot in common with Boolean satisfiability, and we have seen that CSP techniques are effective for scheduling problems, so it is not surprising that it is possible to encode a bounded planning problem (i.e., the problem of finding a plan of length k) as a constraint satisfaction problem (CSP). The encoding is similar to the encoding to a SAT problem (Section 10.4.1), with one important simplification: at each time step we need only a single variable, Action^t^, whose domain is the set of possible actions. We no longer need one variable for every action, and we don’t need the action exclusion axioms. It is also possible to encode a planning graph into a CSP. This is the approach taken by GP-CSP (Do and Kambhampati, 2003).
Planning as refinement of partially ordered plans
All the approaches we have seen so far construct totally ordered plans consisting of a strictly linear sequences of actions. This representation ignores the fact that many subproblems are independent. A solution to an air cargo problem consists of a totally ordered sequence of actions, yet if 30 packages are being loaded onto one plane in one airport and 50 packages are being loaded onto another at another airport, it seems pointless to come up with a strict linear ordering of 80 load actions; the two subsets of actions should be thought of independently.
An alternative is to represent plans as partially ordered structures: a plan is a set of actions and a set of constraints of the form Before(ai, aj) saying that one action occurs before another. In the bottom of Figure 10.13, we see a partially ordered plan that is a solution to the spare tire problem. Actions are boxes and ordering constraints are arrows. Note that Remove(Spare ,Trunk) and Remove(Flat ,Axle) can be done in either order as long as they are both completed before the PutOn(Spare ,Axle) action.
Partially ordered plans are created by a search through the space of plans rather than through the state space. We start with the empty plan consisting of just the initial state and the goal, with no actions in between, as in the top of Figure 10.13. The search procedure then looks for a flaw in the plan, and makes an addition to the plan to correct the flaw (or if no correction can be made, the search backtracks and tries something else). A flaw is anything that keeps the partial plan from being a solution. For example, one flaw in the empty plan is that no action achieves At(Spare ,Axle). One way to correct the flaw is to insert into the plan
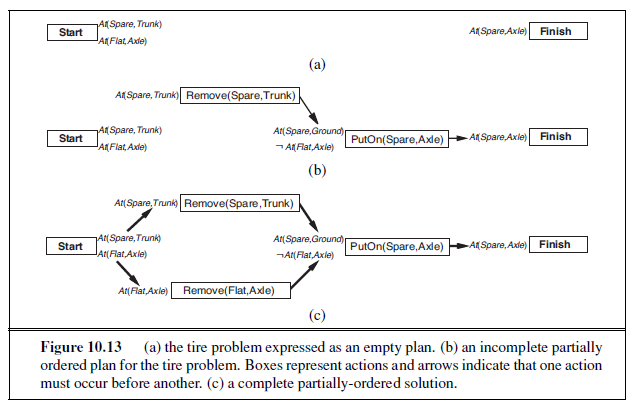
the action PutOn(Spare ,Axle). Of course that introduces some new flaws: the preconditions of the new action are not achieved. The search keeps adding to the plan (backtracking if necessary) until all flaws are resolved, as in the bottom of Figure 10.13. At every step, we make the least commitment possible to fix the flaw. For example, in adding the action Remove(Spare ,Trunk) we need to commit to having it occur before PutOn(Spare ,Axle), but we make no other commitment that places it before or after other actions. If there were a variable in the action schema that could be left unbound, we would do so.
In the 1980s and 90s, partial-order planning was seen as the best way to handle planning problems with independent subproblems—after all, it was the only approach that explicitly represents independent branches of a plan. On the other hand, it has the disadvantage of not having an explicit representation of states in the state-transition model. That makes some computations cumbersome. By 2000, forward-search planners had developed excellent heuristics that allowed them to efficiently discover the independent subproblems that partialorder planning was designed for. As a result, partial-order planners are not competitive on fully automated classical planning problems.
However, partial-order planning remains an important part of the field. For some specific tasks, such as operations scheduling, partial-order planning with domain specific heuristics is the technology of choice. Many of these systems use libraries of high-level plans, as described in Section 11.2. Partial-order planning is also often used in domains where it is important for humans to understand the plans. Operational plans for spacecraft and Mars rovers are generated by partialorder planners and are then checked by human operators before being uploaded to the vehicles for execution. The plan refinement approach makes it easier for the humans to understand what the planning algorithms are doing and verify that they are correct.
ANALYSIS OF PLANNING APPROACHES
Planning combines the two major areas of AI we have covered so far: search and logic. A planner can be seen either as a program that searches for a solution or as one that (constructively) proves the existence of a solution. The cross-fertilization of ideas from the two areas has led both to improvements in performance amounting to several orders of magnitude in the last decade and to an increased use of planners in industrial applications. Unfortunately, we do not yet have a clear understanding of which techniques work best on which kinds of problems. Quite possibly, new techniques will emerge that dominate existing methods.
Planning is foremost an exercise in controlling combinatorial explosion. If there are n propositions in a domain, then there are 2^n^ states. As we have seen, planning is PSPACEhard. Against such pessimism, the identification of independent subproblems can be a powerful weapon. In the best case—full decomposability of the problem—we get an exponential speedup. Decomposability is destroyed, however, by negative interactions between actions. GRAPHPLAN records mutexes to point out where the difficult interactions are. SATP~LAN~ represents a similar range of mutex relations, but does so by using the general CNF form rather than a specific data structure. Forward search addresses the problem heuristically by trying to find patterns (subsets of propositions) that cover the independent subproblems. Since this approach is heuristic, it can work even when the subproblems are not completely independent.
Sometimes it is possible to solve a problem efficiently by recognizing that negative interactions can be ruled out. We say that a problem has serializable subgoals if there exists an order of subgoals such that the planner can achieve them in that order without having to undo any of the previously achieved subgoals. For example, in the blocks world, if the goal is to build a tower (e.g., A on B, which in turn is on C , which in turn is on the Table , as in Figure 10.4 on page 371), then the subgoals are serializable bottom to top: if we first achieve C on Table , we will never have to undo it while we are achieving the other subgoals. A planner that uses the bottom-to-top trick can solve any problem in the blocks world without backtracking (although it might not always find the shortest plan).
As a more complex example, for the Remote Agent planner that commanded NASA’s Deep Space One spacecraft, it was determined that the propositions involved in commanding a spacecraft are serializable. This is perhaps not too surprising, because a spacecraft is designed by its engineers to be as easy as possible to control (subject to other constraints). Taking advantage of the serialized ordering of goals, the Remote Agent planner was able to eliminate most of the search. This meant that it was fast enough to control the spacecraft in real time, something previously considered impossible.
Planners such as GRAPHPLAN, SATP~LAN~, and FF have moved the field of planning forward, by raising the level of performance of planning systems, by clarifying the representational and combinatorial issues involved, and by the development of useful heuristics. However, there is a question of how far these techniques will scale. It seems likely that further progress on larger problems cannot rely only on factored and propositional representations, and will require some kind of synthesis of first-order and hierarchical representations with the efficient heuristics currently in use.
SUMMARY
In this chapter, we defined the problem of planning in deterministic, fully observable, static environments. We described the PDDL representation for planning problems and several algorithmic approaches for solving them. The points to remember:
-
Planning systems are problem-solving algorithms that operate on explicit propositional or relational representations of states and actions. These representations make possible the derivation of effective heuristics and the development of powerful and flexible algorithms for solving problems.
-
PDDL, the Planning Domain Definition Language, describes the initial and goal states as conjunctions of literals, and actions in terms of their preconditions and effects.
-
State-space search can operate in the forward direction (progression) or the backward direction (regression). Effective heuristics can be derived by subgoal independence assumptions and by various relaxations of the planning problem.
-
A planning graph can be constructed incrementally, starting from the initial state. Each layer contains a superset of all the literals or actions that could occur at that time step and encodes mutual exclusion (mutex) relations among literals or actions that cannot cooccur. Planning graphs yield useful heuristics for state-space and partial-order planners and can be used directly in the GRAPHPLAN algorithm.
-
Other approaches include first-order deduction over situation calculus axioms; encoding a planning problem as a Boolean satisfiability problem or as a constraint satisfaction problem; and explicitly searching through the space of partially ordered plans.
-
Each of the major approaches to planning has its adherents, and there is as yet no consensus on which is best. Competition and cross-fertilization among the approaches have resulted in significant gains in efficiency for planning systems.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
AI planning arose from investigations into state-space search, theorem proving, and control theory and from the practical needs of robotics, scheduling, and other domains. STRIPS (Fikes and Nilsson, 1971), the first major planning system, illustrates the interaction of these infleences. STRIPS was designed as the planning component of the software for the Shakey robot project at SRI. Its overall control structure was modeled on that of GPS, the General Problem Solver (Newell and Simon, 1961), a state-space search system that used means–ends analysis. Bylander (1992) shows simple STRIPS planning to be PSPACE-complete. Fikes and Nilsson (1993) give a historical retrospective on the STRIPS project and its relationship to more recent planning efforts.
The representation language used by STRIPS has been far more influential than its algorithmic approach; what we call the “classical” language is close to what STRIPS used.
The Action Description Language, or ADL (Pednault, 1986), relaxed some of the STRIPS restrictions and made it possible to encode more realistic problems. Nebel (2000) explores schemes for compiling ADL into STRIPS. The Problem Domain Description Language, or PDDL (Ghallab et al., 1998), was introduced as a computer-parsable, standardized syntax for representing planning problems and has been used as the standard language for the International Planning Competition since 1998. There have been several extensions; the most recent version, PDDL 3.0, includes plan constraints and preferences (Gerevini and Long, 2005).
Planners in the early 1970s generally considered totally ordered action sequences. Problem decomposition was achieved by computing a subplan for each subgoal and then stringing the subplans together in some order. This approach, called linear planning by Sacerdoti (1975), was soon discovered to be incomplete. It cannot solve some very simple problems, such as the Sussman anomaly (see Exercise 10.7), found by Allen Brown during experimentation with the HACKER system (Sussman, 1975). A complete planner must allow for interleaving of actions from different subplans within a single sequence. The notion of serializable subgoals (Korf, 1987) corresponds exactly to the set of problems for which noninterleaved planners are complete.
One solution to the interleaving problem was goal-regression planning, a technique in which steps in a totally ordered plan are reordered so as to avoid conflict between subgoals. This was introduced by Waldinger (1975) and also used by Warren’s (1974) WARPLAN. WARPLAN is also notable in that it was the first planner to be written in a logic programming language (Prolog) and is one of the best examples of the remarkable economy that can sometimes be gained with logic programming: WARPLAN is only 100 lines of code, a small fraction of the size of comparable planners of the time.
The ideas underlying partial-order planning include the detection of conflicts (Tate, 1975a) and the protection of achieved conditions from interference (Sussman, 1975). The construction of partially ordered plans (then called task networks) was pioneered by the NOAH planner (Sacerdoti, 1975, 1977) and by Tate’s (1975b, 1977) NONLIN system.
Partial-order planning dominated the next 20 years of research, yet the first clear formal exposition was TWEAK (Chapman, 1987), a planner that was simple enough to allow proofs of completeness and intractability (NP-hardness and undecidability) of various planning problems. Chapman’s work led to a straightforward description of a complete partialorder planner (McAllester and Rosenblitt, 1991), then to the widely distributed implementations SNLP (Soderland and Weld, 1991) and UCPOP (Penberthy and Weld, 1992). Partialorder planning fell out of favor in the late 1990s as faster methods emerged. Nguyen and Kambhampati (2001) suggest that a reconsideration is merited: with accurate heuristics derived from a planning graph, their REPOP planner scales up much better than GRAPHPLAN in parallelizable domains and is competitive with the fastest state-space planners. The resurgence of interest in state-space planning was pioneered by Drew McDermott’s UNPOP program (1996), which was the first to suggest the ignore-delete-list heuristic, The name UNPOP was a reaction to the overwhelming concentration on partial-order planning at the time; McDermott suspected that other approaches were not getting the attention they deserved. Bonet and Geffner’s Heuristic Search Planner (HSP) and its later derivatives (Bonet and Geffner, 1999; Haslum et al., 2005; Haslum, 2006) were the first to make state-space search practical for large planning problems. HSP searches in the forward direction while HSPR (Bonet and Geffner, 1999) searches backward. The most successful state-space searcher to date is FF (Hoffmann, 2001; Hoffmann and Nebel, 2001; Hoffmann, 2005), winner of the AIPS 2000 planning competition. FASTDOWNWARD (Helmert, 2006) is a forward state-space search planner that preprocesses the action schemas into an alternative representation which makes some of the constraints more explicit. (Helmert and Richter, 2004; Helmert, 2006) won the 2004 planning competition, and LAMA (Richter and Westphal, 2008), a planner based on FASTDOWNWARD with improved heuristics, won the 2008 competition.
Bylander (1994) and Ghallab et al. (2004) discuss the computational complexity of several variants of the planning problem. Helmert (2003) proves complexity bounds for many of the standard benchmark problems, and Hoffmann (2005) analyzes the search space of the ignore-delete-list heuristic. Heuristics for the set-covering problem are discussed by Caprara et al. (1995) for scheduling operations of the Italian railway. Edelkamp (2009) and Haslum et al. (2007) describe how to construct pattern databases for planning heuristics. As we mentioned in Chapter 3, Felner et al. (2004) show encouraging results using pattern databases for sliding blocks puzzles, which can be thought of as a planning domain, but Hoffmann et al. (2006) show some limitations of abstraction for classical planning problems.
Avrim Blum and Merrick Furst (1995, 1997) revitalized the field of planning with their GRAPHPLAN system, which was orders of magnitude faster than the partial-order planners of the time. Other graph-planning systems, such as IPP (Koehler et al., 1997), STAN (Fox and Long, 1998), and SGP (Weld et al., 1998), soon followed. A data structure closely resembling the planning graph had been developed slightly earlier by Ghallab and Laruelle (1994), whose IXTET partial-order planner used it to derive accurate heuristics to guide searches. Nguyen et al. (2001) thoroughly analyze heuristics derived from planning graphs. Our discussion of planning graphs is based partly on this work and on lecture notes and articles by Subbarao Kambhampati (Bryce and Kambhampati, 2007). As mentioned in the chapter, a planning graph can be used in many different ways to guide the search for a solution. The winner of the 2002 AIPS planning competition, LPG (Gerevini and Serina, 2002, 2003), searched planning graphs using a local search technique inspired by WALKSAT.
The situation calculus approach to planning was introduced by John McCarthy (1963). The version we show here was proposed by Ray Reiter (1991, 2001).
Kautz et al. (1996) investigated various ways to propositionalize action schemas, finding that the most compact forms did not necessarily lead to the fastest solution times. A systematic analysis was carried out by Ernst et al. (1997), who also developed an automatic “compiler” for generating propositional representations from PDDL problems. The BLACKBOX planner, which combines ideas from GRAPHPLAN and SATP~LAN~, was developed by Kautz and Selman (1998). CPLAN, a planner based on constraint satisfaction, was described by van Beek and Chen (1999).
Most recently, there has been interest in the representation of plans as binary decision diagrams, compact data structures for Boolean expressions widely studied in the hardware verification community (Clarke and Grumberg, 1987; McMillan, 1993). There are techniques for proving properties of binary decision diagrams, including the property of being a solution to a planning problem. Cimatti et al. (1998) present a planner based on this approach. Other representations have also been used; for example, Vossen et al. (2001) survey the use of integer programming for planning.
The jury is still out, but there are now some interesting comparisons of the various approaches to planning. Helmert (2001) analyzes several classes of planning problems, and shows that constraint-based approaches such as GRAPHPLAN and SATP~LAN~ are best for NPhard domains, while search-based approaches do better in domains where feasible solutions can be found without backtracking. GRAPHPLAN and SATP~LAN~ have trouble in domains with many objects because that means they must create many actions. In some cases the problem can be delayed or avoided by generating the propositionalized actions dynamically, only as needed, rather than instantiating them all before the search begins.
Readings in Planning (Allen et al., 1990) is a comprehensive anthology of early work in the field. Weld (1994, 1999) provides two excellent surveys of planning algorithms of the 1990s. It is interesting to see the change in the five years between the two surveys: the first concentrates on partial-order planning, and the second introduces GRAPHPLAN and SATP~LAN~. Automated Planning (Ghallab et al., 2004) is an excellent textbook on all aspects of planning. LaValle’s text Planning Algorithms (2006) covers both classical and stochastic planning, with extensive coverage of robot motion planning.
Planning research has been central to AI since its inception, and papers on planning are a staple of mainstream AI journals and conferences. There are also specialized conferences such as the International Conference on AI Planning Systems, the International Workshop on Planning and Scheduling for Space, and the European Conference on Planning.
EXERCISES
10.1 Describe the differences and similarities between problem solving and planning.
10.2 Given the action schemas and initial state from Figure 10.1, what are all the applicable concrete instances of Fly(p, from , to) in the state described by
At(P~1~, JFK ) ∧At(p~2~,SFO) ∧ Plane(P~1~) ∧ Plane(p~2~)
∧ Airport(JFK ) ∧ Airport(SFO) ?
10.3 The monkey-and-bananas problem is faced by a monkey in a laboratory with some bananas hanging out of reach from the ceiling. A box is available that will enable the monkey to reach the bananas if he climbs on it. Initially, the monkey is at A, the bananas at B, and the box at C . The monkey and box have height Low , but if the monkey climbs onto the box he will have height High, the same as the bananas. The actions available to the monkey include Go from one place to another, Push an object from one place to another, ClimbUp onto or ClimbDown from an object, and Grasp or Ungrasp an object. The result of a Grasp is that the monkey holds the object if the monkey and object are in the same place at the same height.
a. Write down the initial state description.
b. Write the six action schemas.
c. Suppose the monkey wants to fool the scientists, who are off to tea, by grabbing the bananas, but leaving the box in its original place. Write this as a general goal (i.e., not assuming that the box is necessarily at C) in the language of situation calculus. Can this goal be solved by a classical planning system?
d. Your schema for pushing is probably incorrect, because if the object is too heavy, its position will remain the same when the Push schema is applied. Fix your action schema to account for heavy objects.
10.4 The original STRIPS planner was designed to control Shakey the robot. Figure 10.14 shows a version of Shakey’s world consisting of four rooms lined up along a corridor, where each room has a door and a light switch. The actions in Shakey’s world include moving from place to place, pushing movable objects (such as boxes), climbing onto and down from rigid objects (such as boxes), and turning light switches on and off. The robot itself could not climb on a box or toggle a switch, but the planner was capable of finding and printing out plans that were beyond the robot’s abilities. Shakey’s six actions are the following:
-
Go(x, y, r), which requires that Shakey be At x and that x and y are locations In the same room r. By convention a door between two rooms is in both of them.
-
Push a box b from location x to location y within the same room: Push(b, x, y, r). You will need the predicate Box and constants for the boxes.
-
Climb onto a box from position x: ClimbUp(x, b); climb down from a box to position x: ClimbDown(b, x). We will need the predicate On and the constant Floor .
-
Turn a light switch on or off: TurnOn(s, b); TurnOff (s, b). To turn a light on or off, Shakey must be on top of a box at the light switch’s location.
Write PDDL sentences for Shakey’s six actions and the initial state from Figure 10.14. Construct a plan for Shakey to get Box 2 into Room2.
10.5 A finite Turing machine has a finite one-dimensional tape of cells, each cell containing one of a finite number of symbols. One cell has a read and write head above it. There is a finite set of states the machine can be in, one of which is the accept state. At each time step, depending on the symbol on the cell under the head and the machine’s current state, there are a set of actions we can choose from. Each action involves writing a symbol to the cell under the head, transitioning the machine to a state, and optionally moving the head left or right. The mapping that determines which actions are allowed is the Turing machine’s program. Your goal is to control the machine into the accept state.
Represent the Turing machine acceptance problem as a planning problem. If you can do this, it demonstrates that determining whether a planning problem has a solution is at least as hard as the Turing acceptance problem, which is PSPACE-hard.
10.6 Explain why dropping negative effects from every action schema in a planning problem results in a relaxed problem.
10.7 Figure 10.4 (page 371) shows a blocks-world problem that is known as the Sussman anomaly. The problem was considered anomalous because the noninterleaved planners of the early 1970s could not solve it. Write a definition of the problem and solve it, either by hand or with a planning program. A noninterleaved planner is a planner that, when given two subgoals G~1~ and G2, produces either a plan for G~1~ concatenated with a plan for G2, or vice versa. Explain why a noninterleaved planner cannot solve this problem.
10.8 Prove that backward search with PDDL problems is complete.
10.9 Construct levels 0, 1, and 2 of the planning graph for the problem in Figure 10.1.
10.10 Prove the following assertions about planning graphs:
a. A literal that does not appear in the final level of the graph cannot be achieved.
b. The level cost of a literal in a serial graph is no greater than the actual cost of an optimal plan for achieving it.
10.11 The set-level heuristic (see page 382) uses a planning graph to estimate the cost of achieving a conjunctive goal from the current state. What relaxed problem is the set-level heuristic the solution to?
10.12 Examine the definition of bidirectional search in Chapter 3.
a. Would bidirectional state-space search be a good idea for planning?
b. What about bidirectional search in the space of partial-order plans?
c. Devise a version of partial-order planning in which an action can be added to a plan if its preconditions can be achieved by the effects of actions already in the plan. Explain how to deal with conflicts and ordering constraints. Is the algorithm essentially identical to forward state-space search?
10.13 We contrasted forward and backward state-space searchers with partial-order planners, saying that the latter is a plan-space searcher. Explain how forward and backward statespace search can also be considered plan-space searchers, and say what the plan refinement operators are.
10.14 Up to now we have assumed that the plans we create always make sure that an action’s preconditions are satisfied. Let us now investigate what propositional successor-state axioms such as HaveArrow^t+1^ ⇔ (HaveArrow^t^ ∧ ¬Shoot^t^) have to say about actions whose preconditions are not satisfied.
a. Show that the axioms predict that nothing will happen when an action is executed in a state where its preconditions are not satisfied.
b. Consider a plan p that contains the actions required to achieve a goal but also includes illegal actions. Is it the case that
initial state ∧ successor-state axioms ∧ p |= goal ?
c. With first-order successor-state axioms in situation calculus, is it possible to prove that a plan containing illegal actions will achieve the goal?
10.15 Consider how to translate a set of action schemas into the successor-state axioms of situation calculus.
a. Consider the schema for Fly(p, from , to). Write a logical definition for the predicate Poss(Fly(p, from, to), s), which is true if the preconditions for Fly(p, from , to) are satisfied in situation s.
b. Next, assuming that Fly(p, from , to) is the only action schema available to the agent, write down a successor-state axiom for At(p, x, s) that captures the same information as the action schema.
c. Now suppose there is an additional method of travel: Teleport(p, from , to). It has the additional precondition ¬Warped(p) and the additional effect Warped(p). Explain how the situation calculus knowledge base must be modified.
d. Finally, develop a general and precisely specified procedure for carrying out the translation from a set of action schemas to a set of successor-state axioms.
10.16 In the SATP~LAN~ algorithm in Figure 7.22 (page 272), each call to the satisfiability algorithm asserts a goal g
T , where T ranges from 0 to T~max~. Suppose instead that the satisfiability algorithm is called only once, with the goal g^0^ ∨ g^1^ ∨ · · · ∨ g^T^~max~ .
a. Will this always return a plan if one exists with length less than or equal to Tmax?
b. Does this approach introduce any new spurious “solutions”?
c. Discuss how one might modify a satisfiability algorithm such as WALKSAT so that it finds short solutions (if they exist) when given a disjunctive goal of this form.
PLANNING AND ACTING IN THE REAL WORLD
In which we see how more expressive representations and more interactive agent architectures lead to planners that are useful in the real world.
The previous chapter introduced the most basic concepts, representations, and algorithms for planning. Planners that are are used in the real world for planning and scheduling the operations of spacecraft, factories, and military campaigns are more complex; they extend both the representation language and the way the planner interacts with the environment. This chapter shows how. Section 11.1 extends the classical language for planning to talk about actions with durations and resource constraints. Section 11.2 describes methods for constructing plans that are organized hierarchically. This allows human experts to communicate to the planner what they know about how to solve the problem. Hierarchy also lends itself to efficient plan construction because the planner can solve a problem at an abstract level before delving into details. Section 11.3 presents agent architectures that can handle uncertain environments and interleave deliberation with execution, and gives some examples of real-world systems. Section 11.4 shows how to plan when the environment contains other agents.
TIME, SCHEDULES, AND RESOURCES
The classical planning representation talks about what to do, and in what order, but the representation cannot talk about time: how long an action takes and when it occurs. For example, the planners of Chapter 10 could produce a schedule for an airline that says which planes are assigned to which flights, but we really need to know departure and arrival times as well. This is the subject matter of scheduling. The real world also imposes many resource constraints; for example, an airline has a limited number of staff—and staff who are on one flight cannot be on another at the same time. This section covers methods for representing and solving planning problems that include temporal and resource constraints.
The approach we take in this section is “plan first, schedule later”: that is, we divide the overall problem into a planning phase in which actions are selected, with some ordering constraints, to meet the goals of the problem, and a later scheduling phase, in which temporal information is added to the plan to ensure that it meets resource and deadline constraints.
Jobs({AddEngine1 ≺AddWheels~1~ ≺ Inspect~1~},
{AddEngine2 ≺AddWheels~2~ ≺ Inspect~2~})
Resources(EngineHoists(1),WheelStations (1), Inspectors (2),LugNuts(500))
Action(AddEngine1 , DURATION:30,
USE:EngineHoists(1 ))
Action(AddEngine2 , DURATION:60,
USE:EngineHoists(1 ))
Action(AddWheels~1~ , DURATION:30, CONSUME:LugNuts(20),
USE:WheelStations(1))
Action(AddWheels~2~ , DURATION:15, CONSUME:LugNuts(20),
USE:WheelStations(1))
Action(Inspect i, DURATION:10,
USE:Inspectors(1))
Figure 11.1 A job-shop scheduling problem for assembling two cars, with resource constraints. The notation A≺B means that action A must precede action B.
This approach is common in real-world manufacturing and logistical settings, where the planning phase is often performed by human experts. The automated methods of Chapter 10 can also be used for the planning phase, provided that they produce plans with just the minimal ordering constraints required for correctness. G RAPHPLAN (Section 10.3), SATP~LAN~ (Section 10.4.1), and partial-order planners (Section 10.4.4) can do this; search-based methods (Section 10.2) produce totally ordered plans, but these can easily be converted to plans with minimal ordering constraints.
Representing temporal and resource constraints
A typical job-shop scheduling problem, as first introduced in Section 6.1.2, consists of a set of jobs, each of which consists a collection of actions with ordering constraints among them. Each action has a duration and a set of resource constraints required by the action.
Each constraint specifies a type of resource (e.g., bolts, wrenches, or pilots), the number of that resource required, and whether that resource is consumable (e.g., the bolts are no longer available for use) or reusable (e.g., a pilot is occupied during a flight but is available again when the flight is over). Resources can also be produced by actions with negative consumption, including manufacturing, growing, and resupply actions. A solution to a job-shop scheduling problem must specify the start times for each action and must satisfy all the temporal ordering constraints and resource constraints. As with search and planning problems, solutions can be evaluated according to a cost function; this can be quite complicated, with nonlinear resource costs, time-dependent delay costs, and so on. For simplicity, we assume that the cost function is just the total duration of the plan, which is called the makespan.MAKESPAN
Figure 11.1 shows a simple example: a problem involving the assembly of two cars. The problem consists of two jobs, each of the form [AddEngine ,AddWheels , Inspect ]. Then the
Resources statement declares that there are four types of resources, and gives the number of each type available at the start: 1 engine hoist, 1 wheel station, 2 inspectors, and 500 lug nuts. The action schemas give the duration and resource needs of each action. The lug nuts are consumed as wheels are added to the car, whereas the other resources are “borrowed” at the start of an action and released at the action’s end.
The representation of resources as numerical quantities, such as Inspectors(2), rather than as named entities, such as Inspector (I~1~) and Inspector (I~2~), is an example of a very general technique called aggregation. The central idea of aggregation is to group individual objects into quantities when the objects are all indistinguishable with respect to the purpose at hand. In our assembly problem, it does not matter which inspector inspects the car, so there is no need to make the distinction. (The same idea works in the missionaries-and-cannibals problem in Exercise 3.9.) Aggregation is essential for reducing complexity. Consider what happens when a proposed schedule has 10 concurrent Inspect actions but only 9 inspectors are available. With inspectors represented as quantities, a failure is detected immediately and the algorithm backtracks to try another schedule. With inspectors represented as individuals, the algorithm backtracks to try all 10! ways of assigning inspectors to actions.
Solving scheduling problems
We begin by considering just the temporal scheduling problem, ignoring resource constraints. To minimize makespan (plan duration), we must find the earliest start times for all the actions consistent with the ordering constraints supplied with the problem. It is helpful to view these ordering constraints as a directed graph relating the actions, as shown in Figure 11.2. We can apply the critical path method (CPM) to this graph to determine the possible start and end times of each action. A path through a graph representing a partial-order plan is a linearly ordered sequence of actions beginning with Start and ending with Finish . (For example, there are two paths in the partial-order plan in Figure 11.2.)
The critical path is that path whose total duration is longest; the path is “critical” because it determines the duration of the entire plan—shortening other paths doesn’t shorten the plan as a whole, but delaying the start of any action on the critical path slows down the whole plan. Actions that are off the critical path have a window of time in which they can be executed. The window is specified in terms of an earliest possible start time, ES , and a latest possible start time, LS . The quantity LS – ES is known as the slack of an action. We can see in Figure 11.2 that the whole plan will take 85 minutes, that each action in the top job has 15 minutes of slack, and that each action on the critical path has no slack (by definition). Together the ES and LS times for all the actions constitute a schedule for the problem.
The following formulas serve as a definition for ES and LS and also as the outline of a dynamic-programming algorithm to compute them. A and B are actions, and A≺B means that A comes before B:
ES (Start) = 0
ES (B) = max~A≺B~ ES(A) + Duration(A)
LS (Finish) = ES (Finish)
LS (A) = min~B A~ LS (B)−Duration(A) .
The idea is that we start by assigning ES (Start) to be 0. Then, as soon as we get an action B such that all the actions that come immediately before B have ES values assigned, we set ES(B) to be the maximum of the earliest finish times of those immediately preceding actions, where the earliest finish time of an action is defined as the earliest start time plus the duration. This process repeats until every action has been assigned an ES value. The LS values are computed in a similar manner, working backward from the Finish action.
The complexity of the critical path algorithm is just O(Nb), where N is the number of actions and b is the maximum branching factor into or out of an action. (To see this, note that the LS and ES computations are done once for each action, and each computation iterates over at most b other actions.) Therefore, finding a minimum-duration schedule, given a partial ordering on the actions and no resource constraints, is quite easy.
Mathematically speaking, critical-path problems are easy to solve because they are defined as a conjunction of linear inequalities on the start and end times. When we introduce resource constraints, the resulting constraints on start and end times become more complicated. For example, the AddEngine actions, which begin at the same time in Figure 11.2,

require the same EngineHoist and so cannot overlap. The “cannot overlap” constraint is a disjunction of two linear inequalities, one for each possible ordering. The introduction of disjunctions turns out to make scheduling with resource constraints NP-hard.
Figure 11.3 shows the solution with the fastest completion time, 115 minutes. This is 30 minutes longer than the 85 minutes required for a schedule without resource constraints. Notice that there is no time at which both inspectors are required, so we can immediately move one of our two inspectors to a more productive position.
The complexity of scheduling with resource constraints is often seen in practice as well as in theory. A challenge problem posed in 1963—to find the optimal schedule for a problem involving just 10 machines and 10 jobs of 100 actions each—went unsolved for 23 years (Lawler et al., 1993). Many approaches have been tried, including branch-andbound, simulated annealing, tabu search, constraint satisfaction, and other techniques from Chapters 3 and 4. One simple but popular heuristic is the minimum slack algorithm: on each iteration, schedule for the earliest possible start whichever unscheduled action has all its predecessors scheduled and has the least slack; then update the ES and LS times for each affected action and repeat. The heuristic resembles the minimum-remaining-values (MRV) heuristic in constraint satisfaction. It often works well in practice, but for our assembly problem it yields a 130–minute solution, not the 115–minute solution of Figure 11.3.
Up to this point, we have assumed that the set of actions and ordering constraints is fixed. Under these assumptions, every scheduling problem can be solved by a nonoverlapping sequence that avoids all resource conflicts, provided that each action is feasible by itself. If a scheduling problem is proving very difficult, however, it may not be a good idea to solve it this way—it may be better to reconsider the actions and constraints, in case that leads to a much easier scheduling problem. Thus, it makes sense to integrate planning and scheduling by taking into account durations and overlaps during the construction of a partial-order plan. Several of the planning algorithms in Chapter 10 can be augmented to handle this information. For example, partial-order planners can detect resource constraint violations in much the same way they detect conflicts with causal links. Heuristics can be devised to estimate the total completion time of a plan. This is currently an active area of research.
HIERARCHICAL PLANNING
The problem-solving and planning methods of the preceding chapters all operate with a fixed set of atomic actions. Actions can be strung together into sequences or branching networks; state-of-the-art algorithms can generate solutions containing thousands of actions.
For plans executed by the human brain, atomic actions are muscle activations. In very round numbers, we have about 10^3^ muscles to activate (639, by some counts, but many of them have multiple subunits); we can modulate their activation perhaps 10 times per second; and we are alive and awake for about 109 seconds in all. Thus, a human life contains about 10^13^ actions, give or take one or two orders of magnitude. Even if we restrict ourselves to planning over much shorter time horizons—for example, a two-week vacation in Hawaii—a detailed motor plan would contain around 10^10^ actions. This is a lot more than 1000.
To bridge this gap, AI systems will probably have to do what humans appear to do: plan at higher levels of abstraction. A reasonable plan for the Hawaii vacation might be “Go to San Francisco airport; take Hawaiian Airlines flight 11 to Honolulu; do vacation stuff for two weeks; take Hawaiian Airlines flight 12 back to San Francisco; go home.” Given such a plan, the action “Go to San Francisco airport” can be viewed as a planning task in itself, with a solution such as “Drive to the long-term parking lot; park; take the shuttle to the terminal.” Each of these actions, in turn, can be decomposed further, until we reach the level of actions that can be executed without deliberation to generate the required motor control sequences.
In this example, we see that planning can occur both before and during the execution of the plan; for example, one would probably defer the problem of planning a route from a parking spot in long-term parking to the shuttle bus stop until a particular parking spot has been found during execution. Thus, that particular action will remain at an abstract level prior to the execution phase. We defer discussion of this topic until Section 11.3. Here, we concentrate on the aspect of hierarchical decomposition, an idea that pervades almost all attempts to manage complexity. For example, complex software is created from a hierarchy of subroutines or object classes; armies operate as a hierarchy of units; governments and corporations have hierarchies of departments, subsidiaries, and branch offices. The key benefit of hierarchical structure is that, at each level of the hierarchy, a computational task, military mission, or administrative function is reduced to a small number of activities at the next lower level, so the computational cost of finding the correct way to arrange those activities for the current problem is small. Nonhierarchical methods, on the other hand, reduce a task to a large number of individual actions; for large-scale problems, this is completely impractical.
High-level actions
The basic formalism we adopt to understand hierarchical decomposition comes from the area of hierarchical task networks or HTN planning. As in classical planning (Chapter 10), we assume full observability and determinism and the availability of a set of actions, now called primitive actions, with standard precondition–effect schemas. The key additional concept is the high-level action or HLA—for example, the action “Go to San Francisco airport” in the
Refinement(Go(Home,SFO),
STEPS: [Drive(Home,SFOLongTermParking),
Shuttle(SFOLongTermParking ,SFO)] )
Refinement(Go(Home,SFO),
STEPS: [Taxi(Home,SFO)] )
Refinement(Navigate([a, b], [x, y]),
PRECOND: a = x ∧ b = y
STEPS: [ ] )
Refinement(Navigate([a, b], [x, y]),
PRECOND:Connected([a, b], [a− 1, b])
STEPS: [Left ,Navigate([a− 1, b], [x, y])] )
Refinement(Navigate([a, b], [x, y]),
PRECOND:Connected([a, b], [a + 1, b])
STEPS: [Right ,Navigate([a + 1, b], [x, y])] )
. . .
Figure 11.4 Definitions of possible refinements for two high-level actions: going to San Francisco airport and navigating in the vacuum world. In the latter case, note the recursive nature of the refinements and the use of preconditions.
example given earlier. Each HLA has one or more possible refinements, into a sequence of actions, each of which may be an HLA or a primitive action (which has no refinements by definition). For example, the action “Go to San Francisco airport,” represented formally as Go(Home,SFO), might have two possible refinements, as shown in Figure 11.4. The same figure shows a recursive refinement for navigation in the vacuum world: to get to a destination, take a step, and then go to the destination.
These examples show that high-level actions and their refinements embody knowledge about how to do things. For instance, the refinements for Go(Home,SFO) say that to get to the airport you can drive or take a taxi; buying milk, sitting down, and moving the knight to e4 are not to be considered.
An HLA refinement that contains only primitive actions is called an implementation of the HLA. For example, in the vacuum world, the sequences [Right ,Right ,Down ] and [Down ,Right ,Right ] both implement the HLA Navigate([1, 3], [3, 2]). An implementation of a high-level plan (a sequence of HLAs) is the concatenation of implementations of each HLA in the sequence. Given the precondition–effect definitions of each primitive action, it is straightforward to determine whether any given implementation of a high-level plan achieves the goal. We can say, then, that a high-level plan achieves the goal from a given state if at least one of its implementations achieves the goal from that state. The “at least one” in this definition is crucial—not all implementations need to achieve the goal, because the agent gets
1 HTN planners often allow refinement into partially ordered plans, and they allow the refinements of two different HLAs in a plan to share actions. We omit these important complications in the interest of understanding the basic concepts of hierarchical planning.
to decide which implementation it will execute. Thus, the set of possible implementations in HTN planning—each of which may have a different outcome—is not the same as the set of possible outcomes in nondeterministic planning. There, we required that a plan work for all outcomes because the agent doesn’t get to choose the outcome; nature does.
The simplest case is an HLA that has exactly one implementation. In that case, we can compute the preconditions and effects of the HLA from those of the implementation (see Exercise 11.3) and then treat the HLA exactly as if it were a primitive action itself. It can be shown that the right collection of HLAs can result in the time complexity of blind search dropping from exponential in the solution depth to linear in the solution depth, although devising such a collection of HLAs may be a nontrivial task in itself. When HLAs have multiple possible implementations, there are two options: one is to search among the implementations for one that works, as in Section 11.2.2; the other is to reason directly about the HLAs—despite the multiplicity of implementations—as explained in Section 11.2.3. The latter method enables the derivation of provably correct abstract plans, without the need to consider their implementations.
Searching for primitive solutions
HTN planning is often formulated with a single “top level” action called Act, where the aim is to find an implementation of Act that achieves the goal. This approach is entirely general. For example, classical planning problems can be defined as follows: for each primitive action ai, provide one refinement of Act with steps [ai, Act]. That creates a recursive definition of Act that lets us add actions. But we need some way to stop the recursion; we do that by providing one more refinement for Act, one with an empty list of steps and with a precondition equal to the goal of the problem. This says that if the goal is already achieved, then the right implementation is to do nothing.
The approach leads to a simple algorithm: repeatedly choose an HLA in the current plan and replace it with one of its refinements, until the plan achieves the goal. One possible implementation based on breadth-first tree search is shown in Figure 11.5. Plans are considered in order of depth of nesting of the refinements, rather than number of primitive steps. It is straightforward to design a graph-search version of the algorithm as well as depth-first and iterative deepening versions.
In essence, this form of hierarchical search explores the space of sequences that conform to the knowledge contained in the HLA library about how things are to be done. A great deal of knowledge can be encoded, not just in the action sequences specified in each refinement but also in the preconditions for the refinements. For some domains, HTN planners have been able to generate huge plans with very little search. For example, O-PLAN (Bell and Tate, 1985), which combines HTN planning with scheduling, has been used to develop production plans for Hitachi. A typical problem involves a product line of 350 different products, 35 assembly machines, and over 2000 different operations. The planner generates a 30-day schedule with three 8-hour shifts a day, involving tens of millions of steps. Another important aspect of HTN plans is that they are, by definition, hierarchically structured; usually this makes them easy for humans to understand.
function HIERARCHICAL-SEARCH(problem ,hierarchy ) returns a solution, or failure
frontier← a FIFO queue with [Act] as the only element loop do
if EMPTY?( frontier ) then return failure plan← POP( frontier ) /* chooses the shallowest plan in frontier */ hla← the first HLA in plan , or null if none prefix ,suffix ← the action subsequences before and after hla in plan
outcome←RESULT(problem .INITIAL-STATE, prefix ) if hla is null then /* so plan is primitive and outcome is its result */
if outcome satisfies problem .GOAL then return plan
else for each sequence in REFINEMENTS(hla ,outcome,//hierarchy ) do frontier← INSERT(APPEND(prefix , sequence, suffix ), frontier )
Figure 11.5 A breadth-first implementation of hierarchical forward planning search. The initial plan supplied to the algorithm is [Act]. The REFINEMENTS function returns a set of action sequences, one for each refinement of the HLA whose preconditions are satisfied by the specified state, outcome.
The computational benefits of hierarchical search can be seen by examining an idealized case. Suppose that a planning problem has a solution with d primitive actions. For a nonhierarchical, forward state-space planner with b allowable actions at each state, the cost is O(b^d^), as explained in Chapter 3. For an HTN planner, let us suppose a very regular refinement structure: each nonprimitive action has r possible refinements, each into k actions at the next lower level. We want to know how many different refinement trees there are with this structure. Now, if there are d actions at the primitive level, then the number of levels below the root is logk d, so the number of internal refinement nodes is 1 + k + k^2^ + · · · + k ^logk d−1^ = (d − 1)/(k − 1). Each internal node has r possible refinements, so r^(d−1)/(k−1)^ possible regular decomposition trees could be constructed. Examining this formula, we see that keeping r small and k large can result in huge savings: essentially we are taking the kth root of the nonhierarchical cost, if b and r are comparable. Small r and large k means a library of HLAs with a small number of refinements each yielding a long action sequence (that nonetheless allows us to solve any problem). This is not always possible: long action sequences that are usable across a wide range of problems are extremely precious.
The key to HTN planning, then, is the construction of a plan library containing known methods for implementing complex, high-level actions. One method of constructing the library is to learn the methods from problem-solving experience. After the excruciating experience of constructing a plan from scratch, the agent can save the plan in the library as a method for implementing the high-level action defined by the task. In this way, the agent can become more and more competent over time as new methods are built on top of old methods. One important aspect of this learning process is the ability to generalize the methods that are constructed, eliminating detail that is specific to the problem instance (e.g., the name of the builder or the address of the plot of land) and keeping just the key elements of the plan. Methods for achieving this kind of generalization are described in Chapter 19. It seems to us inconceivable that humans could be as competent as they are without some such mechanism.
Searching for abstract solutions
The hierarchical search algorithm in the preceding section refines HLAs all the way to primitive action sequences to determine if a plan is workable. This contradicts common sense: one should be able to determine that the two-HLA high-level plan
[Drive(Home,SFOLongTermParking),Shuttle(SFOLongTermParking ,SFO)]
gets one to the airport without having to determine a precise route, choice of parking spot, and so on. The solution seems obvious: write precondition–effect descriptions of the HLAs, just as we write down what the primitive actions do. From the descriptions, it ought to be easy to prove that the high-level plan achieves the goal. This is the holy grail, so to speak, of hierarchical planning because if we derive a high-level plan that provably achieves the goal, working in a small search space of high-level actions, then we can commit to that plan and work on the problem of refining each step of the plan. This gives us the exponential reduction we seek. For this to work, it has to be the case that every high-level plan that “claims” to achieve the goal (by virtue of the descriptions of its steps) does in fact achieve the goal in the sense defined earlier: it must have at least one implementation that does achieve the goal. This property has been called the downward refinement property for HLA descriptions.
Writing HLA descriptions that satisfy the downward refinement property is, in principle, easy: as long as the descriptions are true, then any high-level plan that claims to achieve the goal must in fact do so—otherwise, the descriptions are making some false claim about what the HLAs do. We have already seen how to write true descriptions for HLAs that have exactly one implementation (Exercise 11.3); a problem arises when the HLA has multiple implementations. How can we describe the effects of an action that can be implemented in many different ways?
One safe answer (at least for problems where all preconditions and goals are positive) is to include only the positive effects that are achieved by every implementation of the HLA and the negative effects of any implementation. Then the downward refinement property would be satisfied. Unfortunately, this semantics for HLAs is much too conservative. Consider again the HLA Go(Home,SFO), which has two refinements, and suppose, for the sake of argument, a simple world in which one can always drive to the airport and park, but taking a taxi requires Cash as a precondition. In that case, Go(Home,SFO) doesn’t always get you to the airport. In particular, it fails if Cash is false, and so we cannot assert At(Agent ,SFO) as an effect of the HLA. This makes no sense, however; if the agent didn’t have Cash , it would drive itself. Requiring that an effect hold for every implementation is equivalent to assuming that someone else—an adversary—will choose the implementation. It treats the HLA’s multiple outcomes exactly as if the HLA were a nondeterministic action, as in Section 4.3. For our case, the agent itself will choose the implementation.
The programming languages community has coined the term demonic nondeterminism for the case where an adversary makes the choices, contrasting this with angelic nonde-
terminism, where the agent itself makes the choices. We borrow this term to define angelic semantics for HLA descriptions. The basic concept required for understanding angelic semantics is the reachable set of an HLA: given a state s, the reachable set for an HLA h, written as REACH(s, h), is the set of states reachable by any of the HLA’s implementations. The key idea is that the agent can choose which element of the reachable set it ends up in when it executes the HLA; thus, an HLA with multiple refinements is more “powerful” than the same HLA with fewer refinements. We can also define the reachable set of a sequences of HLAs. For example, the reachable set of a sequence [h~1~, h~2~] is the union of all the reachable sets obtained by applying h~2~ in each state in the reachable set of h~1~:
REACH(s, [h~1~, h~2~]) = ⋃ REACH(s′, h~2~) .
s′∈REACH(s, h~1~)
Given these definitions, a high-level plan—a sequence of HLAs—achieves the goal if its reachable set intersects the set of goal states. (Compare this to the much stronger condition for demonic semantics, where every member of the reachable set has to be a goal state.) Conversely, if the reachable set doesn’t intersect the goal, then the plan definitely doesn’t work. Figure 11.6 illustrates these ideas.
The notion of reachable sets yields a straightforward algorithm: search among highlevel plans, looking for one whose reachable set intersects the goal; once that happens, the algorithm can commit to that abstract plan, knowing that it works, and focus on refining the plan further. We will come back to the algorithmic issues later; first, we consider the question of how the effects of an HLA—the reachable set for each possible initial state—are represented. As with the classical action schemas of Chapter 10, we represent the changes made to each fluent. Think of a fluent as a state variable. A primitive action can add or delete a variable or leave it unchanged. (With conditional effects (see Section 11.3.1) there is a fourth possibility: flipping a variable to its opposite.)
An HLA under angelic semantics can do more: it can control the value of a variable, setting it to true or false depending on which implementation is chosen. In fact, an HLA can have nine different effects on a variable: if the variable starts out true, it can always keep it true, always make it false, or have a choice; if the variable starts out false, it can always keep it false, always make it true, or have a choice; and the three choices for each case can be combined arbitrarily, making nine. Notationally, this is a bit challenging. We’ll use the ˜ symbol to mean “possibly, if the agent so chooses.” Thus, an effect +̃A means “possibly add A,” that is, either leave A unchanged or make it true. Similarly, −̃A means “possibly delete A” and ±̃A means “possibly add or delete A.” For example, the HLA Go(Home,SFO), with the two refinements shown in Figure 11.4, possibly deletes Cash (if the agent decides to take a taxi), so it should have the effect −̃Cash . Thus, we see that the descriptions of HLAs are derivable, in principle, from the descriptions of their refinements—in fact, this is required if we want true HLA descriptions, such that the downward refinement property holds. Now, suppose we have the following schemas for the HLAs h~1~ and h~2~:
Action(h~1~, PRECOND:¬A, EFFECT:A ∧ −̃ B) , Action(h~2~, PRECOND:¬B, EFFECT:+̃ A ∧ ±̃ C) .
That is, h~1~ adds A and possible deletes B, while h~2~ possibly adds A and has full control over C . Now, if only B is true in the initial state and the goal is A ∧ C then the sequence [h~1~, h~2~] achieves the goal: we choose an implementation of h~1~ that makes B false, then choose an implementation of h~2~ that leaves A true and makes C true.
The preceding discussion assumes that the effects of an HLA—the reachable set for any given initial state—can be described exactly by describing the effect on each variable. It would be nice if this were always true, but in many cases we can only approximate the effects because an HLA may have infinitely many implementations and may produce arbitrarily wiggly reachable sets—rather like the wiggly-belief-state problem illustrated in Figure 7.21 on page 271. For example, we said that Go(Home,SFO) possibly deletes Cash; it also possibly adds At(Car ,SFOLongTermParking); but it cannot do both—in fact, it must do exactly one. As with belief states, we may need to write approximate descriptions. We will use two kinds of approximation: an optimistic description REACH+(s,h) of an HLA h may overstate the reachable set, while a pessimistic description REACH−(s,h) may understate the reachable set. Thus, we have
REACH−(s, h) ⊆ REACH(s, h) ⊆ REACH + (s, h) .
For example, an optimistic description of Go(Home,SFO) says that it possible deletes Cash and possibly adds At(Car ,SFOLongTermParking). Another good example arises in the 8-puzzle, half of whose states are unreachable from any given state (see Exercise 3.4 on page 113): the optimistic description of Act might well include the whole state space, since the exact reachable set is quite wiggly.
With approximate descriptions, the test for whether a plan achieves the goal needs to be modified slightly. If the optimistic reachable set for the plan doesn’t intersect the goal,
then the plan doesn’t work; if the pessimistic reachable set intersects the goal, then the plan does work (Figure 11.7(a)). With exact descriptions, a plan either works or it doesn’t, but with approximate descriptions, there is a middle ground: if the optimistic set intersects the goal but the pessimistic set doesn’t, then we cannot tell if the plan works (Figure 11.7(b)). When this circumstance arises, the uncertainty can be resolved by refining the plan. This is a very common situation in human reasoning. For example, in planning the aforementioned two-week Hawaii vacation, one might propose to spend two days on each of seven islands. Prudence would indicate that this ambitious plan needs to be refined by adding details of inter-island transportation.
An algorithm for hierarchical planning with approximate angelic descriptions is shown in Figure 11.8. For simplicity, we have kept to the same overall scheme used previously in Figure 11.5, that is, a breadth-first search in the space of refinements. As just explained, the algorithm can detect plans that will and won’t work by checking the intersections of the optimistic and pessimistic reachable sets with the goal. (The details of how to compute the reachable sets of a plan, given approximate descriptions of each step, are covered in Exercise 11.5.) When a workable abstract plan is found, the algorithm decomposes the original problem into subproblems, one for each step of the plan. The initial state and goal for each subproblem are obtained by regressing a guaranteed-reachable goal state through the action schemas for each step of the plan. (See Section 10.2.2 for a discussion of how regression works.) Figure 11.6(b) illustrates the basic idea: the right-hand circled state is the guaranteed-reachable goal state, and the left-hand circled state is the intermediate goal obtained by regressing the
function ANGELIC-SEARCH(problem ,hierarchy , initialPlan ) returns solution or fail
frontier← a FIFO queue with initialPlan as the only element loop do
if EMPTY?( frontier ) then return fail
plan← POP( frontier ) /* chooses the shallowest node in frontier */
if REACH+(problem .INITIAL-STATE, plan) intersects problem .GOAL then if plan is primitive then return plan /* REACH+ is exact for primitive plans */
guaranteed←REACH−(problem .INITIAL-STATE,plan) ∩ problem .GOAL
if guaranteed ≠{ } and MAKING-PROGRESS(plan , initialPlan) then finalState← any element of guaranteed
return DECOMPOSE(hierarchy ,problem .INITIAL-STATE,plan ,finalState)
hla← some HLA in plan prefix ,suffix← the action subsequences before and after hla in plan
for each sequence in REFINEMENTS(hla ,outcome ,hierarchy ) do frontier← INSERT(APPEND(prefix , sequence, suffix ), frontier )
function DECOMPOSE(hierarchy , S~0~ ,plan , sf ) returns a solution
solution← an empty plan while plan is not empty do
action←REMOVE-LAST(plan)
s~i~ ← a state in REACH−(S~0~ , plan) such that sf ∈REACH− (s~i~ ,action)
problem← a problem with INITIAL-STATE = s~i~ and GOAL = s~f~ solution←APPEND(ANGELIC-SEARCH(problem ,hierarchy ,action ), solution) s~f~ ← s~i~ return solution
Figure 11.8 A hierarchical planning algorithm that uses angelic semantics to identify and commit to high-level plans that work while avoiding high-level plans that don’t. The predicate MAKING-PROGRESS checks to make sure that we aren’t stuck in an infinite regression of refinements. At top level, call ANGELIC-SEARCH with [Act ] as the initialPlan. goal through the final action.
The ability to commit to or reject high-level plans can give ANGELIC-SEARCH a significant computational advantage over HIERARCHICAL-SEARCH, which in turn may have a large advantage over plain old BREADTH-FIRST-SEARCH. Consider, for example, cleaning up a large vacuum world consisting of rectangular rooms connected by narrow corridors. It makes sense to have an HLA for Navigate (as shown in Figure 11.4) and one for CleanWholeRoom. (Cleaning the room could be implemented with the repeated application of another HLA to clean each row.) Since there are five actions in this domain, the cost for BREADTH-FIRST-SEARCH grows as 5^d^, where d is the length of the shortest solution (roughly twice the total number of squares); the algorithm cannot manage even two 2 × 2 rooms. HIERARCHICAL-SEARCH is more efficient, but still suffers from exponential growth because it tries all ways of cleaning that are consistent with the hierarchy. scales approximately linearly in the number of squares—it commits to a good high-level sequence and prunes away the other options. Notice that cleaning a set of rooms by cleaning each room in turn is hardly rocket science: it is easy for humans precisely because of the hierarchical structure of the task. When we consider how difficult humans find it to solve small puzzles such as the 8-puzzle, it seems likely that the human capacity for solving complex problems derives to a great extent from their skill in abstracting and decomposing the problem to eliminate combinatorics.
The angelic approach can be extended to find least-cost solutions by generalizing the notion of reachable set. Instead of a state being reachable or not, it has a cost for the most efficient way to get there. (The cost is ∞ for unreachable states.) The optimistic and pessimistic descriptions bound these costs. In this way, angelic search can find provably optimal abstract plans without considering their implementations. The same approach can be used to obtain effective hierarchical lookahead algorithms for online search, in the style of (page 152). In some ways, such algorithms mirror aspects of human deliberation in tasks such as planning a vacation to Hawaii—consideration of alternatives is done initially at an abstract level over long time scales; some parts of the plan are left quite abstract until execution time, such as how to spend two lazy days on Molokai, while others parts are planned in detail, such as the flights to be taken and lodging to be reserved—without these refinements, there is no guarantee that the plan would be feasible.
PLANNING AND ACTING IN NONDETERMINISTIC DOMAINS
In this section we extend planning to handle partially observable, nondeterministic, and unknown environments. Chapter 4 extended search in similar ways, and the methods here are also similar: sensorless planning (also known as conformant planning) for environments with no observations; contingency planning for partially observable and nondeterministic environments; and online planning and replanning for unknown environments.
While the basic concepts are the same as in Chapter 4, there are also significant differences. These arise because planners deal with factored representations rather than atomic representations. This affects the way we represent the agent’s capability for action and observation and the way we represent belief states—the sets of possible physical states the agent might be in—for unobservable and partially observable environments. We can also take advantage of many of the domain-independent methods given in Chapter 10 for calculating search heuristics.
Consider this problem: given a chair and a table, the goal is to have them match—have the same color. In the initial state we have two cans of paint, but the colors of the paint and the furniture are unknown. Only the table is initially in the agent’s field of view:
Init(Object(Table) ∧ Object(Chair) ∧ Can(C~1~) ∧ Can(C~2~) ∧ InView(Table))
Goal (Color (Chair , c) ∧ Color(Table, c))
There are two actions: removing the lid from a paint can and painting an object using the paint from an open can. The action schemas are straightforward, with one exception: we now allow preconditions and effects to contain variables that are not part of the action’s variable list. That is, Paint(x, can) does not mention the variable c, representing the color of the paint in the can. In the fully observable case, this is not allowed—we would have to name the action Paint(x, can , c). But in the partially observable case, we might or might not know what color is in the can. (The variable c is universally quantified, just like all the other variables in an action schema.)
Action(RemoveLid(can),
PRECOND:Can(can)
EFFECT:Open(can))
Action(Paint(x , can),
PRECOND:Object(x) ∧ Can(can) ∧ Color(can , c) ∧ Open(can)
EFFECT:Color(x , c))
To solve a partially observable problem, the agent will have to reason about the percepts it will obtain when it is executing the plan. The percept will be supplied by the agent’s sensors when it is actually acting, but when it is planning it will need a model of its sensors. In Chapter 4, this model was given by a function, PERCEPT(s). For planning, we augment PDDL with a new type of schema, the percept schema:
Percept(Color(x, c)),
PRECOND:Object(x) ∧ InView(x)
Percept(Color(can, c)),
PRECOND:Can(can) ∧ InView(can) ∧ Open(can)
The first schema says that whenever an object is in view, the agent will perceive the color of the object (that is, for the object x, the agent will learn the truth value of Color(x, c) for all c). The second schema says that if an open can is in view, then the agent perceives the color of the paint in the can. Because there are no exogenous events in this world, the color of an object will remain the same, even if it is not being perceived, until the agent performs an action to change the object’s color. Of course, the agent will need an action that causes objects (one at a time) to come into view:
Action(LookAt(x),
PRECOND:InView(y) ∧ (x ≠ y)
EFFECT:InView(x) ∧ ¬InView(y))
For a fully observable environment, we would have a Percept axiom with no preconditions for each fluent. A sensorless agent, on the other hand, has no Percept axioms at all. Note that even a sensorless agent can solve the painting problem. One solution is to open any can of paint and apply it to both chair and table, thus coercing them to be the same color (even though the agent doesn’t know what the color is).
A contingent planning agent with sensors can generate a better plan. First, look at the table and chair to obtain their colors; if they are already the same then the plan is done. If not, look at the paint cans; if the paint in a can is the same color as one piece of furniture, then apply that paint to the other piece. Otherwise, paint both pieces with any color.
Finally, an online planning agent might generate a contingent plan with fewer branches at first—perhaps ignoring the possibility that no cans match any of the furniture—and deal with problems when they arise by replanning. It could also deal with incorrectness of its action schemas. Whereas a contingent planner simply assumes that the effects of an action always succeed—that painting the chair does the job—a replanning agent would check the result and make an additional plan to fix any unexpected failure, such as an unpainted area or the original color showing through.
In the real world, agents use a combination of approaches. Car manufacturers sell spare tires and air bags, which are physical embodiments of contingent plan branches designed to handle punctures or crashes. On the other hand, most car drivers never consider these possibilities; when a problem arises they respond as replanning agents. In general, agents plan only for contingencies that have important consequences and a nonnegligible chance of happening. Thus, a car driver contemplating a trip across the Sahara desert should make explicit contingency plans for breakdowns, whereas a trip to the supermarket requires less advance planning. We next look at each of the three approaches in more detail.
Sensorless planning
Section 4.4.1 (page 138) introduced the basic idea of searching in belief-state space to find a solution for sensorless problems. Conversion of a sensorless planning problem to a beliefstate planning problem works much the same way as it did in Section 4.4.1; the main differences are that the underlying physical transition model is represented by a collection of action schemas and the belief state can be represented by a logical formula instead of an explicitly enumerated set of states. For simplicity, we assume that the underlying planning problem is deterministic.
The initial belief state for the sensorless painting problem can ignore InView fluents because the agent has no sensors. Furthermore, we take as given the unchanging facts Object(Table) ∧ Object(Chair) ∧ Can(C~1~) ∧ Can(C~2~) because these hold in every belief state. The agent doesn’t know the colors of the cans or the objects, or whether the cans are open or closed, but it does know that objects and cans have colors: ∀x ∃ c Color (x, c). After Skolemizing, (see Section 9.5), we obtain the initial belief state:
b~0~ = Color(x,C(x)).
In classical planning, where the closed-world assumption is made, we would assume that any fluent not mentioned in a state is false, but in sensorless (and partially observable) planning we have to switch to an open-world assumption in which states contain both positive and negative fluents, and if a fluent does not appear, its value is unknown. Thus, the belief state corresponds exactly to the set of possible worlds that satisfy the formula. Given this initial belief state, the following action sequence is a solution:
[RemoveLid(Can~1~),Paint(Chair ,Can~1~),Paint(Table,Can~1~)] .
We now show how to progress the belief state through the action sequence to show that the final belief state satisfies the goal.
First, note that in a given belief state b, the agent can consider any action whose preconditions are satisfied by b. (The other actions cannot be used because the transition model doesn’t define the effects of actions whose preconditions might be unsatisfied.) According to Equation (4.4) (page 139), the general formula for updating the belief state b given an applicable action a in a deterministic world is as follows:
b′= RESULT(b, a) = {s′ : s′= RESULTP (s, a) and s ∈ b}
where RESULTP defines the physical transition model. For the time being, we assume that the initial belief state is always a conjunction of literals, that is, a 1-CNF formula. To construct the new belief state b′, we must consider what happens to each literal l in each physical state s in b when action a is applied. For literals whose truth value is already known in b, the truth value in b′ is computed from the current value and the add list and delete list of the action. (For example, if l is in the delete list of the action, then ¬l is added to b′.) What about a literal whose truth value is unknown in b? There are three cases:
-
If the action adds l, then l will be true in b′ regardless of its initial value.
-
If the action deletes l, then l will be false in b′ regardless of its initial value.
-
If the action does not affect l, then l will retain its initial value (which is unknown) and will not appear in b′.
Hence, we see that the calculation of b′ is almost identical to the observable case, which was
specified by Equation (10.1) on page 368:
b′= RESULT(b, a) = (b− DEL(a)) ∪ ADD(a) .
We cannot quite use the set semantics because (1) we must make sure that b′ does not contain both l and ¬l, and (2) atoms may contain unbound variables. But it is still the case that RESULT(b, a) is computed by starting with b, setting any atom that appears in DEL(a) to false, and setting any atom that appears in ADD(a) to true. For example, if we apply RemoveLid(Can~1~) to the initial belief state b~0~, we get
b~1~ = Color(x,C(x)) ∧Open(Can~1~) .
When we apply the action Paint(Chair ,Can~1~), the precondition Color (Can~1~, c) is satisfied by the known literal Color(x,C(x)) with binding {x/Can~1~, c/C(Can~1~)} and the new belief state is
b~2~ = Color(x,C(x)) ∧Open(Can~1~) ∧ Color(Chair , C(Can~1~)) .
Finally, we apply the action Paint(Table ,Can~1~) to obtain
b~3~ = Color(x,C(x)) ∧Open(Can~1~) ∧ Color(Chair , C(Can~1~))
∧ Color(Table , C(Can~1~)) .
The final belief state satisfies the goal, Color(Table , c)∧Color (Chair , c), with the variable c bound to C(Can~1~).
The preceding analysis of the update rule has shown a very important fact: the family of belief states defined as conjunctions of literals is closed under updates defined by PDDL action schemas. That is, if the belief state starts as a conjunction of literals, then any update will yield a conjunction of literals. That means that in a world with n fluents, any belief state can be represented by a conjunction of size O(n). This is a very comforting result, considering that there are 2^n^ states in the world. It says we can compactly represent all the subsets of those 2^n^ states that we will ever need. Moreover, the process of checking for belief states that are subsets or supersets of previously visited belief states is also easy, at least in the propositional case.
The fly in the ointment of this pleasant picture is that it only works for action schemas that have the same effects for all states in which their preconditions are satisfied. It is this property that enables the preservation of the 1-CNF belief-state representation. As soon as the effect can depend on the state, dependencies are introduced between fluents and the 1-CNF property is lost. Consider, for example, the simple vacuum world defined in Section 3.2.1. Let the fluents be AtL and AtR for the location of the robot and CleanL and CleanR for the state of the squares. According to the definition of the problem, the Suck action has no precondition—it can always be done. The difficulty is that its effect depends on the robot’s location: when the robot is AtL, the result is CleanL, but when it is AtR, the result is CleanR. For such actions, our action schemas will need something new: a conditional effect. These have the syntax “when condition : effect ,” where condition is a logical formula to be compared against the current state, and effect is a formula describing the resulting state. For the vacuum world, we have
Action(Suck ,
EFFECT:when AtL: CleanL ∧ when AtR: CleanR) .
When applied to the initial belief state True , the resulting belief state is (AtL ∧ CleanL) ∨ (AtR ∧ CleanR), which is no longer in 1-CNF. (This transition can be seen in Figure 4.14 on page 141.) In general, conditional effects can induce arbitrary dependencies among the fluents in a belief state, leading to belief states of exponential size in the worst case.
It is important to understand the difference between preconditions and conditional effects. All conditional effects whose conditions are satisfied have their effects applied to generate the resulting state; if none are satisfied, then the resulting state is unchanged. On the other hand, if a precondition is unsatisfied, then the action is inapplicable and the resulting state is undefined. From the point of view of sensorless planning, it is better to have conditional effects than an inapplicable action. For example, we could split Suck into two actions with unconditional effects as follows:
Action(SuckL,
PRECOND:AtL; EFFECT:CleanL)
Action(SuckR,
PRECOND:AtR; EFFECT:CleanR) .
Now we have only unconditional schemas, so the belief states all remain in 1-CNF; unfortunately, we cannot determine the applicability of SuckL and SuckR in the initial belief state.
It seems inevitable, then, that nontrivial problems will involve wiggly belief states, just like those encountered when we considered the problem of state estimation for the wumpus world (see Figure 7.21 on page 271). The solution suggested then was to use a conservative approximation to the exact belief state; for example, the belief state can remain in 1-CNF if it contains all literals whose truth values can be determined and treats all other literals as unknown. While this approach is sound, in that it never generates an incorrect plan, it is incomplete because it may be unable to find solutions to problems that necessarily involve interactions among literals. To give a trivial example, if the goal is for the robot to be on a clean square, then [Suck ] is a solution but a sensorless agent that insists on 1-CNF belief states will not find it.
Perhaps a better solution is to look for action sequences that keep the belief state as simple as possible. For example, in the sensorless vacuum world, the action sequence [Right ,Suck ,Left ,Suck ] generates the following sequence of belief states:
b~0~ = True
b~1~ = AtR
b~2~ = AtR ∧ CleanR
b~3~ = AtL ∧ CleanR
b4 = AtL ∧ CleanR ∧ CleanL
That is, the agent can solve the problem while retaining a 1-CNF belief state, even though some sequences (e.g., those beginning with Suck) go outside 1-CNF. The general lesson is not lost on humans: we are always performing little actions (checking the time, patting our pockets to make sure we have the car keys, reading street signs as we navigate through a city) to eliminate uncertainty and keep our belief state manageable.
There is another, quite different approach to the problem of unmanageably wiggly belief states: don’t bother computing them at all. Suppose the initial belief state is b~0~ and we would like to know the belief state resulting from the action sequence [A~1~, . . . , am]. Instead of computing it explicitly, just represent it as “b~0~ then [A~1~, . . . , am].” This is a lazy but unambiguous representation of the belief state, and it’s quite concise—O(n + m) where n is the size of the initial belief state (assumed to be in 1-CNF) and m is the maximum length of an action sequence. As a belief-state representation, it suffers from one drawback, however: determining whether the goal is satisfied, or an action is applicable, may require a lot of computation.
The computation can be implemented as an entailment test: if Am represents the collection of successor-state axioms required to define occurrences of the actions A~1~, . . . , am—as explained for SATP~LAN~ in Section 10.4.1—and Gm asserts that the goal is true after m steps, then the plan achieves the goal if b~0~ ∧Am |= Gm, that is, if b~0~ ∧Am ∧ ¬Gm is unsatisfiable. Given a modern SAT solver, it may be possible to do this much more quickly than computing the full belief state. For example, if none of the actions in the sequence has a particular goal fluent in its add list, the solver will detect this immediately. It also helps if partial results about the belief state—for example, fluents known to be true or false—are cached to simplify subsequent computations.
The final piece of the sensorless planning puzzle is a heuristic function to guide the search. The meaning of the heuristic function is the same as for classical planning: an estimate (perhaps admissible) of the cost of achieving the goal from the given belief state. With belief states, we have one additional fact: solving any subset of a belief state is necessarily easier than solving the belief state:
if b~1~ ⊆ b~2~ then h ∗(b~1~) ≤ h ∗(b~2~) .
Hence, any admissible heuristic computed for a subset is admissible for the belief state itself. The most obvious candidates are the singleton subsets, that is, individual physical states. We can take any random collection of states s~1~, . . . , s~N~ that are in the belief state b, apply any admissible heuristic h from Chapter 10, and return
H(b) = max{h(s~1~), . . . , h(s~N~ )}
as the heuristic estimate for solving b. We could also use a planning graph directly on b itself: if it is a conjunction of literals (1-CNF), simply set those literals to be the initial state layer of the graph. If b is not in 1-CNF, it may be possible to find sets of literals that together entail b. For example, if b is in disjunctive normal form (DNF), each term of the DNF formula is a conjunction of literals that entails b and can form the initial layer of a planning graph. As before, we can take the maximum of the heuristics obtained from each set of literals. We can also use inadmissible heuristics such as the ignore-delete-lists heuristic (page 377), which seems to work quite well in practice.
Contingent planning
We saw in Chapter 4 that contingent planning—the generation of plans with conditional branching based on percepts—is appropriate for environments with partial observability, nondeterminism, or both. For the partially observable painting problem with the percept axioms given earlier, one possible contingent solution is as follows:
[LookAt(Table),LookAt(Chair),
if Color(Table , c) ∧ Color(Chair , c) then NoOp
else [RemoveLid(Can~1~),LookAt(Can~1~),RemoveLid (Can~2~),LookAt(Can~2~),
if Color (Table, c) ∧ Color (can , c) then Paint(Chair , can)
else if Color(Chair , c) ∧ Color(can , c) then Paint(Table , can)
else [Paint(Chair ,Can~1~),Paint(Table ,Can~1~)]]]
Variables in this plan should be considered existentially quantified; the second line says that if there exists some color c that is the color of the table and the chair, then the agent need not do anything to achieve the goal. When executing this plan, a contingent-planning agent can maintain its belief state as a logical formula and evaluate each branch condition by determining if the belief state entails the condition formula or its negation. (It is up to the contingent-planning algorithm to make sure that the agent will never end up in a belief state where the condition formula’s truth value is unknown.) Note that with first-order conditions, the formula may be satisfied in more than one way; for example, the condition Color(Table , c) ∧ Color (can , c) might be satisfied by {can/Can~1~} and by {can/Can~2~} if both cans are the same color as the table. In that case, the agent can choose any satisfying substitution to apply to the rest of the plan.
As shown in Section 4.4.2, calculating the new belief state after an action and subsequent percept is done in two stages. The first stage calculates the belief state after the action, just as for the sensorless agent:
b̂ = (b− DEL(a)) ∪ ADD(a)
where, as before, we have assumed a belief state represented as a conjunction of literals. The second stage is a little trickier. Suppose that percept literals P~1~, . . . , P~k~ are received. One might think that we simply need to add these into the belief state; in fact, we can also infer that the preconditions for sensing are satisfied. Now, if a percept p has exactly one percept axiom, Percept(p, PRECOND:c), where c is a conjunction of literals, then those literals can be thrown into the belief state along with p. On the other hand, if p has more than one percept axiom whose preconditions might hold according to the predicted belief state b̂, then we have to add in the disjunction of the preconditions. Obviously, this takes the belief state outside 1-CNF and brings up the same complications as conditional effects, with much the same classes of solutions.
Given a mechanism for computing exact or approximate belief states, we can generate contingent plans with an extension of the AND–OR forward search over belief states used in Section 4.4. Actions with nondeterministic effects—which are defined simply by using a disjunction in the EFFECT of the action schema—can be accommodated with minor changes to the belief-state update calculation and no change to the search algorithm.2 For the heuristic function, many of the methods suggested for sensorless planning are also applicable in the partially observable, nondeterministic case.
Online replanning
Imagine watching a spot-welding robot in a car plant. The robot’s fast, accurate motions are repeated over and over again as each car passes down the line. Although technically impressive, the robot probably does not seem at all intelligent because the motion is a fixed, preprogrammed sequence; the robot obviously doesn’t “know what it’s doing” in any meaningful sense. Now suppose that a poorly attached door falls off the car just as the robot is about to apply a spot-weld. The robot quickly replaces its welding actuator with a gripper, picks up the door, checks it for scratches, reattaches it to the car, sends an email to the floor supervisor, switches back to the welding actuator, and resumes its work. All of a sudden, the robot’s behavior seems purposive rather than rote; we assume it results not from a vast, precomputed contingent plan but from an online replanning process—which means that the robot does need to know what it’s trying to do.
Replanning presupposes some form of execution monitoring to determine the need for a new plan. One such need arises when a contingent planning agent gets tired of planning for every little contingency, such as whether the sky might fall on its head.3 Some branches of a partially constructed contingent plan can simply say Replan ; if such a branch is reached during execution, the agent reverts to planning mode. As we mentioned earlier, the decision as to how much of the problem to solve in advance and how much to leave to replanning is one that involves tradeoffs among possible events with different costs and probabilities of occurring. Nobody wants to have their car break down in the middle of the Sahara desert and only then think about having enough water.
2 If cyclic solutions are required for a nondeterministic problem, AND–OR search must be generalized to a loopy version such as LAO∗ (Hansen and Zilberstein, 2001). 3 In 1954, a Mrs. Hodges of Alabama was hit by meteorite that crashed through her roof. In 1992, a piece of the Mbale meteorite hit a small boy on the head; fortunately, its descent was slowed by banana leaves (Jenniskens et al., 1994). And in 2009, a German boy claimed to have been hit in the hand by a pea-sized meteorite. No serious injuries resulted from any of these incidents, suggesting that the need for preplanning against such contingencies is sometimes overstated.
Replanning may also be needed if the agent’s model of the world is incorrect. The model for an action may have a missing precondition—for example, the agent may not know that removing the lid of a paint can often requires a screwdriver; the model may have a missing effect—for example, painting an object may get paint on the floor as well; or the model may have a missing state variable—for example, the model given earlier has no notion of the amount of paint in a can, of how its actions affect this amount, or of the need for the amount to be nonzero. The model may also lack provision for exogenous events such as someone knocking over the paint can. Exogenous events can also include changes in the goal, such as the addition of the requirement that the table and chair not be painted black. Without the ability to monitor and replan, an agent’s behavior is likely to be extremely fragile if it relies on absolute correctness of its model.
The online agent has a choice of how carefully to monitor the environment. We distinguish three levels:
-
Action monitoring: before executing an action, the agent verifies that all the preconditions still hold.
-
Plan monitoring: before executing an action, the agent verifies that the remaining plan will still succeed.
-
Goal monitoring: before executing an action, the agent checks to see if there is a better set of goals it could be trying to achieve.
In Figure 11.9 we see a schematic of action monitoring. The agent keeps track of both its original plan, wholeplan , and the part of the plan that has not been executed yet, which is denoted by plan . After executing the first few steps of the plan, the agent expects to be in state E. But the agent observes it is actually in state O. It then needs to repair the plan by finding some point P on the original plan that it can get back to. (It may be that P is the goal state, G.) The agent tries to minimize the total cost of the plan: the repair part (from O to P ) plus the continuation (from P to G).
Now let’s return to the example problem of achieving a chair and table of matching color. Suppose the agent comes up with this plan:
[LookAt(Table),LookAt(Chair),
if Color(Table , c) ∧ Color(Chair , c) then NoOp
else [RemoveLid(Can~1~),LookAt(Can~1~),
if Color (Table, c) ∧ Color (Can~1~, c) then Paint(Chair ,Can~1~)
else REPLAN]] .
Now the agent is ready to execute the plan. Suppose the agent observes that the table and can of paint are white and the chair is black. It then executes Paint(Chair ,Can~1~). At this point a classical planner would declare victory; the plan has been executed. But an online execution monitoring agent needs to check the preconditions of the remaining empty plan— that the table and chair are the same color. Suppose the agent perceives that they do not have the same color—in fact, the chair is now a mottled gray because the black paint is showing through. The agent then needs to figure out a position in whole plan to aim for and a repair action sequence to get there. The agent notices that the current state is identical to the precondition before the Paint(Chair ,Can~1~) action, so the agent chooses the empty sequence for repair and makes its plan be the same [Paint ] sequence that it just attempted. With this new plan in place, execution monitoring resumes, and the Paint action is retried. This behavior will loop until the chair is perceived to be completely painted. But notice that the loop is created by a process of plan–execute–replan, rather than by an explicit loop in a plan. Note also that the original plan need not cover every contingency. If the agent reaches the step marked REPLAN, it can then generate a new plan (perhaps involving Can~2~).
Action monitoring is a simple method of execution monitoring, but it can sometimes lead to less than intelligent behavior. For example, suppose there is no black or white paint, and the agent constructs a plan to solve the painting problem by painting both the chair and table red. Suppose that there is only enough red paint for the chair. With action monitoring, the agent would go ahead and paint the chair red, then notice that it is out of paint and cannot paint the table, at which point it would replan a repair—perhaps painting both chair and table green. A plan-monitoring agent can detect failure whenever the current state is such that the remaining plan no longer works. Thus, it would not waste time painting the chair red. Plan monitoring achieves this by checking the preconditions for success of the entire remaining plan—that is, the preconditions of each step in the plan, except those preconditions that are achieved by another step in the remaining plan. Plan monitoring cuts off execution of a doomed plan as soon as possible, rather than continuing until the failure actually occurs.4
Plan monitoring also allows for serendipity—accidental success. If someone comes along and paints the table red at the same time that the agent is painting the chair red, then the final plan preconditions are satisfied (the goal has been achieved), and the agent can go home early.
It is straightforward to modify a planning algorithm so that each action in the plan is annotated with the action’s preconditions, thus enabling action monitoring. It is slightly
4 Plan monitoring means that finally, after 424 pages, we have an agent that is smarter than a dung beetle (see page 39). A plan-monitoring agent would notice that the dung ball was missing from its grasp and would replan to get another ball and plug its hole.
more complex to enable plan monitoring. Partial-order and planning-graph planners have the advantage that they have already built up structures that contain the relations necessary for plan monitoring. Augmenting state-space planners with the necessary annotations can be done by careful bookkeeping as the goal fluents are regressed through the plan.
Now that we have described a method for monitoring and replanning, we need to ask, “Does it work?” This is a surprisingly tricky question. If we mean, “Can we guarantee that the agent will always achieve the goal?” then the answer is no, because the agent could inadvertently arrive at a dead end from which there is no repair. For example, the vacuum agent might have a faulty model of itself and not know that its batteries can run out. Once they do, it cannot repair any plans. If we rule out dead ends—assume that there exists a plan to reach the goal from any state in the environment—and assume that the environment is really nondeterministic, in the sense that such a plan always has some chance of success on any given execution attempt, then the agent will eventually reach the goal.
Trouble occurs when an action is actually not nondeterministic, but rather depends on some precondition that the agent does not know about. For example, sometimes a paint can may be empty, so painting from that can has no effect. No amount of retrying is going to change this.5 One solution is to choose randomly from among the set of possible repair plans, rather than to try the same one each time. In this case, the repair plan of opening another can might work. A better approach is to learn a better model. Every prediction failure is an opportunity for learning; an agent should be able to modify its model of the world to accord with its percepts. From then on, the replanner will be able to come up with a repair that gets at the root problem, rather than relying on luck to choose a good repair. This kind of learning is described in Chapters 18 and 19.
MULTIAGENT PLANNING
So far, we have assumed that only one agent is doing the sensing, planning, and acting. When there are multiple agents in the environment, each agent faces a multiagent planning problem in which it tries to achieve its own goals with the help or hindrance of others.
Between the purely single-agent and truly multiagent cases is a wide spectrum of problems that exhibit various degrees of decomposition of the monolithic agent. An agent with multiple effectors that can operate concurrently—for example, a human who can type and speak at the same time—needs to do multieffector planning to manage each effector while handling positive and negative interactions among the effectors. When the effectors are physically decoupled into detached units—as in a fleet of delivery robots in a factory— multieffector planning becomes multibody planning. A multibody problem is still a “standard” single-agent problem as long as the relevant sensor information collected by each body can be pooled—either centrally or within each body—to form a common estimate of the world state that then informs the execution of the overall plan; in this case, the multiple bodies act as a single body. When communication constraints make this impossible, we have
5 Futile repetition of a plan repair is exactly the behavior exhibited by the sphex wasp (page 39).
what is sometimes called a decentralized planning problem; this is perhaps a misnomer, because the planning phase is centralized but the execution phase is at least partially decoupled. In this case, the subplan constructed for each body may need to include explicit communicative actions with other bodies. For example, multiple reconnaissance robots covering a wide area may often be out of radio contact with each other and should share their findings during times when communication is feasible.
When a single entity is doing the planning, there is really only one goal, which all the bodies necessarily share. When the bodies are distinct agents that do their own planning, they may still share identical goals; for example, two human tennis players who form a doubles team share the goal of winning the match. Even with shared goals, however, the multibody and multiagent cases are quite different. In a multibody robotic doubles team, a single plan dictates which body will go where on the court and which body will hit the ball. In a multiagent doubles team, on the other hand, each agent decides what to do; without some method for coordination, both agents may decide to cover the same part of the court and each may leave the ball for the other to hit. The clearest case of a multiagent problem, of course, is when the agents have different goals. In tennis, the goals of two opposing teams are in direct conflict, leading to the zerosum situation of Chapter 5. Spectators could be viewed as agents if their support or disdain is a significant factor and can be influenced by the players’ conduct; otherwise, they can be treated as an aspect of nature—just like the weather—that is assumed to be indifferent to the players’ intentions.6
Finally, some systems are a mixture of centralized and multiagent planning. For example, a delivery company may do centralized, offline planning for the routes of its trucks and planes each day, but leave some aspects open for autonomous decisions by drivers and pilots who can respond individually to traffic and weather situations. Also, the goals of the company and its employees are brought into alignment, to some extent, by the payment of incentives (salaries and bonuses)—a sure sign that this is a true multiagent system.
The issues involved in multiagent planning can be divided roughly into two sets. The first, covered in Section 11.4.1, involves issues of representing and planning for multiple simultaneous actions; these issues occur in all settings from multieffector to multiagent planning. The second, covered in Section 11.4.2, involves issues of cooperation, coordination, and competition arising in true multiagent settings.
Planning with multiple simultaneous actions
For the time being, we will treat the multieffector, multibody, and multiagent settings in the same way, labeling them generically as multiactor settings, using the generic term actor toMULTIACTOR
ACTOR cover effectors, bodies, and agents. The goal of this section is to work out how to define transition models, correct plans, and efficient planning algorithms for the multiactor setting. A correct plan is one that, if executed by the actors, achieves the goal. In the true multiagent setting, of course, the agents may not agree to execute any particular plan, but at least they
6 We apologize to residents of the United Kingdom, where the mere act of contemplating a game of tennis guarantees rain.
Actors(A, B)
Init(At(A,LeftBaseline) ∧ At(B,RightNet) ∧
Approaching(Ball ,RightBaseline)) ∧ Partner(A, B) ∧ Partner(B, A)
Goal (Returned(Ball ) ∧ (At(a,RightNet) ∨ At(a,LeftNet))
Action(Hit(actor ,Ball),
PRECOND:Approaching(Ball , loc) ∧ At(actor , loc)
EFFECT:Returned(Ball))
Action(Go(actor , to),
PRECOND:At(actor , loc) ∧ to ≠ loc,
EFFECT:At(actor , to) ∧ ¬ At(actor , loc))
Figure 11.10 The doubles tennis problem. Two actors A and B are playing together and can be in one of four locations: LeftBaseline , RightBaseline , LeftNet , and RightNet . The ball can be returned only if a player is in the right place. Note that each action must include the actor as an argument.
will know what plans would work if they did agree to execute them.) For simplicity, we assume perfect synchronization: each action takes the same amount of time and actions at each point in the joint plan are simultaneous.
We begin with the transition model; for the deterministic case, this is the function RESULT(s, a). In the single-agent setting, there might be b different choices for the action; b can be quite large, especially for first-order representations with many objects to act on, but action schemas provide a concise representation nonetheless. In the multiactor setting with n actors, the single action a is replaced by a joint action 〈a~1~, . . . , a~n~〉, where ai is the action taken by the ith actor. Immediately, we see two problems: first, we have to describe the transition model for b~n~ different joint actions; second, we have a joint planning problem with a branching factor of b~n~. Having put the actors together into a multiactor system with a huge branching factor,
the principal focus of research on multiactor planning has been to decouple the actors to the extent possible, so that the complexity of the problem grows linearly with n rather than exponentially. If the actors have no interaction with one another—for example, n actors each playing a game of solitaire—then we can simply solve n separate problems. If the actors are loosely coupled, can we attain something close to this exponential improvement? This is, of course, a central question in many areas of AI. We have seen it explicitly in the context of CSPs, where “tree like” constraint graphs yielded efficient solution methods (see page 225), as well as in the context of disjoint pattern databases (page 106) and additive heuristics for planning (page 378).
The standard approach to loosely coupled problems is to pretend the problems are completely decoupled and then fix up the interactions. For the transition model, this means writing action schemas as if the actors acted independently. Let’s see how this works for the doubles tennis problem. Let’s suppose that at one point in the game, the team has the goal of returning the ball that has been hit to them and ensuring that at least one of them is covering the net.
A first pass at a multiactor definition might look like Figure 11.10. With this definition, it is easy to see that the following joint plan plan works:
PLAN 1: A : [Go(A,RightBaseline),Hit(A,Ball )] B : [NoOp(B),NoOp(B)] .
Problems arise, however, when a plan has both agents hitting the ball at the same time. In the real world, this won’t work, but the action schema for Hit says that the ball will be returned successfully. Technically, the difficulty is that preconditions constrain the state in which an action can be executed successfully, but do not constrain other actions that might mess it up. We solve this by augmenting action schemas with one new feature: a concurrent action list stating which actions must or must not be executed concurrently. For example, the Hit action could be described as follows:
Action(Hit(a,Ball ),
CONCURRENT:b ≠ a ⇒ ¬Hit(b,Ball )
PRECOND:Approaching(Ball , loc) ∧ At(a, loc)
EFFECT:Returned(Ball)) .
In other words, the Hit action has its stated effect only if no other Hit action by another agent occurs at the same time. (In the SATP~LAN~ approach, this would be handled by a partial action exclusion axiom.) For some actions, the desired effect is achieved only when another action occurs concurrently. For example, two agents are needed to carry a cooler full of beverages to the tennis court:
Action(Carry(a, cooler , here , there),
CONCURRENT:b ≠ a ∧ Carry(b, cooler , here , there)
PRECOND:At(a, here) ∧ At(cooler , here) ∧ Cooler (cooler )
EFFECT:At(a, there) ∧ At(cooler , there) ∧ ¬At(a, here) ∧ ¬At(cooler , here)).
With these kinds of action schemas, any of the planning algorithms described in Chapter 10 can be adapted with only minor modifications to generate multiactor plans. To the extent that the coupling among subplans is loose—meaning that concurrency constraints come into play only rarely during plan search—one would expect the various heuristics derived for singleagent planning to also be effective in the multiactor context. We could extend this approach with the refinements of the last two chapters—HTNs, partial observability, conditionals, execution monitoring, and replanning—but that is beyond the scope of this book.
Planning with multiple agents: Cooperation and coordination
Now let us consider the true multiagent setting in which each agent makes its own plan. To start with, let us assume that the goals and knowledge base are shared. One might think that this reduces to the multibody case—each agent simply computes the joint solution and executes its own part of that solution. Alas, the “the” in “the joint solution” is misleading. For our doubles team, more than one joint solution exists:
PLAN 2:
A : [Go(A,LeftNet),NoOp(A)] B : [Go(B,RightBaseline),Hit(B,Ball)] .
Section 11.4. Multiagent Planning 429
If both agents can agree on either plan 1 or plan 2, the goal will be achieved. But if A chooses plan 2 and B chooses plan 1, then nobody will return the ball. Conversely, if A chooses 1 and B chooses 2, then they will both try to hit the ball. The agents may realize this, but how can they coordinate to make sure they agree on the plan?
One option is to adopt a convention before engaging in joint activity. A convention is any constraint on the selection of joint plans. For example, the convention “stick to your side of the court” would rule out plan 1, causing the doubles partners to select plan 2. Drivers on a road face the problem of not colliding with each other; this is (partially) solved by adopting the convention “stay on the right side of the road” in most countries; the alternative, “stay on the left side,” works equally well as long as all agents in an environment agree. Similar considerations apply to the development of human language, where the important thing is not which language each individual should speak, but the fact that a community all speaks the same language. When conventions are widespread, they are called social laws.
In the absence of a convention, agents can use communication to achieve common knowledge of a feasible joint plan. For example, a tennis player could shout “Mine!” or “Yours!” to indicate a preferred joint plan. We cover mechanisms for communication in more depth in Chapter 22, where we observe that communication does not necessarily involve a verbal exchange. For example, one player can communicate a preferred joint plan to the other simply by executing the first part of it. If agent A heads for the net, then agent B is obliged to go back to the baseline to hit the ball, because plan 2 is the only joint plan that begins with A’s heading for the net. This approach to coordination, sometimes called plan recognition, works when a single action (or short sequence of actions) is enough to determine a joint plan unambiguously. Note that communication can work as well with competitive agents as with cooperative ones.
Conventions can also arise through evolutionary processes. For example, seed-eating harvester ants are social creatures that evolved from the less social wasps. Colonies of ants execute very elaborate joint plans without any centralized control—the queen’s job is to reproduce, not to do centralized planning—and with very limited computation, communication, and memory capabilities in each ant (Gordon, 2000, 2007). The colony has many roles, including interior workers, patrollers, and foragers. Each ant chooses to perform a role according to the local conditions it observes. For example, foragers travel away from the nest, search for a seed, and when they find one, bring it back immediately. Thus, the rate at which foragers return to the nest is an approximation of the availability of food today. When the rate is high, other ants abandon their current role and take on the role of scavenger. The ants appear to have a convention on the importance of roles—foraging is the most important—and ants will easily switch into the more important roles, but not into the less important. There is some learning mechanism: a colony learns to make more successful and prudent actions over the course of its decades-long life, even though individual ants live only about a year.
One final example of cooperative multiagent behavior appears in the flocking behavior of birds. We can obtain a reasonable simulation of a flock if each bird agent (sometimes called a boid) observes the positions of its nearest neighbors and then chooses the heading and acceleration that maximizes the weighted sum of these three components:

-
Cohesion: a positive score for getting closer to the average position of the neighbors
-
Separation: a negative score for getting too close to any one neighbor
-
Alignment: a positive score for getting closer to the average heading of the neighbors
If all the boids execute this policy, the flock exhibits the emergent behavior of flying as a pseudorigid body with roughly constant density that does not disperse over time, and that occasionally makes sudden swooping motions. You can see a still images in Figure 11.11(a) and compare it to an actual flock in (b). As with ants, there is no need for each agent to possess a joint plan that models the actions of other agents.
The most difficult multiagent problems involve both cooperation with members of one’s own team and competition against members of opposing teams, all without centralized control. We see this in games such as robotic soccer or the NERO game shown in Figure 11.11(c), in which two teams of software agents compete to capture the control towers. As yet, methods for efficient planning in these kinds of environments—for example, taking advantage of loose coupling—are in their infancy.
SUMMARY
This chapter has addressed some of the complications of planning and acting in the real world. The main points:
-
Many actions consume resources, such as money, gas, or raw materials. It is convenient to treat these resources as numeric measures in a pool rather than try to reason about, say, each individual coin and bill in the world. Actions can generate and consume resources, and it is usually cheap and effective to check partial plans for satisfaction of resource constraints before attempting further refinements.
-
Time is one of the most important resources. It can be handled by specialized scheduling algorithms, or scheduling can be integrated with planning.
-
Hierarchical task network (HTN) planning allows the agent to take advice from the domain designer in the form of high-level actions (HLAs) that can be implemented in various ways by lower-level action sequences. The effects of HLAs can be defined with angelic semantics, allowing provably correct high-level plans to be derived without consideration of lower-level implementations. HTN methods can create the very large plans required by many real-world applications.
-
Standard planning algorithms assume complete and correct information and deterministic, fully observable environments. Many domains violate this assumption.
-
Contingent plans allow the agent to sense the world during execution to decide what branch of the plan to follow. In some cases, sensorless or conformant planning can be used to construct a plan that works without the need for perception. Both conformant and contingent plans can be constructed by search in the space of belief states. Efficient representation or computation of belief states is a key problem.
-
An online planning agent uses execution monitoring and splices in repairs as needed to recover from unexpected situations, which can be due to nondeterministic actions, exogenous events, or incorrect models of the environment.
-
Multiagent planning is necessary when there are other agents in the environment with which to cooperate or compete. Joint plans can be constructed, but must be augmented with some form of coordination if two agents are to agree on which joint plan to execute.
-
This chapter extends classic planning to cover nondeterministic environments (where outcomes of actions are uncertain), but it is not the last word on planning. Chapter 17 describes techniques for stochastic environments (in which outcomes of actions have probabilities associated with them): Markov decision processes, partially observable Markov decision processes, and game theory. In Chapter 21 we show that reinforcement learning allows an agent to learn how to behave from past successes and failures.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
Planning with time constraints was first dealt with by DEVISER (Vere, 1983). The representation of time in plans was addressed by Allen (1984) and by Dean et al. (1990) in the FORBIN system. NONLIN+ (Tate and Whiter, 1984) and SIPE (Wilkins, 1988, 1990) could reason about the allocation of limited resources to various plan steps. O-PLAN (Bell and Tate, 1985), an HTN planner, had a uniform, general representation for constraints on time and resources. In addition to the Hitachi application mentioned in the text, O-PLAN has been applied to software procurement planning at Price Waterhouse and back-axle assembly planning at Jaguar Cars.
The two planners SAPA (Do and Kambhampati, 2001) and t~4~ (Haslum and Geffner, 2001) both used forward state-space search with sophisticated heuristics to handle actions with durations and resources. An alternative is to use very expressive action languages, but guide them by human-written domain-specific heuristics, as is done by ASPEN (Fukunaga et al., 1997), HSTS (Jonsson et al., 2000), and IxTeT (Ghallab and Laruelle, 1994).
A number of hybrid planning-and-scheduling systems have been deployed: ISIS (Fox et al., 1982; Fox, 1990) has been used for job shop scheduling at Westinghouse, GARI (Descotte and Latombe, 1985) planned the machining and construction of mechanical parts, FORBIN was used for factory control, and NONLIN+ was used for naval logistics planning. We chose to present planning and scheduling as two separate problems; (Cushing et al., 2007) show that this can lead to incompleteness on certain problems. There is a long history of scheduling in aerospace. T-SCHED (Drabble, 1990) was used to schedule mission-command sequences for the UOSAT-II satellite. OPTIMUM-AIV (Aarup et al., 1994) and PLAN-ERs~1~ (Fuchs et al., 1990), both based on O-PLAN, were used for spacecraft assembly and observation planning, respectively, at the European Space Agency. SPIKE (Johnston and Adorf, 1992) was used for observation planning at NASA for the Hubble Space Telescope, while the Space Shuttle Ground Processing Scheduling System (Deale et al., 1994) does job-shop scheduling of up to 16,000 worker-shifts. Remote Agent (Muscettola et al., 1998) became the first autonomous planner–scheduler to control a spacecraft when it flew onboard the Deep Space One probe in 1999. Space applications have driven the development of algorithms for resource allocations; see Laborie (2003) and Muscettola (2002). The literature on scheduling is presented in a classic survey article (Lawler et al., 1993), a recent book (Pinedo, 2008), and an edited handbook (Blazewicz et al., 2007).
The facility in the STRIPS program for learning macrops—“macro-operators” consisting of a sequence of primitive steps—could be considered the first mechanism for hierarchical planning (Fikes et al., 1972). Hierarchy was also used in the LAWALY system (Siklossy and Dreussi, 1973). The ABSTRIPS system (Sacerdoti, 1974) introduced the idea of an abstraction hierarchy, whereby planning at higher levels was permitted to ignore lower-level preconditions of actions in order to derive the general structure of a working plan. Austin Tate’s Ph.D. thesis (1975b) and work by Earl Sacerdoti (1977) developed the basic ideas of HTN planning in its modern form. Many practical planners, including O-PLAN and SIPE, are HTN planners. Yang (1990) discusses properties of actions that make HTN planning efficient. Erol, Hendler, and Nau (1994, 1996) present a complete hierarchical decomposition planner as well as a range of complexity results for pure HTN planners. Our presentation of HLAs and angelic semantics is due to Marthi et al. (2007, 2008). Kambhampati et al. (1998) have proposed an approach in which decompositions are just another form of plan refinement, similar to the refinements for non-hierarchical partial-order planning.
Beginning with the work on macro-operators in STRIPS, one of the goals of hierarchical planning has been the reuse of previous planning experience in the form of generalized plans. The technique of explanation-based learning, described in depth in Chapter 19, has been applied in several systems as a means of generalizing previously computed plans, including SOAR (Laird et al., 1986) and PRODIGY (Carbonell et al., 1989). An alternative approach is to store previously computed plans in their original form and then reuse them to solve new, similar problems by analogy to the original problem. This is the approach taken by the field called case-based planning (Carbonell, 1983; Alterman, 1988; Hammond, 1989). Kambhampati (1994) argues that case-based planning should be analyzed as a form of refinement planning and provides a formal foundation for case-based partial-order planning.
Early planners lacked conditionals and loops, but some could use coercion to form conformant plans. Sacerdoti’s NOAH solved the “keys and boxes” problem, a planning challenge problem in which the planner knows little about the initial state, using coercion. Mason (1993) argued that sensing often can and should be dispensed with in robotic planning, and described a sensorless plan that can move a tool into a specific position on a table by a sequence of tilting actions, regardless of the initial position.
Goldman and Boddy (1996) introduced the term conformant planning, noting that sensorless plans are often effective even if the agent has sensors. The first moderately efficient conformant planner was Smith and Weld’s (1998) Conformant Graphplan or CGP. Ferraris and Giunchiglia (2000) and Rintanen (1999) independently developed SATP~LAN~-based conformant planners. Bonet and Geffner (2000) describe a conformant planner based on heuristic search in the space of belief states, drawing on ideas first developed in the 1960s for partially observable Markov decision processes, or POMDPs (see Chapter 17).
Currently, there are three main approaches to conformant planning. The first two use heuristic search in belief-state space: HSCP (Bertoli et al., 2001a) uses binary decision diagrams (BDDs) to represent belief states, whereas Hoffmann and Brafman (2006) adopt the lazy approach of computing precondition and goal tests on demand using a SAT solver. The third approach, championed primarily by Jussi Rintanen (2007), formulates the entire sensorless planning problem as a quantified Boolean formula (QBF) and solves it using a general-purpose QBF solver. Current conformant planners are five orders of magnitude faster than CGP. The winner of the 2006 conformant-planning track at the International Planning Competition was T0 (Palacios and Geffner, 2007), which uses heuristic search in belief-state space while keeping the belief-state representation simple by defining derived literals that cover conditional effects. Bryce and Kambhampati (2007) discuss how a planning graph can be generalized to generate good heuristics for conformant and contingent planning.
There has been some confusion in the literature between the terms “conditional” and “contingent” planning. Following Majercik and Littman (2003), we use “conditional” to mean a plan (or action) that has different effects depending on the actual state of the world, and “contingent” to mean a plan in which the agent can choose different actions depending on the results of sensing. The problem of contingent planning received more attention after the publication of Drew McDermott’s (1978a) influential article, Planning and Acting.
The contingent-planning approach described in the chapter is based on Hoffmann and Brafman (2005), and was influenced by the efficient search algorithms for cyclic AND–OR graphs developed by Jimenez and Torras (2000) and Hansen and Zilberstein (2001). Bertoli et al. (2001b) describe MBP (Model-Based Planner), which uses binary decision diagrams to do conformant and contingent planning.
In retrospect, it is now possible to see how the major classical planning algorithms led to extended versions for uncertain domains. Fast-forward heuristic search through state space led to forward search in belief space (Bonet and Geffner, 2000; Hoffmann and Brafman, 2005); SATP~LAN~ led to stochastic SATP~LAN~ (Majercik and Littman, 2003) and to planning with quantified Boolean logic (Rintanen, 2007); partial order planning led to UWL (Etzioni et al., 1992) and CNLP (Peot and Smith, 1992); GRAPHPLAN led to Sensory Graphplan or SGP (Weld et al., 1998).
The first online planner with execution monitoring was PLANEX (Fikes et al., 1972), which worked with the STRIPS planner to control the robot Shakey. The NASL planner (McDermott, 1978a) treated a planning problem simply as a specification for carrying out a complex action, so that execution and planning were completely unified. SIPE (System for Interactive Planning and Execution monitoring) (Wilkins, 1988, 1990) was the first planner to deal systematically with the problem of replanning. It has been used in demonstration projects in several domains, including planning operations on the flight deck of an aircraft carrier, job-shop scheduling for an Australian beer factory, and planning the construction of multistory buildings (Kartam and Levitt, 1990).
In the mid-1980s, pessimism about the slow run times of planning systems led to the proposal of reflex agents called reactive planning systems (Brooks, 1986; Agre and Chapman, 1987). PENGI (Agre and Chapman, 1987) could play a (fully observable) video game by using Boolean circuits combined with a “visual” representation of current goals and the agent’s internal state. “Universal plans” (Schoppers, 1987, 1989) were developed as a lookuptable method for reactive planning, but turned out to be a rediscovery of the idea of policiesthat had long been used in Markov decision processes (see Chapter 17). A universal plan (or a policy) contains a mapping from any state to the action that should be taken in that state. Koenig (2001) surveys online planning techniques, under the name Agent-Centered Search.
Multiagent planning has leaped in popularity in recent years, although it does have a long history. Konolige (1982) formalizes multiagent planning in first-order logic, while Pednault (1986) gives a STRIPS-style description. The notion of joint intention, which is essential if agents are to execute a joint plan, comes from work on communicative acts (Cohen and Levesque, 1990; Cohen et al., 1990). Boutilier and Brafman (2001) show how to adapt partial-order planning to a multiactor setting. Brafman and Domshlak (2008) devise a multiactor planning algorithm whose complexity grows only linearly with the number of actors, provided that the degree of coupling (measured partly by the tree width of the graph of interactions among agents) is bounded. Petrik and Zilberstein (2009) show that an approach based on bilinear programming outperforms the cover-set approach we outlined in the chapter.
We have barely skimmed the surface of work on negotiation in multiagent planning. Durfee and Lesser (1989) discuss how tasks can be shared out among agents by negotiation. Kraus et al. (1991) describe a system for playing Diplomacy, a board game requiring negotiation, coalition formation, and dishonesty. Stone (2000) shows how agents can cooperate as teammates in the competitive, dynamic, partially observable environment of robotic soccer. In a later article, Stone (2003) analyzes two competitive multiagent environments—RoboCup, a robotic soccer competition, and TAC, the auction-based Trading Agents Competition— and finds that the computational intractability of our current theoretically well-founded approaches has led to many multiagent systems being designed by ad hoc methods.
In his highly influential Society of Mind theory, Marvin Minsky (1986, 2007) proposes that human minds are constructed from an ensemble of agents. Livnat and Pippenger (2006) prove that, for the problem of optimal path-finding, and given a limitation on the total amount of computing resources, the best architecture for an agent is an ensemble of subagents, each of which tries to optimize its own objective, and all of which are in conflict with one another.
The boid model on page 429 is due to Reynolds (1987), who won an Academy Award for its application to swarms of penguins in Batman Returns. The NERO game and the methods for learning strategies are described by Bryant and Miikkulainen (2007).
Recent book on multiagent systems include those by Weiss (2000a), Young (2004), Vlassis (2008), and Shoham and Leyton-Brown (2009). There is an annual conference on autonomous agents and multiagent systems (AAMAS).
EXERCISES
11.1 The goals we have considered so far all ask the planner to make the world satisfy the goal at just one time step. Not all goals can be expressed this way: you do not achieve the goal of suspending a chandelier above the ground by throwing it in the air. More seriously, you wouldn’t want your spacecraft life-support system to supply oxygen one day but not the next. A maintenance goal is achieved when the agent’s plan causes a condition to hold continuously from a given state onward. Describe how to extend the formalism of this chapter to support maintenance goals.
11.2 You have a number of trucks with which to deliver a set of packages. Each package starts at some location on a grid map, and has a destination somewhere else. Each truck is directly controlled by moving forward and turning. Construct a hierarchy of high-level actions for this problem. What knowledge about the solution does your hierarchy encode?
11.3 Suppose that a high-level action has exactly one implementation as a sequence of primitive actions. Give an algorithm for computing its preconditions and effects, given the complete refinement hierarchy and schemas for the primitive actions.
11.4 Suppose that the optimistic reachable set of a high-level plan is a superset of the goal set; can anything be concluded about whether the plan achieves the goal? What if the pessimistic reachable set doesn’t intersect the goal set? Explain.
11.5 Write an algorithm that takes an initial state (specified by a set of propositional literals) and a sequence of HLAs (each defined by preconditions and angelic specifications of optimistic and pessimistic reachable sets) and computes optimistic and pessimistic descriptions of the reachable set of the sequence.
11.6 In Figure 11.2 we showed how to describe actions in a scheduling problem by using separate fields for DURATION, USE, and CONSUME. Now suppose we wanted to combine scheduling with nondeterministic planning, which requires nondeterministic and conditional effects. Consider each of the three fields and explain if they should remain separate fields, or if they should become effects of the action. Give an example for each of the three.
11.7 Some of the operations in standard programming languages can be modeled as actions that change the state of the world. For example, the assignment operation changes the contents of a memory location, and the print operation changes the state of the output stream. A program consisting of these operations can also be considered as a plan, whose goal is given by the specification of the program. Therefore, planning algorithms can be used to construct programs that achieve a given specification.
a. Write an action schema for the assignment operator (assigning the value of one variable to another). Remember that the original value will be overwritten!
b. Show how object creation can be used by a planner to produce a plan for exchanging the values of two variables by using a temporary variable.
11.8 Suppose the Flip action always changes the truth value of variable L. Show how to define its effects by using an action schema with conditional effects. Show that, despite the use of conditional effects, a 1-CNF belief state representation remains in 1-CNF after a Flip.
11.9 In the blocks world we were forced to introduce two action schemas, Move and MoveToTable , in order to maintain the Clear predicate properly. Show how conditional effects can be used to represent both of these cases with a single action.
11.10 Conditional effects were illustrated for the Suck action in the vacuum world—which square becomes clean depends on which square the robot is in. Can you think of a new set of propositional variables to define states of the vacuum world, such that Suck has an unconditional description? Write out the descriptions of Suck , Left , and Right , using your propositions, and demonstrate that they suffice to describe all possible states of the world.
11.11 Find a suitably dirty carpet, free of obstacles, and vacuum it. Draw the path taken by the vacuum cleaner as accurately as you can. Explain it, with reference to the forms of planning discussed in this chapter.
11.12 To the medication problem in the previous exercise, add a Test action that has the conditional effect CultureGrowth when Disease is true and in any case has the perceptual effect Known(CultureGrowth). Diagram a conditional plan that solves the problem and minimizes the use of the Medicate action.
KNOWLEDGE REPRESENTATION
In which we show how to use first-order logic to represent the most important aspects of the real world, such as action, space, time, thoughts, and shopping.
The previous chapters described the technology for knowledge-based agents: the syntax, semantics, and proof theory of propositional and first-order logic, and the implementation of agents that use these logics. In this chapter we address the question of what content to put into such an agent’s knowledge base—how to represent facts about the world.
Section 12.1 introduces the idea of a general ontology, which organizes everything in the world into a hierarchy of categories. Section 12.2 covers the basic categories of objects, substances, and measures; Section 12.3 covers events, and Section 12.4 discusses knowledge about beliefs. We then return to consider the technology for reasoning with this content: Section 12.5 discusses reasoning systems designed for efficient inference with categories, and Section 12.6 discusses reasoning with default information. Section 12.7 brings all the knowledge together in the context of an Internet shopping environment.
ONTOLOGICAL ENGINEERING
In “toy” domains, the choice of representation is not that important; many choices will work. Complex domains such as shopping on the Internet or driving a car in traffic require more general and flexible representations. This chapter shows how to create these representations, concentrating on general concepts—such as Events, Time, Physical Objects, and Beliefs— that occur in many different domains. Representing these abstract concepts is sometimes called ontological engineering.
The prospect of representing everything in the world is daunting. Of course, we won’t actually write a complete description of everything—that would be far too much for even a 1000-page textbook—but we will leave placeholders where new knowledge for any domain can fit in. For example, we will define what it means to be a physical object, and the details of different types of objects—robots, televisions, books, or whatever—can be filled in later. This is analogous to the way that designers of an object-oriented programming framework (such as the Java Swing graphical framework) define general concepts like Window, expecting users to
use these to define more specific concepts like SpreadsheetWindow. The general framework of concepts is called an upper ontology because of the convention of drawing graphs with the general concepts at the top and the more specific concepts below them, as in Figure 12.1.
Before considering the ontology further, we should state one important caveat. We have elected to use first-order logic to discuss the content and organization of knowledge, although certain aspects of the real world are hard to capture in FOL. The principal difficulty is that most generalizations have exceptions or hold only to a degree. For example, although “tomatoes are red” is a useful rule, some tomatoes are green, yellow, or orange. Similar exceptions can be found to almost all the rules in this chapter. The ability to handle exceptions and uncertainty is extremely important, but is orthogonal to the task of understanding the general ontology. For this reason, we delay the discussion of exceptions until Section 12.5 of this chapter, and the more general topic of reasoning with uncertainty until Chapter 13.
Of what use is an upper ontology? Consider the ontology for circuits in Section 8.4.2. It makes many simplifying assumptions: time is omitted completely; signals are fixed and do not propagate; the structure of the circuit remains constant. A more general ontology would consider signals at particular times, and would include the wire lengths and propagation delays. This would allow us to simulate the timing properties of the circuit, and indeed such simulations are often carried out by circuit designers. We could also introduce more interesting classes of gates, for example, by describing the technology (TTL, CMOS, and so on) as well as the input–output specification. If we wanted to discuss reliability or diagnosis, we would include the possibility that the structure of the circuit or the properties of the gates might change spontaneously. To account for stray capacitances, we would need to represent where the wires are on the board.
If we look at the wumpus world, similar considerations apply. Although we do represent time, it has a simple structure: Nothing happens except when the agent acts, and all changes are instantaneous. A more general ontology, better suited for the real world, would allow for simultaneous changes extended over time. We also used a Pit predicate to say which squares have pits. We could have allowed for different kinds of pits by having several individuals belonging to the class of pits, each having different properties. Similarly, we might want to allow for other animals besides wumpuses. It might not be possible to pin down the exact species from the available percepts, so we would need to build up a biological taxonomy to help the agent predict the behavior of cave-dwellers from scanty clues.
For any special-purpose ontology, it is possible to make changes like these to move toward greater generality. An obvious question then arises: do all these ontologies converge on a general-purpose ontology? After centuries of philosophical and computational investigation, the answer is “Maybe.” In this section, we present one general-purpose ontology that synthesizes ideas from those centuries. Two major characteristics of general-purpose ontologies distinguish them from collections of special-purpose ontologies:
A general-purpose ontology should be applicable in more or less any special-purpose domain (with the addition of domain-specific axioms). This means that no representational issue can be finessed or brushed under the carpet.
In any sufficiently demanding domain, different areas of knowledge must be unified, because reasoning and problem solving could involve several areas simultaneously. A robot circuit-repair system, for instance, needs to reason about circuits in terms of electrical connectivity and physical layout, and about time, both for circuit timing analysis and estimating labor costs. The sentences describing time therefore must be capable of being combined with those describing spatial layout and must work equally well for nanoseconds and minutes and for angstroms and meters.
We should say up front that the enterprise of general ontological engineering has so far had only limited success. None of the top AI applications (as listed in Chapter 1) make use of a shared ontology—they all use special-purpose knowledge engineering. Social/political considerations can make it difficult for competing parties to agree on an ontology. As Tom Gruber (2004) says, “Every ontology is a treaty—a social agreement—among people with some common motive in sharing.” When competing concerns outweigh the motivation for sharing, there can be no common ontology. Those ontologies that do exist have been created along four routes:
-
By a team of trained ontologist/logicians, who architect the ontology and write axioms. The CYC system was mostly built this way (Lenat and Guha, 1990).
-
By importing categories, attributes, and values from an existing database or databases. DBPEDIA was built by importing structured facts from Wikipedia (Bizer et al., 2007).
-
By parsing text documents and extracting information from them. TEXTRUNNER was built by reading a large corpus of Web pages (Banko and Etzioni, 2008).
-
By enticing unskilled amateurs to enter commonsense knowledge. The OPENMIND
system was built by volunteers who proposed facts in English (Singh et al., 2002; Chklovski and Gil, 2005).
CATEGORIES AND OBJECTS
The organization of objects into categories is a vital part of knowledge representation. Although interaction with the world takes place at the level of individual objects, much reasoning takes place at the level of categories. For example, a shopper would normally have the goal of buying a basketball, rather than a particular basketball such as BB~9~. Categories also serve to make predictions about objects once they are classified. One infers the presence of certain objects from perceptual input, infers category membership from the perceived properties of the objects, and then uses category information to make predictions about the objects. For example, from its green and yellow mottled skin, one-foot diameter, ovoid shape, red flesh, black seeds, and presence in the fruit aisle, one can infer that an object is a watermelon; from this, one infers that it would be useful for fruit salad.
There are two choices for representing categories in first-order logic: predicates and objects. That is, we can use the predicate Basketball (b), or we can reify1 the category as an object, Basketballs . We could then say Member(b,Basketballs), which we will abbreviate as b∈Basketballs , to say that b is a member of the category of basketballs. We say Subset(Basketballs ,Balls), abbreviated as Basketballs ⊂ Balls , to say that Basketballs is a subcategory of Balls . We will use subcategory, subclass, and subset interchangeably.
Categories serve to organize and simplify the knowledge base through inheritance.we say that all instances of the category Food are edible, and if we assert that Fruit is a subclass of Food and Apples is a subclass of Fruit , then we can infer that every apple is edible. We say that the individual apples inherit the property of edibility, in this case from their membership in the Food category.
Subclass relations organize categories into a taxonomy, or taxonomic hierarchy. Taxonomies have been used explicitly for centuries in technical fields. The largest such taxonomy organizes about 10 million living and extinct species, many of them beetles,2 into a single hierarchy; library science has developed a taxonomy of all fields of knowledge, encoded as the Dewey Decimal system; and tax authorities and other government departments have developed extensive taxonomies of occupations and commercial products. Taxonomies are also an important aspect of general commonsense knowledge.
First-order logic makes it easy to state facts about categories, either by relating objects to categories or by quantifying over their members. Here are some types of facts, with examples of each:
-
An object is a member of a category. BB~9~ ∈ Basketballs
-
A category is a subclass of another category. Basketballs ⊂ Balls
-
All members of a category have some properties. (x ∈ Basketballs) ⇒ Spherical (x)
1 Turning a proposition into an object is called reification,from the Latin word res, or thing. John McCarthy proposed the term “thingification,” but it never caught on. 2 The famous biologist J. B. S. Haldane deduced “An inordinate fondness for beetles” on the part of the Creator.
-
Members of a category can be recognized by some properties. Orange(x) ∧ Round(x) ∧Diameter(x)= 9.5′′ ∧ x ∈ Balls ⇒ x ∈ Basketballs
-
A category as a whole has some properties. Dogs ∈ DomesticatedSpecies
Notice that because Dogs is a category and is a member of DomesticatedSpecies , the latter must be a category of categories. Of course there are exceptions to many of the above rules (punctured basketballs are not spherical); we deal with these exceptions later.
Although subclass and member relations are the most important ones for categories, we also want to be able to state relations between categories that are not subclasses of each other. For example, if we just say that Males and Females are subclasses of Animals , then we have not said that a male cannot be a female. We say that two or more categories are disjoint if they have no members in common. And even if we know that males and females are disjoint, we will not know that an animal that is not a male must be a female, unless we say that males and females constitute an exhaustive decomposition of the animals. disjoint exhaustive decomposition is known as a partition. The following examples illustrate these three concepts:
Disjoint({Animals ,Vegetables})
ExhaustiveDecomposition({Americans ,Canadians ,Mexicans},
NorthAmericans)
Partition({Males ,Females},Animals) .
(Note that the ExhaustiveDecomposition of NorthAmericans is not a Partition , because some people have dual citizenship.) The three predicates are defined as follows:
Disjoint(s) ⇔ (∀ C~1~, C~2~ C~1~ ∈ s ∧ C~2~ ∈ s ∧ C~1~ ≠ C~2~ ⇒ Intersection(C~1~, C~2~)= { })
ExhaustiveDecomposition(s, c) ⇔ (∀ i i ∈ c ⇔ ∃ C~2~ C~2~ ∈ s ∧ i∈ C~2~)
Partition(s, c) ⇔ Disjoint(s) ∧ ExhaustiveDecomposition(s, c) .
Categories can also be defined by providing necessary and sufficient conditions for membership. For example, a bachelor is an unmarried adult male:
x ∈ Bachelors ⇔ Unmarried(x) ∧ x ∈ Adults ∧ x ∈ Males .
As we discuss in the sidebar on natural kinds on page 443, strict logical definitions for categories are neither always possible nor always necessary.
Physical composition
The idea that one object can be part of another is a familiar one. One’s nose is part of one’s head, Romania is part of Europe, and this chapter is part of this book. We use the general PartOf relation to say that one thing is part of another. Objects can be grouped into Part Of hierarchies, reminiscent of the Subset hierarchy:
PartOf (Bucharest ,Romania) PartOf (Romania ,EasternEurope) PartOf (EasternEurope ,Europe) PartOf (Europe ,Earth) .
The PartOf relation is transitive and reflexive; that is,
PartOf (x, y) ∧ PartOf (y, z) ⇒ PartOf (x, z) . PartOf (x, x) .
Therefore, we can conclude PartOf (Bucharest ,Earth). Categories of composite objects are often characterized by structural relations among parts. For example, a biped has two legs attached to a body:
Biped(a) ⇒ ∃ l~1~, l~2~, b Leg(l~1~) ∧ Leg(l~2~) ∧ Body(b) ∧
PartOf (l~1~, a) ∧ PartOf (l~2~, a) ∧ PartOf (b, a) ∧
Attached(l~1~, b) ∧ Attached(l~2~, b) ∧
l~1~ ≠ l~2~ ∧ [∀ l~3~ Leg(l~3~) ∧ PartOf (l~3~, a) ⇒ (l~3~ = l~1~ ∨ l~3~ = ~)] .
The notation for “exactly two” is a little awkward; we are forced to say that there are two legs, that they are not the same, and that if anyone proposes a third leg, it must be the same as one of the other two. In Section 12.5.2, we describe a formalism called description logic makes it easier to represent constraints like “exactly two.”
We can define a PartPartition relation analogous to the Partition relation for categories. (See Exercise 12.8.) An object is composed of the parts in its PartPartition and can be viewed as deriving some properties from those parts. For example, the mass of a composite object is the sum of the masses of the parts. Notice that this is not the case with categories, which have no mass, even though their elements might.
It is also useful to define composite objects with definite parts but no particular structure. For example, we might want to say “The apples in this bag weigh two pounds.” The temptation would be to ascribe this weight to the set of apples in the bag, but this would be a mistake because the set is an abstract mathematical concept that has elements but does not have weight. Instead, we need a new concept, which we will call a bunch. For example, if the apples are Apple1, Apple2, and Apple3, then
BunchOf ({Apple1,Apple2,Apple3})
denotes the composite object with the three apples as parts (not elements). We can then use the bunch as a normal, albeit unstructured, object. Notice that BunchOf ({x})= x. Furthermore, BunchOf (Apples) is the composite object consisting of all apples—not to be confused with Apples , the category or set of all apples.
We can define BunchOf in terms of the PartOf relation. Obviously, each element of s is part of BunchOf (s):
∀ x x ∈ s ⇒ PartOf (x,BunchOf (s)) .
Furthermore, BunchOf (s) is the smallest object satisfying this condition. In other words, BunchOf (s) must be part of any object that has all the elements of s as parts:
∀ y [∀ x x ∈ s ⇒ PartOf (x, y)] ⇒ PartOf (BunchOf (s), y) .
These axioms are an example of a general technique called logical minimization, which means defining an object as the smallest one satisfying certain conditions.
NATURAL KINDS
Some categories have strict definitions: an object is a triangle if and only if it is a polygon with three sides. On the other hand, most categories in the real world have no clear-cut definition; these are called natural kind categories. For example, tomatoes tend to be a dull scarlet; roughly spherical; with an indentation at the top where the stem was; about two to four inches in diameter; with a thin but tough skin; and with flesh, seeds, and juice inside. There is, however, variation: some tomatoes are yellow or orange, unripe tomatoes are green, some are smaller or larger than average, and cherry tomatoes are uniformly small. Rather than having a complete definition of tomatoes, we have a set of features that serves to identify objects that are clearly typical tomatoes, but might not be able to decide for other objects. (Could there be a tomato that is fuzzy like a peach?)
This poses a problem for a logical agent. The agent cannot be sure that an object it has perceived is a tomato, and even if it were sure, it could not be certain which of the properties of typical tomatoes this one has. This problem is an inevitable consequence of operating in partially observable environments.
One useful approach is to separate what is true of all instances of a category from what is true only of typical instances. So in addition to the category Tomatoes , we will also have the category Typical(Tomatoes). Here, the Typical
function maps a category to the subclass that contains only typical instances:
Typical(c) ⊆ c .
Most knowledge about natural kinds will actually be about their typical instances:
x ∈ Typical(Tomatoes) ⇒ Red (x) ∧ Round(x) .
Thus, we can write down useful facts about categories without exact definitions. The difficulty of providing exact definitions for most natural categories was explained in depth by Wittgenstein (1953). He used the example of games to show that members of a category shared “family resemblances” rather than necessary and sufficient characteristics: what strict definition encompasses chess, tag, solitaire, and dodgeball?
The utility of the notion of strict definition was also challenged by Quine (1953). He pointed out that even the definition of “bachelor” as an unmarried adult male is suspect; one might, for example, question a statement such as “the Pope is a bachelor.” While not strictly false, this usage is certainly infelicitous because it induces unintended inferences on the part of the listener. The tension could perhaps be resolved by distinguishing between logical definitions suitable for internal knowledge representation and the more nuanced criteria for felicitous linguistic usage. The latter may be achieved by “filtering” the assertions derived from the former. It is also possible that failures of linguistic usage serve as feedback for modifying internal definitions, so that filtering becomes unnecessary.
Measurements
In both scientific and commonsense theories of the world, objects have height, mass, cost, and so on. The values that we assign for these properties are called measures. Ordinary quantitative measures are quite easy to represent. We imagine that the universe includes abstract “measure objects,” such as the length that is the length of this line segment: . We can call this length 1.5 inches or 3.81 centimeters. Thus, the same length has different names in our language.We represent the length with a units function that takes a number as argument. (An alternative scheme is explored in Exer-UNITS FUNCTION
cise 12.9.) If the line segment is called l~1~, we can write
Length(l~1~)= Inches(1.5)= Centimeters(3.81) .
Conversion between units is done by equating multiples of one unit to another:
Centimeters(2.54 × d)= Inches(d) .
Similar axioms can be written for pounds and kilograms, seconds and days, and dollars and cents. Measures can be used to describe objects as follows:
Diameter(Basketball 12)= Inches(9.5) . ListPrice(Basketball 12)= $(19) . d ∈ Days ⇒ Duration(d)= Hours(24) .
Note that $(1) is not a dollar bill! One can have two dollar bills, but there is only one object named $(1). Note also that, while Inches(0) and Centimeters(0) refer to the same zero length, they are not identical to other zero measures, such as Seconds(0).
Simple, quantitative measures are easy to represent. Other measures present more of a problem, because they have no agreed scale of values. Exercises have difficulty, desserts have deliciousness, and poems have beauty, yet numbers cannot be assigned to these qualities. One might, in a moment of pure accountancy, dismiss such properties as useless for the purpose of logical reasoning; or, still worse, attempt to impose a numerical scale on beauty. This would be a grave mistake, because it is unnecessary. The most important aspect of measures is not the particular numerical values, but the fact that measures can be ordered.
Although measures are not numbers, we can still compare them, using an ordering symbol such as >. For example, we might well believe that Norvig’s exercises are tougher than Russell’s, and that one scores less on tougher exercises:
e~1~ ∈ Exercises ∧ e~2~ ∈ Exercises ∧W rote(Norvig , e~1~) ∧ Wrote(Russell , e~2~) ⇒
Difficulty(e~1~) > Difficulty(e~2~) .
e~1~ ∈ Exercises ∧ e~2~ ∈ Exercises ∧ Difficulty(e~1~) > Difficulty(e~2~) ⇒
ExpectedScore(e~1~) < ExpectedScore(e~2~) .
This is enough to allow one to decide which exercises to do, even though no numerical values for difficulty were ever used. (One does, however, have to discover who wrote which exercises.) These sorts of monotonic relationships among measures form the basis for the field of qualitative physics, a subfield of AI that investigates how to reason about physical systems without plunging into detailed equations and numerical simulations. Qualitative physics is discussed in the historical notes section.
Objects: Things and stuff
The real world can be seen as consisting of primitive objects (e.g., atomic particles) and composite objects built from them. By reasoning at the level of large objects such as apples and cars, we can overcome the complexity involved in dealing with vast numbers of primitive objects individually. There is, however, a significant portion of reality that seems to defy any obvious individuation—division into distinct objects. We give this portion the generic name stuff. For example, suppose I have some butter and an aardvark in front of me. I can say there is one aardvark, but there is no obvious number of “butter-objects,” because any part of a butter-object is also a butter-object, at least until we get to very small parts indeed. This is the major distinction between stuff and things. If we cut an aardvark in half, we do not get two aardvarks (unfortunately).
The English language distinguishes clearly between stuff and things. We say “an aardvark,” but, except in pretentious California restaurants, one cannot say “a butter.” Linguists distinguish between count nouns, such as aardvarks, holes, and theorems, and mass nouns, such as butter, water, and energy. Several competing ontologies claim to handle this distinction. Here we describe just one; the others are covered in the historical notes section.
To represent stuff properly, we begin with the obvious. We need to have as objects in our ontology at least the gross “lumps” of stuff we interact with. For example, we might recognize a lump of butter as the one left on the table the night before; we might pick it up, weigh it, sell it, or whatever. In these senses, it is an object just like the aardvark. Let us call it ButteR~3~. We also define the category Butter . Informally, its elements will be all those things of which one might say “It’s butter,” including ButteR~3~. With some caveats about very small parts that we w omit for now, any part of a butter-object is also a butter-object:
b ∈ Butter ∧ PartOf (p, b) ⇒ p ∈ Butter .
We can now say that butter melts at around 30 degrees centigrade:
b ∈ Butter ⇒ MeltingPoint(b,Centigrade(30)) .
We could go on to say that butter is yellow, is less dense than water, is soft at room temperature, has a high fat content, and so on. On the other hand, butter has no particular size, shape, or weight. We can define more specialized categories of butter such as UnsaltedButter , which is also a kind of stuff. Note that the category PoundOfButter , which includes as members all butter-objects weighing one pound, is not a kind of stuff. If we cut a pound of butter in half, we do not, alas, get two pounds of butter.
What is actually going on is this: some properties are intrinsic: they belong to the very substance of the object, rather than to the object as a whole. When you cut an instance of stuff in half, the two pieces retain the intrinsic properties—things like density, boiling point, flavor, color, ownership, and so on. On the other hand, their extrinsic properties—weight, length, shape, and so on—are not retained under subdivision. A category of objects that includes in its definition only intrinsic properties is then a substance, or mass noun; a class that includes any extrinsic properties in its definition is a count noun. The category Stuff is the most general substance category, specifying no intrinsic properties. The category Thing is the most general discrete object category, specifying no extrinsic properties.
EVENTS
In Section 10.4.2, we showed how situation calculus represents actions and their effects. Situation calculus is limited in its applicability: it was designed to describe a world in which actions are discrete, instantaneous, and happen one at a time. Consider a continuous action, such as filling a bathtub. Situation calculus can say that the tub is empty before the action and full when the action is done, but it can’t talk about what happens during the action. It also can’t describe two actions happening at the same time—such as brushing one’s teeth while waiting for the tub to fill. To handle such cases we introduce an alternative formalism known as event calculus, which is based on points of time rather than on situations.^3^
Event calculus reifies fluents and events. The fluent At(Shankar ,Berkeley) is an object that refers to the fact of Shankar being in Berkeley, but does not by itself say anything about whether it is true. To assert that a fluent is actually true at some point in time we use the predicate T , as in T (At(Shankar ,Berkeley), t).
Events are described as instances of event categories.^4^ The event E~1~ of Shankar flying from San Francisco to Washington, D.C. is described as
E~1~ ∈ Flyings ∧ Flyer(E~1~,Shankar ) ∧ Origin(E~1~,SF ) ∧ Destination(E~1~,DC ) .
If this is too verbose, we can define an alternative three-argument version of the category of flying events and say
E~1~ ∈ Flyings(Shankar ,SF ,DC ) .
We then use Happens(E~1~, i) to say that the event E~1~ took place over the time interval i, and we say the same thing in functional form with Extent(E~1~)= i. We represent time intervals by a (start, end) pair of times; that is, i = (t~1~, t~2~) is the time interval that starts at t~1~ and ends at t~2~. The complete set of predicates for one version of the event calculus is
T (f, t) Fluent f is true at time t
Happens(e, i) Event e happens over the time interval i
Initiates(e, f, t) Event e causes fluent f to start to hold at time t
Terminates(e, f, t) Event e causes fluent f to cease to hold at time t
Clipped (f, i) Fluent f ceases to be true at some point during time interval i
Restored (f, i) Fluent f becomes true sometime during time interval i
We assume a distinguished event, Start , that describes the initial state by saying which fluents are initiated or terminated at the start time. We define T by saying that a fluent holds at a point in time if the fluent was initiated by an event at some time in the past and was not made false (clipped) by an intervening event. A fluent does not hold if it was terminated by an event and
3 The terms “event” and “action” may be used interchangeably. Informally, “action” connotes an agent while “event” connotes the possibility of agentless actions. 4 Some versions of event calculus do not distinguish event categories from instances of the categories.
not made true (restored) by another event. Formally, the axioms are:
Happens(e, (t~1~, t~2~)) ∧ Initiates(e, f, t~1~) ∧ ¬Clipped(f, (t~1~, t)) ∧ t~1~ < t ⇒ T (f, t)
Happens(e, (t~1~, t~2~)) ∧ Terminates(e, f, t~1~) ∧ ¬Restored (f, (t~1~, t)) ∧ t~1~ < t ⇒ ¬T (f, t)
where Clipped and Restored are defined by Clipped (f, (t~1~, t~2~)) ⇔ ∃ e, t, t~3~ Happens(e, (t, t~3~)) ∧ t~1~ ≤ t < t~2~ ∧ Terminates(e, f, t)
Restored (f, (t~1~, t~2~)) ⇔ ∃ e, t, t~3~ Happens(e, (t, t~3~)) ∧ t~1~ ≤ t < t~2~ ∧ Initiates(e, f, t)
It is convenient to extend T to work over intervals as well as time points; a fluent holds over an interval if it holds on every point within the interval:
T (f, (t~1~, t~2~)) ⇔ [∀ t (t~1~ ≤ t < t~2~) ⇒ T (f, t)]
Fluents and actions are defined with domain-specific axioms that are similar to successorstate axioms. For example, we can say that the only way a wumpus-world agent gets an arrow is at the start, and the only way to use up an arrow is to shoot it:
Initiates(e,HaveArrow(a), t) ⇔ e = Start Terminates(e,HaveArrow(a), t) ⇔ e ∈ Shootings(a)
By reifying events we make it possible to add any amount of arbitrary information about them. For example, we can say that Shankar’s flight was bumpy with Bumpy(E~1~). In an ontology where events are n-ary predicates, there would be no way to add extra information like this; moving to an n + 1-ary predicate isn’t a scalable solution.
We can extend event calculus to make it possible to represent simultaneous events (such as two people being necessary to ride a seesaw), exogenous events (such as the wind blowing and changing the location of an object), continuous events (such as the level of water in the bathtub continuously rising) and other complications.
Processes
The events we have seen so far are what we call discrete events—they have a definite structure. Shankar’s trip has a beginning, middle, and end. If interrupted halfway, the event would be something different—it would not be a trip from San Francisco to Washington, but instead a trip from San Francisco to somewhere over Kansas. On the other hand, the category of events denoted by Flyings has a different quality. If we take a small interval of Shankar’s flight, say, the third 20-minute segment (while he waits anxiously for a bag of peanuts), that event is still a member of Flyings . In fact, this is true for any subinterval.
Categories of events with this property are called process categories or liquid eventcategories. Any process e that happens over an interval also happens over any subinterval:
(e ∈ Processes) ∧Happens(e, (t~1~, t~4~)) ∧ (t~1~ < t~2~ < t~3~ < t~4~) ⇒ Happens(e, (t~2~, t~3~)) .
The distinction between liquid and nonliquid events is exactly analogous to the difference between substances, or stuff, and individual objects, or things. In fact, some have called liquid events temporal substances, whereas substances like butter are spatial substances.
Time intervals
Event calculus opens us up to the possibility of talking about time, and time intervals. We will consider two kinds of time intervals: moments and extended intervals. The distinction is that only moments have zero duration:
Partition({Moments ,ExtendedIntervals}, Intervals) i ∈ Moments ⇔ Duration(i)= Seconds(0) .
Next we invent a time scale and associate points on that scale with moments, giving us absolute times. The time scale is arbitrary; we measure it in seconds and say that the moment at midnight (GMT) on January 1, 1900, has time 0. The functions Begin and End pick out the earliest and latest moments in an interval, and the function Time delivers the point on the time scale for a moment. The function Duration gives the difference between the end time and the start time.
Interval (i) ⇒ Duration(i)= (Time(End(i)) − Time(Begin(i))) .
Time(Begin(AD1900)) = Seconds(0) .
Time(Begin(AD2001)) = Seconds(3187324800) .
Time(End(AD2001)) = Seconds(3218860800) .
Duration(AD2001) = Seconds(31536000) .
To make these numbers easier to read, we also introduce a function Date , which takes six arguments (hours, minutes, seconds, day, month, and year) and returns a time point:
Time(Begin(AD2001))= Date(0, 0, 0, 1, Jan , 2001)
Date(0, 20, 21, 24, 1, 1995)=Seconds(3000000000) .
Two intervals Meet if the end time of the first equals the start time of the second. The complete set of interval relations, as proposed by Allen (1983), is shown graphically in Figure 12.2 and logically below:
Meet(i, j) ⇔ End(i)= Begin(j)
Before(i, j) ⇔ End(i) < Begin(j)
After(j, i) ⇔ Before(i, j)
During(i, j) ⇔ Begin(j) < Begin(i) < End(i) < End(j)
Overlap(i, j) ⇔ Begin(i) < Begin(j) < End(i) < End(j)
Begins(i, j) ⇔ Begin(i) = Begin(j)
Finishes(i, j) ⇔ End(i) = End(j)
Equals(i, j) ⇔ Begin(i) = Begin(j) ∧ End(i) = End(j)
These all have their intuitive meaning, with the exception of Overlap: we tend to think of overlap as symmetric (if i overlaps j then j overlaps i), but in this definition, Overlap(i, j) only holds if i begins before j. To say that the reign of Elizabeth II immediately followed that of George VI, and the reign of Elvis overlapped with the 1950s, we can write the following:
Meets(ReignOf (GeorgeVI ),ReignOf (ElizabethII )) .
Overlap(Fifties ,ReignOf (Elvis)) .
Begin(Fifties)= Begin(AD1950) .
End(Fifties)=End(AD1959) .
Section 12.3. Events 449
Fluents and objects
Physical objects can be viewed as generalized events, in the sense that a physical object is a chunk of space–time. For example, USA can be thought of as an event that began in, say, 1776 as a union of 13 states and is still in progress today as a union of 50. We can describe the changing properties of USA using state fluents, such as Population(USA). A property of the USA that changes every four or eight years, barring mishaps, is its president. One might propose that President(USA) is a logical term that denotes a different object at different times. Unfortunately, this is not possible, because a term denotes exactly one object in a given model structure. (The term President(USA, t) can denote different objects, depending on the value of t, but our ontology keeps time indices separate from fluents.) The only possibility is that President(USA) denotes a single object that consists of different people at different times. It is the object that is George Washington from 1789 to 1797, John Adams from 1797 to 1801, and so on, as in Figure 12.3. To say that George Washington was president throughout 1790, we can write
T (Equals(President(USA),GeorgeWashington ),AD1790) .
We use the function symbol Equals rather than the standard logical predicate =, because we cannot have a predicate as an argument to T , and because the interpretation is not that GeorgeWashington and President(USA) are logically identical in 1790; logical identity is not something that can change over time. The identity is between the subevents of each object that are defined by the period 1790.
MENTAL EVENTS AND MENTAL OBJECTS
The agents we have constructed so far have beliefs and can deduce new beliefs. Yet none of them has any knowledge about beliefs or about deduction. Knowledge about one’s own knowledge and reasoning processes is useful for controlling inference. For example, suppose Alice asks “what is the square root of 1764” and Bob replies “I don’t know.” If Alice insists “think harder,” Bob should realize that with some more thought, this question can in fact be answered. On the other hand, if the question were “Is your mother sitting down right now?” then Bob should realize that thinking harder is unlikely to help. Knowledge about the knowledge of other agents is also important; Bob should realize that his mother knows whether she is sitting or not, and that asking her would be a way to find out.
What we need is a model of the mental objects that are in someone’s head (or something’s knowledge base) and of the mental processes that manipulate those mental objects. The model does not have to be detailed. We do not have to be able to predict how many milliseconds it will take for a particular agent to make a deduction. We will be happy just to be able to conclude that mother knows whether or not she is sitting.
We begin with the propositional attitudes that an agent can have toward mental objects: attitudes such as Believes, Knows , Wants , Intends , and Informs . The difficulty is that these attitudes do not behave like “normal” predicates. For example, suppose we try to assert that Lois knows that Superman can fly:
Knows(Lois ,CanFly(Superman)) .
One minor issue with this is that we normally think of CanFly(Superman) as a sentence, but here it appears as a term. That issue can be patched up just be reifying CanFly(Superman); making it a fluent. A more serious problem is that, if it is true that Superman is Clark Kent, then we must conclude that Lois knows that Clark can fly:
(Superman = Clark) ∧Knows(Lois ,CanFly(Superman)) |= Knows(Lois ,CanFly(Clark )) .
This is a consequence of the fact that equality reasoning is built into logic. Normally that is a good thing; if our agent knows that 2 + 2 = 4 and 4 < 5, then we want our agent to know that 2 + 2 < 5. This property is called referential transparency—it doesn’t matter what term a logic uses to refer to an object, what matters is the object that the term names. But for propositional attitudes like believes and knows, we would like to have referential opacity—the terms used do matter, because not all agents know which terms are co-referential.
Modal logic is designed to address this problem. Regular logic is concerned with a single modality, the modality of truth, allowing us to express “P is true.” Modal logic includes special modal operators that take sentences (rather than terms) as arguments. For example, “A knows P” is represented with the notation K~A~P , where K is the modal operator for knowledge. It takes two arguments, an agent (written as the subscript) and a sentence. The syntax of modal logic is the same as first-order logic, except that sentences can also be formed with modal operators.
The semantics of modal logic is more complicated. In first-order logic a model contains a set of objects and an interpretation that maps each name to the appropriate object, relation, or function. In modal logic we want to be able to consider both the possibility that Superman’s secret identity is Clark and that it isn’t. Therefore, we will need a more complicated model, one that consists of a collection of possible worlds rather than just one true world. The worlds are connected in a graph by accessibility relations, one relation for each modal operator. We say that world w~1~ is accessible from world w~0~ with respect to the modal operator K~A~ if everything in w~1~ is consistent with what A knows in w~0~, and we write this as Acc(K~A~, w~0~, w~1~). In diagrams such as Figure 12.4 we show accessibility as an arrow between possible worlds. As an example, in the real world, Bucharest is the capital of Romania, but for an agent that did not know that, other possible worlds are accessible, including ones where the capital of Romania is Sibiu or Sofia. Presumably a world where 2 + 2 = 5 would not be accessible to any agent.
In general, a knowledge atom K~A~P is true in world w if and only if P is true in every world accessible from w. The truth of more complex sentences is derived by recursive application of this rule and the normal rules of first-order logic. That means that modal logic can be used to reason about nested knowledge sentences: what one agent knows about another agent’s knowledge. For example, we can say that, even though Lois doesn’t know whether Superman’s secret identity is Clark Kent, she does know that Clark knows:
KLois [KClark Identity(Superman ,Clark ) ∨KClark¬Identity(Superman ,Clark )]
Figure 12.4 shows some possible worlds for this domain, with accessibility relations for Lois and Superman.
In the TOP-LEFT diagram, it is common knowledge that Superman knows his own identity, and neither he nor Lois has seen the weather report. So in w~0~ the worlds w~0~ and w2 are accessible to Superman; maybe rain is predicted, maybe not. For Lois all four worlds are accessible from each other; she doesn’t know anything about the report or if Clark is Superman. But she does know that Superman knows whether he is Clark, because in every world that is accessible to Lois, either Superman knows I , or he knows ¬I . Lois does not know which is the case, but either way she knows Superman knows.
In the TOP-RIGHT diagram it is common knowledge that Lois has seen the weather report. So in w~4~ she knows rain is predicted and in w~6~ she knows rain is not predicted.
Superman does not know the report, but he knows that Lois knows, because in every world that is accessible to him, either she knows R or she knows ¬R.
In the BOTTOM diagram we represent the scenario where it is common knowledge that Superman knows his identity, and Lois might or might not have seen the weather report. We represent this by combining the two top scenarios, and adding arrows to show that Superman does not know which scenario actually holds. Lois does know, so we don’t need to add any arrows for her. In w~0~ Superman still knows I but not R, and now he does not know whether Lois knows R. From what Superman knows, he might be in w~0~ or w2, in which case Lois does not know whether R is true, or he could be in w~4~, in which case she knows R, or w~6~, in which case she knows ¬R.
There are an infinite number of possible worlds, so the trick is to introduce just the ones you need to represent what you are trying to model. A new possible world is needed to talk about different possible facts (e.g., rain is predicted or not), or to talk about different states of knowledge (e.g., does Lois know that rain is predicted). That means two possible worlds, such as w~4~ and w~0~ in Figure 12.4, might have the same base facts about the world, but differ in their accessibility relations, and therefore in facts about knowledge.
Modal logic solves some tricky issues with the interplay of quantifiers and knowledge. The English sentence “Bond knows that someone is a spy” is ambiguous. The first reading is that there is a particular someone who Bond knows is a spy; we can write this as
∃ x K~Bond~Spy(x) ,
which in modal logic means that there is an x that, in all accessible worlds, Bond knows to be a spy. The second reading is that Bond just knows that there is at least one spy:
K~Bond~∃x Spy(x) .
The modal logic interpretation is that in each accessible world there is an x that is a spy, but it need not be the same x in each world.
Now that we have a modal operator for knowledge, we can write axioms for it. First, we can say that agents are able to draw deductions; if an agent knows P and knows that P
implies Q, then the agent knows Q:
(K~a~P ∧K~a~(P ⇒ Q)) ⇒ K~a~Q .
From this (and a few other rules about logical identities) we can establish that K~A~(P ∨ ¬P )
is a tautology; every agent knows every proposition P is either true or false. On the other hand, (K~A~P ) ∨ (K~A~¬P ) is not a tautology; in general, there will be lots of propositions that an agent does not know to be true and does not know to be false.
It is said (going back to Plato) that knowledge is justified true belief. That is, if it is true, if you believe it, and if you have an unassailably good reason, then you know it. That means that if you know something, it must be true, and we have the axiom:
K~a~P ⇒ P .
Furthermore, logical agents should be able to introspect on their own knowledge. If they know something, then they know that they know it:
K~a~P ⇒ K~a~(K~a~P ) .
We can define similar axioms for belief (often denoted by B) and other modalities. However, one problem with the modal logic approach is that it assumes logical omniscience on the part of agents. That is, if an agent knows a set of axioms, then it knows all consequences of those axioms. This is on shaky ground even for the somewhat abstract notion of knowledge, but it seems even worse for belief, because belief has more connotation of referring to things that are physically represented in the agent, not just potentially derivable. There have been attempts to define a form of limited rationality for agents; to say that agents believe those assertions that can be derived with the application of no more than k reasoning steps, or no more than s seconds of computation. These attempts have been generally unsatisfactory.
REASONING SYSTEMS FOR CATEGORIES
Categories are the primary building blocks of large-scale knowledge representation schemes. This section describes systems specially designed for organizing and reasoning with categories. There are two closely related families of systems: semantic networks provide graphical aids for visualizing a knowledge base and efficient algorithms for inferring properties of an object on the basis of its category membership; and description logics provide a formal language for constructing and combining category definitions and efficient algorithms for deciding subset and superset relationships between categories.
Semantic networks
In 1909, Charles S. Peirce proposed a graphical notation of nodes and edges called existential graphs that he called “the logic of the future.” Thus began a long-running debate between advocates of “logic” and advocates of “semantic networks.” Unfortunately, the debate obscured the fact that semantics networks—at least those with well-defined semantics—are a form of logic. The notation that semantic networks provide for certain kinds of sentences is often more convenient, but if we strip away the “human interface” issues, the underlying concepts—objects, relations, quantification, and so on—are the same.
There are many variants of semantic networks, but all are capable of representing individual objects, categories of objects, and relations among objects. A typical graphical notation displays object or category names in ovals or boxes, and connects them with labeled links. For example, Figure 12.5 has a MemberOf link between Mary and FemalePersons , corresponding to the logical assertion Mary ∈FemalePersons ; similarly, the SisterOf link between Mary and John corresponds to the assertion SisterOf (Mary , John). We can connect categories using SubsetOf links, and so on. It is such fun drawing bubbles and arrows that one can get carried away. For example, we know that persons have female persons as mothers, so can we draw a HasMother link from Persons to FemalePersons? The answer is no, because HasMother is a relation between a person and his or her mother, and categories do not have mothers.5
For this reason, we have used a special notation—the double-boxed link—in Figure 12.5. This link asserts that
∀ x x ∈ Persons ⇒ [∀ y HasMother(x, y) ⇒ y ∈FemalePersons ] .
We might also want to assert that persons have two legs—that is,
∀ x x ∈ Persons ⇒ Legs(x, 2) .
As before, we need to be careful not to assert that a category has legs; the single-boxed link in Figure 12.5 is used to assert properties of every member of a category.
The semantic network notation makes it convenient to perform inheritance reasoning of the kind introduced in Section 12.2. For example, by virtue of being a person, Mary inherits the property of having two legs. Thus, to find out how many legs Mary has, the inheritance algorithm follows the MemberOf link from Mary to the category she belongs to, and then follows SubsetOf links up the hierarchy until it finds a category for which there is a boxed Legs link—in this case, the Persons category. The simplicity and efficiency of this inference
5 Several early systems failed to distinguish between properties of members of a category and properties of the category as a whole. This can lead directly to inconsistencies, as pointed out by Drew McDermott (1976) in his article “Artificial Intelligence Meets Natural Stupidity.” Another common problem was the use of IsA links for both subset and membership relations, in correspondence with English usage: “a cat is a mammal” and “Fifi is a cat.” See Exercise 12.22 for more on these issues.
mechanism, compared with logical theorem proving, has been one of the main attractions of semantic networks.
Inheritance becomes complicated when an object can belong to more than one category or when a category can be a subset of more than one other category; this is called multiple inheritance. In such cases, the inheritance algorithm might find two or more conflicting values answering the query. For this reason, multiple inheritance is banned in some object-oriented programming (OOP) languages, such as Java, that use inheritance in a class hierarchy. It is usually allowed in semantic networks, but we defer discussion of that until Section 12.6.
The reader might have noticed an obvious drawback of semantic network notation, compared to first-order logic: the fact that links between bubbles represent only binary relations. For example, the sentence Fly(Shankar ,NewYork ,NewDelhi ,Yesterday) cannot be asserted directly in a semantic network. Nonetheless, we can obtain the effect of n-ary assertions by reifying the proposition itself as an event belonging to an appropriate event category. Figure 12.6 shows the semantic network structure for this particular event. Notice that the restriction to binary relations forces the creation of a rich ontology of reified concepts.
Reification of propositions makes it possible to represent every ground, function-free atomic sentence of first-order logic in the semantic network notation. Certain kinds of universally quantified sentences can be asserted using inverse links and the singly boxed and doubly boxed arrows applied to categories, but that still leaves us a long way short of full first-order logic. Negation, disjunction, nested function symbols, and existential quantification are all missing. Now it is possible to extend the notation to make it equivalent to first-order logic—as in Peirce’s existential graphs—but doing so negates one of the main advantages of semantic networks, which is the simplicity and transparency of the inference processes. Designers can build a large network and still have a good idea about what queries will be efficient, because (a) it is easy to visualize the steps that the inference procedure will go through and (b) in some cases the query language is so simple that difficult queries cannot be posed. In cases where the expressive power proves to be too limiting, many semantic network systems provide for procedural attachment to fill in the gaps. Procedural attachment is a technique whereby a query about (or sometimes an assertion of) a certain relation results in a call to a special procedure designed for that relation rather than a general inference algorithm.
One of the most important aspects of semantic networks is their ability to represent default values for categories. Examining Figure 12.5 carefully, one notices that John has one leg, despite the fact that he is a person and all persons have two legs. In a strictly logical KB, this would be a contradiction, but in a semantic network, the assertion that all persons have two legs has only default status; that is, a person is assumed to have two legs unless this is contradicted by more specific information. The default semantics is enforced naturally by the inheritance algorithm, because it follows links upwards from the object itself (John in this case) and stops as soon as it finds a value. We say that the default is overridden by the more specific value. Notice that we could also override the default number of legs by creating a category of OneLeggedPersons , a subset of Persons of which John is a member.
We can retain a strictly logical semantics for the network if we say that the Legs assertion for Persons includes an exception for John:
∀ x x ∈ Persons ∧ x ≠ John ⇒ Legs(x, 2) .
For a fixed network, this is semantically adequate but will be much less concise than the network notation itself if there are lots of exceptions. For a network that will be updated with more assertions, however, such an approach fails—we really want to say that any persons as yet unknown with one leg are exceptions too. Section 12.6 goes into more depth on this issue and on default reasoning in general.
Description logics
The syntax of first-order logic is designed to make it easy to say things about objects. Description logics are notations that are designed to make it easier to describe definitions and properties of categories. Description logic systems evolved from semantic networks in response to pressure to formalize what the networks mean while retaining the emphasis on taxonomic structure as an organizing principle.
The principal inference tasks for description logics are subsumption (checking if one category is a subset of another by comparing their definitions) and classification (checking whether an object belongs to a category).. Some systems also include consistency of a category definition—whether the membership criteria are logically satisfiable.
Concept → Thing | ConceptName
| And(Concept , . . .)
| All(RoleName ,Concept )
| AtLeast(Integer ,RoleName)
| AtMost(Integer ,RoleName)
| Fills(RoleName , IndividualName , . . .)
| SameAs(Path ,Path)
| OneOf(IndividualName , . . .)
Path → [RoleName , . . .]
Figure 12.7 The syntax of descriptions in a subset of the CLASSIC language.
The CLASSIC language (Borgida et al., 1989) is a typical description logic. The syntax of CLASSIC descriptions is shown in Figure 12.7.6 For example, to say that bachelors are unmarried adult males we would write
Bachelor = And(Unmarried ,Adult ,Male) .
The equivalent in first-order logic would be
Bachelor (x) ⇔ Unmarried(x) ∧ Adult(x) ∧ Male(x) .
Notice that the description logic has an an algebra of operations on predicates, which of course we can’t do in first-order logic. Any description in CLASSIC can be translated into an equivalent first-order sentence, but some descriptions are more straightforward in CLASSIC. For example, to describe the set of men with at least three sons who are all unemployed and married to doctors, and at most two daughters who are all professors in physics or math departments, we would use
And(Man ,AtLeast(3,Son),AtMost(2,Daughter),
All(Son ,And(Unemployed ,Married ,All(Spouse ,Doctor ))),
All(Daughter ,And(Professor ,Fills(Department ,Physics ,Math)))) .
We leave it as an exercise to translate this into first-order logic. Perhaps the most important aspect of description logics is their emphasis on tractability of inference. A problem instance is solved by describing it and then asking if it is subsumed by one of several possible solution categories. In standard first-order logic systems, predicting the solution time is often impossible. It is frequently left to the user to engineer the representation to detour around sets of sentences that seem to be causing the system to take several weeks to solve a problem. The thrust in description logics, on the other hand, is to ensure that subsumption-testing can be solved in time polynomial in the size of the descriptions.7
6 Notice that the language does not allow one to simply state that one concept, or category, is a subset of another. This is a deliberate policy: subsumption between categories must be derivable from some aspects of the descriptions of the categories. If not, then something is missing from the descriptions. 7 CLASSIC provides efficient subsumption testing in practice, but the worst-case run time is exponential.
This sounds wonderful in principle, until one realizes that it can only have one of two consequences: either hard problems cannot be stated at all, or they require exponentially large descriptions! However, the tractability results do shed light on what sorts of constructs cause problems and thus help the user to understand how different representations behave. For example, description logics usually lack negation and disjunction. Each forces firstorder logical systems to go through a potentially exponential case analysis in order to ensure completeness. CLASSIC allows only a limited form of disjunction in the Fills and One Of constructs, which permit disjunction over explicitly enumerated individuals but not over descriptions. With disjunctive descriptions, nested definitions can lead easily to an exponential number of alternative routes by which one category can subsume another.
REASONING WITH DEFAULT INFORMATION
In the preceding section, we saw a simple example of an assertion with default status: people have two legs. This default can be overridden by more specific information, such as that Long John Silver has one leg. We saw that the inheritance mechanism in semantic networks implements the overriding of defaults in a simple and natural way. In this section, we study defaults more generally, with a view toward understanding the semantics of defaults rather than just providing a procedural mechanism.
Circumscription and default logic
We have seen two examples of reasoning processes that violate the monotonicity property of logic that was proved in Chapter 7.8 In this chapter we saw that a property inherited by all members of a category in a semantic network could be overridden by more specific information for a subcategory. In Section 9.4.5, we saw that under the closed-world assumption, if a proposition α is not mentioned in KB then KB |= ¬α, but KB ∧ α |= α.
Simple introspection suggests that these failures of monotonicity are widespread in commonsense reasoning. It seems that humans often “jump to conclusions.” For example, when one sees a car parked on the street, one is normally willing to believe that it has four wheels even though only three are visible. Now, probability theory can certainly provide a conclusion that the fourth wheel exists with high probability, yet, for most people, the possibility of the car’s not having four wheels does not arise unless some new evidence presents itself. Thus, it seems that the four-wheel conclusion is reached by default, in the absence of any reason to doubt it. If new evidence arrives—for example, if one sees the owner carrying a wheel and notices that the car is jacked up—then the conclusion can be retracted. This kind of reasoning is said to exhibit nonmonotonicity, because the set of beliefs does not grow monotonically over time as new evidence arrives. Nonmonotonic logics have been devised with modified notions of truth and entailment in order to capture such behavior. We will look at two such logics that have been studied extensively: circumscription and default logic.
8 Recall that monotonicity requires all entailed sentences to remain entailed after new sentences are added to the KB. That is, if KB |= α then KB ∧ β |= α.
Circumscription can be seen as a more powerful and precise version of the closedworld assumption. The idea is to specify particular predicates that are assumed to be “as false as possible”—that is, false for every object except those for which they are known to be true. For example, suppose we want to assert the default rule that birds fly. We would introduce a predicate, say Abnormal~1~(x), and write
Bird(x) ∧ ¬Abnormal~1~(x) ⇒ Flies(x) .
If we say that Abnormal 1 is to be circumscribed, a circumscriptive reasoner is entitled to assume ¬Abnormal~1~(x) unless Abnormal~1~(x) is known to be true. This allows the conclusion Flies(Tweety) to be drawn from the premise Bird(Tweety), but the conclusion no longer holds if Abnormal~1~(Tweety) is asserted.
Circumscription can be viewed as an example of a model preference logic. In such logics, a sentence is entailed (with default status) if it is true in all preferred models of the KB, as opposed to the requirement of truth in all models in classical logic. For circumscription, one model is preferred to another if it has fewer abnormal objects.9 Let us see how this idea works in the context of multiple inheritance in semantic networks. The standard example for which multiple inheritance is problematic is called the “Nixon diamond.” It arises from the observation that Richard Nixon was both a Quaker (and hence by default a pacifist) and a Republican (and hence by default not a pacifist). We can write this as follows:
Republican(Nixon) ∧Quaker(Nixon) .
Republican(x) ∧ ¬Abnormal~2~(x) ⇒ ¬Pacifist(x) .
Quaker(x) ∧ ¬Abnormal~3~(x) ⇒ Pacifist(x) .
If we circumscribe Abnormal~2~ and Abnormal~3~, there are two preferred models: one in which Abnormal 2(Nixon) and Pacifist(Nixon) hold and one in which Abnormal 3(Nixon) and ¬Pacifist(Nixon) hold. Thus, the circumscriptive reasoner remains properly agnostic as to whether Nixon was a pacifist. If we wish, in addition, to assert that religious beliefs take precedence over political beliefs, we can use a formalism called prioritized circumscription to give preference to models where Abnormal~3~ is minimized. Default logic is a formalism in which default rules can be written to generate contingent, nonmonotonic conclusions. A default rule looks like this:
Bird(x) : Flies(x)/Flies(x) .
This rule means that if Bird(x) is true, and if Flies(x) is consistent with the knowledge base, then Flies(x) may be concluded by default. In general, a default rule has the form
P : J~1~, . . . , J~n~/C
where P is called the prerequisite, C is the conclusion, and Ji are the justifications—if any one of them can be proven false, then the conclusion cannot be drawn. Any variable that
9 For the closed-world assumption, one model is preferred to another if it has fewer true atoms—that is, preferred models are minimal models. There is a natural connection between the closed-world assumption and definiteclause KBs, because the fixed point reached by forward chaining on definite-clause KBs is the unique minimal model. See page 258 for more on this point.
appears in Ji or C must also appear in P . The Nixon-diamond example can be represented in default logic with one fact and two default rules:
Republican(Nixon) ∧ Quaker(Nixon) .
Republican(x) : ¬Pacifist(x)/¬Pacifist(x) .
Quaker(x) : Pacifist(x)/Pacifist(x) .
To interpret what the default rules mean, we define the notion of an extension of a default theory to be a maximal set of consequences of the theory. That is, an extension S consists of the original known facts and a set of conclusions from the default rules, such that no additional conclusions can be drawn from S and the justifications of every default conclusion in S are consistent with S. As in the case of the preferred models in circumscription, we have two possible extensions for the Nixon diamond: one wherein he is a pacifist and one wherein he is not. Prioritized schemes exist in which some default rules can be given precedence over others, allowing some ambiguities to be resolved.
Since 1980, when nonmonotonic logics were first proposed, a great deal of progress has been made in understanding their mathematical properties. There are still unresolved questions, however. For example, if “Cars have four wheels” is false, what does it mean to have it in one’s knowledge base? What is a good set of default rules to have? If we cannot decide, for each rule separately, whether it belongs in our knowledge base, then we have a serious problem of nonmodularity. Finally, how can beliefs that have default status be used to make decisions? This is probably the hardest issue for default reasoning. Decisions often involve tradeoffs, and one therefore needs to compare the strengths of belief in the outcomes of different actions, and the costs of making a wrong decision. In cases where the same kinds of decisions are being made repeatedly, it is possible to interpret default rules as “threshold probability” statements. For example, the default rule “My brakes are always OK” really means “The probability that my brakes are OK, given no other information, is sufficiently high that the optimal decision is for me to drive without checking them.” When the decision context changes—for example, when one is driving a heavily laden truck down a steep mountain road—the default rule suddenly becomes inappropriate, even though there is no new evidence of faulty brakes. These considerations have led some researchers to consider how to embed default reasoning within probability theory or utility theory.
Truth maintenance systems
We have seen that many of the inferences drawn by a knowledge representation system will have only default status, rather than being absolutely certain. Inevitably, some of these inferred facts will turn out to be wrong and will have to be retracted in the face of new information. This process is called belief revision.10 Suppose that a knowledge base KB contains a sentence P—perhaps a default conclusion recorded by a forward-chaining algorithm, or perhaps just an incorrect assertion—and we want to execute TELL(KB , ¬P ). To avoid creating a contradiction, we must first execute RETRACT(KB , P ). This sounds easy enough.
10 Belief revision is often contrasted with belief update, which occurs when a knowledge base is revised to reflect a change in the world rather than new information about a fixed world. Belief update combines belief revision with reasoning about time and change; it is also related to the process of filtering described in Chapter 15.
Problems arise, however, if any additional sentences were inferred from P and asserted in the KB. For example, the implication P ⇒ Q might have been used to add Q. The obvious “solution”—retracting all sentences inferred from P—fails because such sentences may have other justifications besides P . For example, if R and R ⇒ Q are also in the KB, then Q does not have to be removed after all. Truth maintenance systems, or TMSs, are designed to handle exactly these kinds of complications.
One simple approach to truth maintenance is to keep track of the order in which sentences are told to the knowledge base by numbering them from P~1~ to p~n~. When the call RETRACT(KB , p~i~) is made, the system reverts to the state just before p~i~ was added, thereby removing both p~i~ and any inferences that were derived from p~i~. The sentences p~i~+1 through p~n~ can then be added again. This is simple, and it guarantees that the knowledge base will be consistent, but retracting p~i~ requires retracting and reasserting n − i sentences as well as undoing and redoing all the inferences drawn from those sentences. For systems to which many facts are being added—such as large commercial databases—this is impractical.
A more efficient approach is the justification-based truth maintenance system, or JTMS.
In a JTMS, each sentence in the knowledge base is annotated with a justification consisting of the set of sentences from which it was inferred. For example, if the knowledge base already contains P ⇒ Q, then TELL(P ) will cause Q to be added with the justification {P, P ⇒ Q}. In general, a sentence can have any number of justifications. Justifications make retraction efficient. Given the call RETRACT(P ), the JTMS will delete exactly those sentences for which P is a member of every justification. So, if a sentence Q had the single justification {P, P ⇒ Q}, it would be removed; if it had the additional justification {P, P ∨ R ⇒ Q}, it would still be removed; but if it also had the justification {R, P ∨R ⇒ Q}, then it would be spared. In this way, the time required for retraction of P depends only on the number of sentences derived from P rather than on the number of other sentences added since P entered the knowledge base.
The JTMS assumes that sentences that are considered once will probably be considered again, so rather than deleting a sentence from the knowledge base entirely when it loses all justifications, we merely mark the sentence as being out of the knowledge base. If a subsequent assertion restores one of the justifications, then we mark the sentence as being back in. In this way, the JTMS retains all the inference chains that it uses and need not rederive sentences when a justification becomes valid again.
In addition to handling the retraction of incorrect information, TMSs can be used to speed up the analysis of multiple hypothetical situations. Suppose, for example, that the Romanian Olympic Committee is choosing sites for the swimming, athletics, and equestrian events at the 2048 Games to be held in Romania. For example, let the first hypothesis be Site(Swimming ,Pitesti), Site(Athletics ,Bucharest), and Site(Equestrian,Arad). A great deal of reasoning must then be done to work out the logistical consequences and hence the desirability of this selection. If we want to consider Site(Athletics ,Sibiu) instead, the TMS avoids the need to start again from scratch. Instead, we simply retract Site(Athletics ,Bucharest) and assert Site(Athletics,Sibiu) and the TMS takes care of the necessary revisions. Inference chains generated from the choice of Bucharest can be reused with Sibiu, provided that the conclusions are the same.
An assumption-based truth maintenance system, or ATMS, makes this type of context switching between hypothetical worlds particularly efficient. In a JTMS, the maintenance of justifications allows you to move quickly from one state to another by making a few retractions and assertions, but at any time only one state is represented. An ATMS represents all the states that have ever been considered at the same time. Whereas a JTMS simply labels each sentence as being in or out, an ATMS keeps track, for each sentence, of which assumptions would cause the sentence to be true. In other words, each sentence has a label that consists of a set of assumption sets. The sentence holds just in those cases in which all the assumptions in one of the assumption sets hold.
Truth maintenance systems also provide a mechanism for generating explanations Technically, an explanation of a sentence P is a set of sentences E such that E entails P . If the sentences in E are already known to be true, then E simply provides a sufficient basis for proving that P must be the case. But explanations can also include assumptions sentences that are not known to be true, but would suffice to prove P if they were true. For example, one might not have enough information to prove that one’s car won’t start, but a reasonable explanation might include the assumption that the battery is dead. This, combined with knowledge of how cars operate, explains the observed nonbehavior. In most cases, we will prefer an explanation E that is minimal, meaning that there is no proper subset of E that is also an explanation. An ATMS can generate explanations for the “car won’t start” problem by making assumptions (such as “gas in car” or “battery dead”) in any order we like, even if some assumptions are contradictory. Then we look at the label for the sentence “car won’t start” to read off the sets of assumptions that would justify the sentence.
The exact algorithms used to implement truth maintenance systems are a little complicated, and we do not cover them here. The computational complexity of the truth maintenance problem is at least as great as that of propositional inference—that is, NP-hard. Therefore, you should not expect truth maintenance to be a panacea. When used carefully, however, a TMS can provide a substantial increase in the ability of a logical system to handle complex environments and hypotheses.
THE INTERNET SHOPPING WORLD
In this final section we put together all we have learned to encode knowledge for a shopping research agent that helps a buyer find product offers on the Internet. The shopping agent is given a product description by the buyer and has the task of producing a list of Web pages that offer such a product for sale, and ranking which offers are best. In some cases the buyer’s product description will be precise, as in Canon Rebel XTi digital camera, and the task is then to find the store(s) with the best offer. In other cases the description will be only partially specified, as in digital camera for under $300, and the agent will have to compare different products.
The shopping agent’s environment is the entire World Wide Web in its full complexity— not a toy simulated environment. The agent’s percepts are Web pages, but whereas a human
Example Online Store Select from our fine line of products:
- Computers
- Cameras
- Books
- Videos
- Music
<h~1~>Example Online Store</h~1~> Select from our fine line of products:
Figure 12.8 A Web page from a generic online store in the form perceived by the human user of a browser (top), and the corresponding HTML string as perceived by the browser or the shopping agent (bottom). In HTML, characters between < and > are markup directives that specify how the page is displayed. For example, the string Select means to switch to italic font, display the word Select, and then end the use of italic font. A page identifier such as http://example.com/books is called a uniform resource locator (URL). The markup Books means to create a hypertext link to url with the anchor text Books.
Web user would see pages displayed as an array of pixels on a screen, the shopping agent will perceive a page as a character string consisting of ordinary words interspersed with formatting commands in the HTML markup language. Figure 12.8 shows a Web page and a corresponding HTML character string. The perception problem for the shopping agent involves extracting useful information from percepts of this kind.
Clearly, perception on Web pages is easier than, say, perception while driving a taxi in Cairo. Nonetheless, there are complications to the Internet perception task. The Web page in Figure 12.8 is simple compared to real shopping sites, which may include CSS, cookies, Java, Javascript, Flash, robot exclusion protocols, malformed HTML, sound files, movies, and text that appears only as part of a JPEG image. An agent that can deal with all of the Internet is almost as complex as a robot that can move in the real world. We concentrate on a simple agent that ignores most of these complications.
The agent’s first task is to collect product offers that are relevant to a query. If the query is “laptops,” then a Web page with a review of the latest high-end laptop would be relevant, but if it doesn’t provide a way to buy, it isn’t an offer. For now, we can say a page is an offer if it contains the words “buy” or “price” or “add to cart” within an HTML link or form on the page. For example, if the page contains a string of the form “<a . . .add to cart . . .</a” then it is an offer. This could be represented in first-order logic, but it is more straightforward to encode it into program code. We show how to do more sophisticated information extraction in Section 22.4.
Following links
The strategy is to start at the home page of an online store and consider all pages that can be reached by following relevant links.11 The agent will have knowledge of a number of stores, for example:
Amazon ∈ OnlineStores ∧ Homepage(Amazon , “amazon.com”) .
Ebay ∈ OnlineStores ∧ Homepage(Ebay , “ebay.com”) .
ExampleStore ∈ OnlineStores ∧ Homepage(ExampleStore , “example.com”) .
These stores classify their goods into product categories, and provide links to the major categories from their home page. Minor categories can be reached through a chain of relevant links, and eventually we will reach offers. In other words, a page is relevant to the query if it can be reached by a chain of zero or more relevant category links from a store’s home page, and then from one more link to the product offer. We can define relevance:
Relevant(page , query) ⇔
∃ store , home store ∈OnlineStores ∧ Homepage(store , home) ∧ ∃ url , url~2~ RelevantChain(home , url~2~, query) ∧ Link(url~2~, url)
∧ page = Contents(url) .
Here the predicate Link(from, to) means that there is a hyperlink from the from URL to the to URL. To define what counts as a RelevantChain, we need to follow not just any old hyperlinks, but only those links whose associated anchor text indicates that the link is relevant to the product query. For this, we use LinkText(from , to, text) to mean that there is a link between from and to with text as the anchor text. A chain of links between two URLs, start and end, is relevant to a description d if the anchor text of each link is a relevant category name for d. The existence of the chain itself is determined by a recursive definition, with the empty chain (start = end ) as the base case:
RelevantChain(start , end , query) ⇔ (start = end)
∨ (∃u, text LinkText(start , u, text) ∧RelevantCategoryName(query , text)
∧ RelevantChain(u, end , query)) .
Now we must define what it means for text to be a RelevantCategoryName for query. First, we need to relate strings to the categories they name. This is done using the predicate Name(s, c), which says that string s is a name for category c—for example, we might assert that Name(“laptops”,LaptopComputers ). Some more examples of the Name predicate appear in Figure 12.9(b). Next, we define relevance. Suppose that query is “laptops.” Then RelevantCategoryName(query , text) is true when one of the following holds:
- The text and query name the same category—e.g., “notebooks” and “laptops.”
11 An alternative to the link-following strategy is to use an Internet search engine; the technology behind Internet search, information retrieval, will be covered in Section 22.3.
-
The text names a supercategory such as “computers.”
-
The text names a subcategory such as “ultralight notebooks.”
The logical definition of RelevantCategoryName is as follows:
RelevantCategoryName(query , text) ⇔
∃ C~1~, C~2~ Name(query , C~1~) ∧ Name(text , C~2~) ∧ (C~1~ ⊆ C~2~ ∨ C~2~ ⊆ C~1~) . (12.1)
Otherwise, the anchor text is irrelevant because it names a category outside this line, such as “clothes” or “lawn & garden.”
To follow relevant links, then, it is essential to have a rich hierarchy of product categories. The top part of this hierarchy might look like Figure 12.9(a). It will not be feasible to list all possible shopping categories, because a buyer could always come up with some new desire and manufacturers will always come out with new products to satisfy them (electric kneecap warmers?). Nonetheless, an ontology of about a thousand categories will serve as a very useful tool for most buyers.
In addition to the product hierarchy itself, we also need to have a rich vocabulary of names for categories. Life would be much easier if there were a one-to-one correspondence between categories and the character strings that name them. We have already seen the problem of synonymy—two names for the same category, such as “laptop computers” and “laptops.” There is also the problem of ambiguity—one name for two or more different categories. For example, if we add the sentence
Name(“CDs”,CertificatesOfDeposit)
to the knowledge base in Figure 12.9(b), then “CDs” will name two different categories. Synonymy and ambiguity can cause a significant increase in the number of paths that the agent has to follow, and can sometimes make it difficult to determine whether a given page is indeed relevant. A much more serious problem is the very broad range of descriptions that a user can type and category names that a store can use. For example, the link might say “laptop” when the knowledge base has only “laptops” or the user might ask for “a computer
I can fit on the tray table of an economy-class airline seat.” It is impossible to enumerate in advance all the ways a category can be named, so the agent will have to be able to do additional reasoning in some cases to determine if the Name relation holds. In the worst case, this requires full natural language understanding, a topic that we will defer to Chapter 22. In practice, a few simple rules—such as allowing “laptop” to match a category named “laptops”—go a long way. Exercise 12.10 asks you to develop a set of such rules after doing some research into online stores.
Given the logical definitions from the preceding paragraphs and suitable knowledge bases of product categories and naming conventions, are we ready to apply an inference algorithm to obtain a set of relevant offers for our query? Not quite! The missing element is the Contents(url) function, which refers to the HTML page at a given URL. The agent doesn’t have the page contents of every URL in its knowledge base; nor does it have explicit rules for deducing what those contents might be. Instead, we can arrange for the right HTTP procedure to be executed whenever a subgoal involves the Contents function. In this way, it appears to the inference engine as if the entire Web is inside the knowledge base. This is an example of a general technique called procedural attachment, whereby particular predicates and functions can be handled by special-purpose methods.
Comparing offers
Let us assume that the reasoning processes of the preceding section have produced a set of offer pages for our “laptops” query. To compare those offers, the agent must extract the relevant information—price, speed, disk size, weight, and so on—from the offer pages. This can be a difficult task with real Web pages, for all the reasons mentioned previously. A common way of dealing with this problem is to use programs called wrappers to extract information from a page. The technology of information extraction is discussed in Section 22.4. For now we assume that wrappers exist, and when given a page and a knowledge base, they add assertions to the knowledge base. Typically, a hierarchy of wrappers would be applied to a page: a very general one to extract dates and prices, a more specific one to extract attributes for computer-related products, and if necessary a site-specific one that knows the format of a particular store. Given a page on the example.com site with the text
IBM ThinkBook 970. Our price: $399.00
followed by various technical specifications, we would like a wrapper to extract information such as the following:
∃ c, offer c∈LaptopComputers ∧ offer ∈ProductOffers ∧
Manufacturer(c, IBM ) ∧Model (c,ThinkBook970 ) ∧
ScreenSize(c, Inches(14)) ∧ ScreenType(c,ColorLCD ) ∧
MemorySize(c,Gigabytes(2)) ∧ CPUSpeed(c,GHz (1.2)) ∧
OfferedProduct(offer , c) ∧ Store(offer ,GenStore) ∧
URL(offer , “example.com/computers/34356.html”) ∧ Price(offer , $(399)) ∧Date(offer ,Today) .
This example illustrates several issues that arise when we take seriously the task of knowledge engineering for commercial transactions. For example, notice that the price is an attribute of the offer, not the product itself. This is important because the offer at a given store may change from day to day even for the same individual laptop; for some categories—such as houses and paintings—the same individual object may even be offered simultaneously by different intermediaries at different prices. There are still more complications that we have not handled, such as the possibility that the price depends on the method of payment and on the buyer’s qualifications for certain discounts. The final task is to compare the offers that have been extracted. For example, consider these three offers:
A : 1.4 GHz CPU, 2GB RAM, 250 GB disk, $299 .
B : 1.2 GHz CPU, 4GB RAM, 350 GB disk, $500 .
C : 1.2 GHz CPU, 2GB RAM, 250 GB disk, $399 .
C is dominated by A; that is, A is cheaper and faster, and they are otherwise the same. In general, X dominates Y if X has a better value on at least one attribute, and is not worse on any attribute. But neither A nor B dominates the other. To decide which is better we need to know how the buyer weighs CPU speed and price against memory and disk space. The general topic of preferences among multiple attributes is addressed in Section 16.4; for now, our shopping agent will simply return a list of all undominated offers that meet the buyer’s description. In this example, both A and B are undominated. Notice that this outcome relies on the assumption that everyone prefers cheaper prices, faster processors, and more storage. Some attributes, such as screen size on a notebook, depend on the user’s particular preference (portability versus visibility); for these, the shopping agent will just have to ask the user.
The shopping agent we have described here is a simple one; many refinements are possible. Still, it has enough capability that with the right domain-specific knowledge it can actually be of use to a shopper. Because of its declarative construction, it extends easily to more complex applications. The main point of this section is to show that some knowledge representation—in particular, the product hierarchy—is necessary for such an agent, and that once we have some knowledge in this form, the rest follows naturally.
SUMMARY
By delving into the details of how one represents a variety of knowledge, we hope we have given the reader a sense of how real knowledge bases are constructed and a feeling for the interesting philosophical issues that arise. The major points are as follows:
-
Large-scale knowledge representation requires a general-purpose ontology to organize and tie together the various specific domains of knowledge.
-
A general-purpose ontology needs to cover a wide variety of knowledge and should be capable, in principle, of handling any domain.
-
Building a large, general-purpose ontology is a significant challenge that has yet to be fully realized, although current frameworks seem to be quite robust.
-
We presented an upper ontology based on categories and the event calculus. We covered categories, subcategories, parts, structured objects, measurements, substances, events, time and space, change, and beliefs.
-
Natural kinds cannot be defined completely in logic, but properties of natural kinds can be represented.
-
Actions, events, and time can be represented either in situation calculus or in more expressive representations such as event calculus. Such representations enable an agent to construct plans by logical inference.
-
We presented a detailed analysis of the Internet shopping domain, exercising the general ontology and showing how the domain knowledge can be used by a shopping agent.
-
Special-purpose representation systems, such as semantic networks and description logics, have been devised to help in organizing a hierarchy of categories. Inheritance is an important form of inference, allowing the properties of objects to be deduced from their membership in categories.
-
The closed-world assumption, as implemented in logic programs, provides a simple way to avoid having to specify lots of negative information. It is best interpreted as a default that can be overridden by additional information.
-
Nonmonotonic logics, such as circumscription and default logic, are intended to capture default reasoning in general.
-
Truth maintenance systems handle knowledge updates and revisions efficiently.
BIBLIOGRAPHICAL AND HISTORICAL NOTES
Briggs (1985) claims that formal knowledge representation research began with classical Indian theorizing about the grammar of Shastric Sanskrit, which dates back to the first millennium B.C. In the West, the use of definitions of terms in ancient Greek mathematics can be regarded as the earliest instance: Aristotle’s Metaphysics (literally, what comes after the book on physics) is a near-synonym for Ontology. Indeed, the development of technical terminology in any field can be regarded as a form of knowledge representation.
Early discussions of representation in AI tended to focus on “problem representation” rather than “knowledge representation.” (See, for example, Amarel’s (1968) discussion of the Missionaries and Cannibals problem.) In the 1970s, AI emphasized the development of “expert systems” (also called “knowledge-based systems”) that could, if given the appropriate domain knowledge, match or exceed the performance of human experts on narrowly defined tasks. For example, the first expert system, DENDRAL (Feigenbaum et al., 1971; Lindsay et al., 1980), interpreted the output of a mass spectrometer (a type of instrument used to analyze the structure of organic chemical compounds) as accurately as expert chemists. Although the success of DENDRAL was instrumental in convincing the AI research community of the importance of knowledge representation, the representational formalisms used in are highly specific to the domain of chemistry. Over time, researchers became interested in standardized knowledge representation formalisms and ontologies that could streamline the process of creating new expert systems. In so doing, they ventured into territory previously explored by philosophers of science and of language. The discipline imposed in AI by the need for one’s theories to “work” has led to more rapid and deeper progress than was the case when these problems were the exclusive domain of philosophy (although it has at times also led to the repeated reinvention of the wheel).
The creation of comprehensive taxonomies or classifications dates back to ancient times. Aristotle (384–322 B.C.) strongly emphasized classification and categorization schemes. His Organon, a collection of works on logic assembled by his students after his death, included a treatise called Categories in which he attempted to construct what we would now call an upper ontology. He also introduced the notions of genus and species for lower-level classification. Our present system of biological classification, including the use of “binomial nomenclature” (classification via genus and species in the technical sense), was invented by the Swedish biologist Carolus Linnaeus, or Carl von Linne (1707–1778). The problems associated with natural kinds and inexact category boundaries have been addressed by Wittgenstein (1953), Quine (1953), Lakoff (1987), and Schwartz (1977), among others.
Interest in larger-scale ontologies is increasing, as documented by the Handbook on Ontologies (Staab, 2004). The OPENCYC project (Lenat and Guha, 1990; Matuszek et al., 2006) has released a 150,000-concept ontology, with an upper ontology similar to the one in Figure 12.1 as well as specific concepts like “OLED Display” and “iPhone,” which is a type of “cellular phone,” which in turn is a type of “consumer electronics,” “phone,” “wireless communication device,” and other concepts. The DBPEDIA project extracts structured data from Wikipedia; specifically from Infoboxes: the boxes of attribute/value pairs that accompany many Wikipedia articles (Wu and Weld, 2008; Bizer et al., 2007). As of mid-2009, DBPEDIA contains 2.6 million concepts, with about 100 facts per concept. The IEEE working group P~1~600.1 created the Suggested Upper Merged Ontology (SUMO) (Niles and Pease, 2001; Pease and Niles, 2002), which contains about 1000 terms in the upper ontology and links to over 20,000 domain-specific terms. Stoffel et al. (1997) describe algorithms for efficiently managing a very large ontology. A survey of techniques for extracting knowledge from Web pages is given by Etzioni et al. (2008).
On the Web, representation languages are emerging. RDF (Brickley and Guha, 2004) allows for assertions to be made in the form of relational triples, and provides some means for evolving the meaning of names over time. OWL (Smith et al., 2004) is a description logic that supports inferences over these triples. So far, usage seems to be inversely proportional to representational complexity: the traditional HTML and CSS formats account for over 99% of Web content, followed by the simplest representation schemes, such as microformats (Khare, 2006) and RDFa (Adida and Birbeck, 2008), which use HTML and XHTML markup to add attributes to literal text. Usage of sophisticated RDF and OWL ontologies is not yet widespread, and the full vision of the Semantic Web (Berners-Lee et al., 2001) has not yet been realized. The conferences on Formal Ontology in Information Systems (FOIS) contain many interesting papers on both general and domain-specific ontologies.
The taxonomy used in this chapter was developed by the authors and is based in part on their experience in the CYC project and in part on work by Hwang and Schubert (1993) and Davis (1990, 2005). An inspirational discussion of the general project of commonsense knowledge representation appears in Hayes’s (1978, 1985b) “Naive Physics Manifesto.”
Successful deep ontologies within a specific field include the Gene Ontology project (Consortium, 2008) and CML, the Chemical Markup Language (Murray-Rust et al., 2003).
Doubts about the feasibility of a single ontology for all knowledge are expressed by Doctorow (2001), Gruber (2004), Halevy et al. (2009), and Smith (2004), who states, “the initial project of building one single ontology . . . has . . . largely been abandoned.”
The event calculus was introduced by Kowalski and Sergot (1986) to handle continuous time, and there have been several variations (Sadri and Kowalski, 1995; Shanahan, 1997) and overviews (Shanahan, 1999; Mueller, 2006). van Lambalgen and Hamm (2005) show how the logic of events maps onto the language we use to talk about events. An alternative to the event and situation calculi is the fluent calculus (Thielscher, 1999). James Allen introduced time intervals for the same reason (Allen, 1984), arguing that intervals were much more natural than situations for reasoning about extended and concurrent events. Peter Ladkin (1986a, 1986b) introduced “concave” time intervals (intervals with gaps; essentially, unions of ordinary “convex” time intervals) and applied the techniques of mathematical abstract algebra to time representation. Allen (1991) systematically investigates the wide variety of techniques available for time representation; van Beek and Manchak (1996) analyze algorithms for temporal reasoning. There are significant commonalities between the event-based ontology given in this chapter and an analysis of events due to the philosopher Donald Davidson (1980). The histories in Pat Hayes’s (1985a) ontology of liquids and the chronicles in McDermott’s (1985) theory of plans were also important influences on the field and this chapter.
The question of the ontological status of substances has a long history. Plato proposed that substances were abstract entities entirely distinct from physical objects; he would say MadeOf (Butter 3,Butter) rather than ButteR~3~ ∈Butter . This leads to a substance hierarchy in which, for example, UnsaltedButter is a more specific substance than Butter . The position adopted in this chapter, in which substances are categories of objects, was championed by Richard Montague (1973). It has also been adopted in the CYC project. Copeland (1993) mounts a serious, but not invincible, attack. The alternative approach mentioned in the chapter, in which butter is one object consisting of all buttery objects in the universe, was proposed originally by the Polish logician Leśniewski (1916). His mereology (the name is derived from the Greek word for “part”) used the part–whole relation as a substitute for mathematical set theory, with the aim of eliminating abstract entities such as sets. A more readable exposition of these ideas is given by Leonard and Goodman (1940), and Goodman’s The Structure of Appearance (1977) applies the ideas to various problems in knowledge representation. While some aspects of the mereological approach are awkward—for example, the need for a separate inheritance mechanism based on part–whole relations—the approach gained the support of Quine (1960). Harry Bunt (1985) has provided an extensive analysis of its use in knowledge representation. Casati and Varzi (1999) cover parts, wholes, and the spatial locations.
Mental objects have been the subject of intensive study in philosophy and AI. There are three main approaches. The one taken in this chapter, based on modal logic and possible worlds, is the classical approach from philosophy (Hintikka, 1962; KriP~k~e, 1963; Hughes and Cresswell, 1996). The book Reasoning about Knowledge (Fagin et al., 1995) provides a thorough introduction. The second approach is a first-order theory in which mental objects are fluents. Davis (2005) and Davis and Morgenstern (2005) describe this approach. It relies on the possible-worlds formalism, and builds on work by Robert Moore (1980, 1985). The third approach is a syntactic theory, in which mental objects are represented by character strings. A string is just a complex term denoting a list of symbols, so CanFly(Clark ) can be represented by the list of symbols [C, a, n, F, l, y, (, C, l, a, r, k, )]. The syntactic theory of mental objects was first studied in depth by Kaplan and Montague (1960), who showed that it led to paradoxes if not handled carefully. Ernie Davis (1990) provides an excellent comparison of the syntactic and modal theories of knowledge.
The Greek philosopher Porphyry (c. 234–305 A.D.), commenting on Aristotle’s Categories, drew what might qualify as the first semantic network. Charles S. Peirce (1909) developed existential graphs as the first semantic network formalism using modern logic. Ross Quillian (1961), driven by an interest in human memory and language processing, initiated work on semantic networks within AI. An influential paper by Marvin Minsky (1975) presented a version of semantic networks called frames; a frame was a representation of an object or category, with attributes and relations to other objects or categories. The question of semantics arose quite acutely with respect to Quillian’s semantic networks (and those of others who followed his approach), with their ubiquitous and very vague “IS-A links” Woods’s (1975) famous article “What’s In a Link?” drew the attention of AI researchers to the need for precise semantics in knowledge representation formalisms. Brachman (1979) elaborated on this point and proposed solutions. Patrick Hayes’s (1979) “The Logic of Frames” cut even deeper, claiming that “Most of ‘frames’ is just a new syntax for parts of first-order logic.” Drew McDermott’s (1978b) “Tarskian Semantics, or, No Notation without Denotation!” argued that the model-theoretic approach to semantics used in first-order logic should be applied to all knowledge representation formalisms. This remains a controversial idea; notably, McDermott himself has reversed his position in “A Critique of Pure Reason” (McDermott, 1987). Selman and Levesque (1993) discuss the complexity of inheritance with exceptions, showing that in most formulations it is NP-complete.
The development of description logics is the most recent stage in a long line of research aimed at finding useful subsets of first-order logic for which inference is computationally tractable. Hector Levesque and Ron Brachman (1987) showed that certain logical constructs—notably, certain uses of disjunction and negation—were primarily responsible for the intractability of logical inference. Building on the KL-ONE system (Schmolze and Lipkis, 1983), several researchers developed systems that incorporate theoretical complexity analysis, most notably KRYPTON (Brachman et al., 1983) and Classic (Borgida et al., 1989). The result has been a marked increase in the speed of inference and a much better understanding of the interaction between complexity and expressiveness in reasoning systems. Calvanese et al. (1999) summarize the state of the art, and Baader et al. (2007) present a comprehensive handbook of description logic. Against this trend, Doyle and Patil (1991) have argued that restricting the expressiveness of a language either makes it impossible to solve certain problems or encourages the user to circumvent the language restrictions through nonlogical means.
The three main formalisms for dealing with nonmonotonic inference—circumscription (McCarthy, 1980), default logic (Reiter, 1980), and modal nonmonotonic logic (McDermott and Doyle, 1980)—were all introduced in one special issue of the AI Journal. Delgrande and Schaub (2003) discuss the merits of the variants, given 25 years of hindsight. Answer set programming can be seen as an extension of negation as failure or as a refinement of circumscription; the underlying theory of stable model semantics was introduced by Gelfond and Lifschitz (1988), and the leading answer set programming systems are DLV (Eiter et al., 1998) and SMODELS (Niemelä et al., 2000). The disk drive example comes from the SMODELS user manual (Syrjänen, 2000). Lifschitz (2001) discusses the use of answer set programming for planning. Brewka et al. (1997) give a good overview of the various approaches to nonmonotonic logic. Clark (1978) covers the negation-as-failure approach to logic programming and Clark completion. Van Emden and Kowalski (1976) show that every Prolog program without negation has a unique minimal model. Recent years have seen renewed interest in applications of nonmonotonic logics to large-scale knowledge representation systems. The systems for handling insurance-benefit inquiries was perhaps the first commercially successful application of a nonmonotonic inheritance system (Morgenstern, 1998). Lifschitz (2001) discusses the application of answer set programming to planning. A variety of nonmonotonic reasoning systems based on logic programming are documented in the proceedings of the conferences on Logic Programming and Nonmonotonic Reasoning (Lp~n~MR).
The study of truth maintenance systems began with the TMS (Doyle, 1979) and RUP (McAllester, 1980) systems, both of which were essentially JTMSs. Forbus and de Kleer (1993) explain in depth how TMSs can be used in AI applications. Nayak and Williams (1997) show how an efficient incremental TMS called an ITMS makes it feasible to plan the operations of a NASA spacecraft in real time.
This chapter could not cover every area of knowledge representation in depth. The three principal topics omitted are the following:
Qualitative physics: Qualitative physics is a subfield of knowledge representation concerned specifically with constructing a logical, nonnumeric theory of physical objects and processes. The term was coined by Johan de Kleer (1975), although the enterprise could be said to have started in Fahlman’s (1974) BUILD, a sophisticated planner for constructing complex towers of blocks. Fahlman discovered in the process of designing it that most of the effort (80%, by his estimate) went into modeling the physics of the blocks world to calculate the stability of various subassemblies of blocks, rather than into planning per se. He sketches a hypothetical naive-physics-like process to explain why young children can solve BUILD-like problems without access to the high-speed floating-point arithmetic used in BUILD’s physical modeling. Hayes (1985a) uses “histories”—four-dimensional slices of space-time similar to Davidson’s events—to construct a fairly complex naive physics of liquids. Hayes was the first to prove that a bath with the plug in will eventually overflow if the tap keeps running and that a person who falls into a lake will get wet all over. Davis (2008) gives an update to the ontology of liquids that describes the pouring of liquids into containers.
De Kleer and Brown (1985), Ken Forbus (1985), and Benjamin Kuipers (1985) independently and almost simultaneously developed systems that can reason about a physical system based on qualitative abstractions of the underlying equations. Qualitative physics soon developed to the point where it became possible to analyze an impressive variety of complex physical systems (Yip, 1991). Qualitative techniques have been used to construct novel designs for clocks, windshield wipers, and six-legged walkers (Subramanian and Wang, 1994). The collection Readings in Qualitative Reasoning about Physical Systems (Weld and de Kleer, 1990) an encyclopedia article by Kuipers (2001), and a handbook article by Davis (2007) introduce to the field.
Spatial reasoning: The reasoning necessary to navigate in the wumpus world and shopping world is trivial in comparison to the rich spatial structure of the real world. The earliest serious attempt to capture commonsense reasoning about space appears in the work of Ernest Davis (1986, 1990). The region connection calculus of Cohn et al. (1997) supports a form of qualitative spatial reasoning and has led to new kinds of geographical information systems; see also (Davis, 2006). As with qualitative physics, an agent can go a long way, so to speak, without resorting to a full metric representation. When such a representation is necessary, techniques developed in robotics (Chapter 25) can be used.
Psychological reasoning: Psychological reasoning involves the development of a working psychology for artificial agents to use in reasoning about themselves and other agents. This is often based on so-called folk psychology, the theory that humans in general are believed to use in reasoning about themselves and other humans. When AI researchers provide their artificial agents with psychological theories for reasoning about other agents, the theories are frequently based on the researchers’ description of the logical agents’ own design. Psychological reasoning is currently most useful within the context of natural language understanding, where divining the speaker’s intentions is of paramount importance.
Minker (2001) collects papers by leading researchers in knowledge representation, summarizing 40 years of work in the field. The proceedings of the international conferences on Principles of Knowledge Representation and Reasoning provide the most up-to-date sources for work in this area. Readings in Knowledge Representation (Brachman and Levesque, 1985) and Formal Theories of the Commonsense World (Hobbs and Moore, 1985) are excellent anthologies on knowledge representation; the former focuses more on historically important papers in representation languages and formalisms, the latter on the accumulation of the knowledge itself. Davis (1990), Stefik (1995), and Sowa (1999) provide textbook introductions to knowledge representation, van Harmelen et al. (2007) contributes a handbook, and a special issue of AI Journal covers recent progress (Davis and Morgenstern, 2004). The biennial conference on Theoretical Aspects of Reasoning About Knowledge (TARK) covers applications of the theory of knowledge in AI, economics, and distributed systems.
EXERCISES
12.1 Define an ontology in firstorder logic for tic-tac-toe. The ontology should contain situations, actions, squares, players, marks (X, O, or blank), and the notion of winning, losing, or drawing a game. Also define the notion of a forced win (or draw): a position from which a player can force a win (or draw) with the right sequence of actions. Write axioms for the domain. (Note: The axioms that enumerate the different squares and that characterize the winning positions are rather long. You need not write these out in full, but indicate clearly what they look like.)
12.2 Figure 12.1 shows the top levels of a hierarchy for everything. Extend it to include as many real categories as possible. A good way to do this is to cover all the things in your everyday life. This includes objects and events. Start with waking up, and proceed in an orderly fashion noting everything that you see, touch, do, and think about. For example, a random sampling produces music, news, milk, walking, driving, gas, Soda Hall, carpet, talking, Professor Fateman, chicken curry, tongue, $7, sun, the daily newspaper, and so on.
You should produce both a single hierarchy chart (on a large sheet of paper) and a listing of objects and categories with the relations satisfied by members of each category. Every object should be in a category, and every category should be in the hierarchy.
12.3 Develop a representational system for reasoning about windows in a window-based computer interface. In particular, your representation should be able to describe:
-
The state of a window: minimized, displayed, or nonexistent.
-
Which window (if any) is the active window.
-
The position of every window at a given time.
-
The order (front to back) of overlapping windows.
-
The actions of creating, destroying, resizing, and moving windows; changing the state of a window; and bringing a window to the front. Treat these actions as atomic; that is, do not deal with the issue of relating them to mouse actions. Give axioms describing the effects of actions on fluents. You may use either event or situation calculus.
Assume an ontology containing situations, actions, integers (for x and y coordinates) and windows. Define a language over this ontology; that is, a list of constants, function symbols, and predicates with an English description of each. If you need to add more categories to the ontology (e.g., pixels), you may do so, but be sure to specify these in your write-up. You may (and should) use symbols defined in the text, but be sure to list these explicitly.
12.4 State the following in the language you developed for the previous exercise:
a. In situation S~0~, window w~1~ is behind W2 but sticks out on the left and right. Do not state exact coordinates for these; describe the general situation.
b. If a window is displayed, then its top edge is higher than its bottom edge.
c. After you create a window w, it is displayed.
d. A window can be minimized if it is displayed.
12.5 (Adapted from an example by Doug Lenat.) Your mission is to capture, in logical form, enough knowledge to answer a series of questions about the following simple scenario:
Yesterday John went to the North Berkeley Safeway supermarket and bought two pounds of tomatoes and a pound of ground beef.
Start by trying to represent the content of the sentence as a series of assertions. You should write sentences that have straightforward logical structure (e.g., statements that objects have certain properties, that objects are related in certain ways, that all objects satisfying one property satisfy another). The following might help you get started:
-
Which classes, objects, and relations would you need? What are their parents, siblings and so on? (You will need events and temporal ordering, among other things.)
-
Where would they fit in a more general hierarchy?
-
What are the constraints and interrelationships among them?
-
How detailed must you be about each of the various concepts?
To answer the questions below, your knowledge base must include background knowledge. You’ll have to deal with what kind of things are at a supermarket, what is involved with purchasing the things one selects, what the purchases will be used for, and so on. Try to make your representation as general as possible. To give a trivial example: don’t say “People buy food from Safeway,” because that won’t help you with those who shop at another supermarket. Also, don’t turn the questions into answers; for example, question (c) asks “Did John buy any meat?”—not “Did John buy a pound of ground beef?”
Sketch the chains of reasoning that would answer the questions. If possible, use a logical reasoning system to demonstrate the sufficiency of your knowledge base. Many of the things you write might be only approximately correct in reality, but don’t worry too much; the idea is to extract the common sense that lets you answer these questions at all. A truly complete answer to this question is extremely difficult, probably beyond the state of the art of current knowledge representation. But you should be able to put together a consistent set of axioms for the limited questions posed here.
a. Is John a child or an adult? [Adult]
b. Does John now have at least two tomatoes? [Yes]
c. Did John buy any meat? [Yes]
d. If Mary was buying tomatoes at the same time as John, did he see her? [Yes]
e. Are the tomatoes made in the supermarket? [No]
f. What is John going to do with the tomatoes? [Eat them]
g. Does Safeway sell deodorant? [Yes]
h. Did John bring some money or a credit card to the supermarket? [Yes]
i. Does John have less money after going to the supermarket? [Yes]
12.6 Make the necessary additions or changes to your knowledge base from the previous exercise so that the questions that follow can be answered. Include in your report a discussion of your changes, explaining why they were needed, whether they were minor or major, and what kinds of questions would necessitate further changes.
a. Are there other people in Safeway while John is there? [Yes—staff!]
b. Is John a vegetarian? [No]
c. Who owns the deodorant in Safeway? [Safeway Corporation]
d. Did John have an ounce of ground beef? [Yes]
e. Does the Shell station next door have any gas? [Yes]
f. Do the tomatoes fit in John’s car trunk? [Yes]
12.7 Represent the following seven sentences using and extending the representations developed in the chapter:
a. Water is a liquid between 0 and 100 degrees.
b. Water boils at 100 degrees.
c. The water in John’s water bottle is frozen.
d. Perrier is a kind of water.
e. John has Perrier in his water bottle.
f. All liquids have a freezing point.
g. A liter of water weighs more than a liter of alcohol.
12.8 Write definitions for the following:
a. ExhaustivePartDecomposition
b. PartPartition
c. PartwiseDisjoint
These should be analogous to the definitions for ExhaustiveDecomposition , Partition , and Disjoint . Is it the case that PartPartition(s,BunchOf (s))? If so, prove it; if not, give a counterexample and define sufficient conditions under which it does hold.
12.9 An alternative scheme for representing measures involves applying the units function to an abstract length object. In such a scheme, one would write Inches(Length(l~1~)) = 1.5. How does this scheme compare with the one in the chapter? Issues include conversion axioms, names for abstract quantities (such as “50 dollars”), and comparisons of abstract measures in different units (50 inches is more than 50 centimeters).
12.10 Add sentences to extend the definition of the predicate Name(s, c) so that a string such as “laptop computer” matches the appropriate category names from a variety of stores. Try to make your definition general. Test it by looking at ten online stores, and at the category names they give for three different categories. For example, for the category of laptops, we found the names “Notebooks,” “Laptops,” “Notebook Computers,” “Notebook,” “Laptops and Notebooks,” and “Notebook PCs.” Some of these can be covered by explicit Name facts, while others could be covered by sentences for handling plurals, conjunctions, etc.
12.11 Write event calculus axioms to describe the actions in the wumpus world.
12.12 State the interval-algebra relation that holds between every pair of the following realworld events:
LK: The life of President Kennedy. IK: The infancy of President Kennedy. PK: The presidency of President Kennedy. LJ : The life of President Johnson. P~j~ : The presidency of President Johnson. LO: The life of President Obama.
12.13 Investigate ways to extend the event calculus to handle simultaneous events. Is it possible to avoid a combinatorial explosion of axioms?
12.14 Construct a representation for exchange rates between currencies that allows for daily fluctuations.
12.15 Define the predicate Fixed , where Fixed(Location(x)) means that the location of object x is fixed over time.
12.16 Describe the event of trading something for something else. Describe buying as a kind of trading in which one of the objects traded is a sum of money.
12.17 The two preceding exercises assume a fairly primitive notion of ownership. For example, the buyer starts by owning the dollar bills. This picture begins to break down when, for example, one’s money is in the bank, because there is no longer any specific collection of dollar bills that one owns. The picture is complicated still further by borrowing, leasing, renting, and bailment. Investigate the various commonsense and legal concepts of ownership, and propose a scheme by which they can be represented formally.
12.18 (Adapted from Fagin et al. (1995).) Consider a game played with a deck of just 8 cards, 4 aces and 4 kings. The three players, Alice, Bob, and Carlos, are dealt two cards each. Without looking at them, they place the cards on their foreheads so that the other players can see them. Then the players take turns either announcing that they know what cards are on their own forehead, thereby winning the game, or saying “I don’t know.” Everyone knows the players are truthful and are perfect at reasoning about beliefs.
a. Game 1. Alice and Bob have both said “I don’t know.” Carlos sees that Alice has two aces (A-A) and Bob has two kings (K-K). What should Carlos say? (Hint: consider all three possible cases for Carlos: A-A, K-K, A-K.)
b. Describe each step of Game 1 using the notation of modal logic. c. Game 2. Carlos, Alice, and Bob all said “I don’t know” on their first turn. Alice holds
K-K and Bob holds A-K. What should Carlos say on his second turn? d. Game 3. Alice, Carlos, and Bob all say “I don’t know” on their first turn, as does Alice
on her second turn. Alice and Bob both hold A-K. What should Carlos say? e. Prove that there will always be a winner to this game.
12.19 The assumption of logical omniscience, discussed on page 453, is of course not true of any actual reasoners. Rather, it is an idealization of the reasoning process that may be more or less acceptable depending on the applications. Discuss the reasonableness of the assumption for each of the following applications of reasoning about knowledge:
a. Partial knowledge adversary games, such as card games. Here one player wants to reason about what his opponent knows about the state of the game.
b. Chess with a clock. Here the player may wish to reason about the limits of his opponent’s or his own ability to find the best move in the time available. For instance, if player A has much more time left than player B, then A will sometimes make a move that greatly complicates the situation, in the hopes of gaining an advantage because he has more time to work out the proper strategy.
c. A shopping agent in an environment in which there are costs of gathering information.
d. Reasoning about public key cryptography, which rests on the intractability of certain computational problems.
12.20 Translate the following description logic expression (from page 457) into first-order logic, and comment on the result:
And(Man ,AtLeast(3,Son),AtMost(2,Daughter),
All(Son ,And(Unemployed ,Married ,All(Spouse ,Doctor ))),
All(Daughter ,And(Professor ,Fills(Department ,Physics ,Math)))) .
12.21 Recall that inheritance information in semantic networks can be captured logically by suitable implication sentences. This exercise investigates the efficiency of using such sentences for inheritance.
a. Consider the information in a used-car catalog such as Kelly’s Blue Book—for example, that 1973 Dodge vans are (or perhaps were once) worth $575. Suppose all this information (for 11,000 models) is encoded as logical sentences, as suggested in the chapter. Write down three such sentences, including that for 1973 Dodge vans. How would you use the sentences to find the value of a particular car, given a backwardchaining theorem prover such as Prolog?
b. Compare the time efficiency of the backward-chaining method for solving this problem with the inheritance method used in semantic nets.
c. Explain how forward chaining allows a logic-based system to solve the same problem efficiently, assuming that the KB contains only the 11,000 sentences about prices.
d. Describe a situation in which neither forward nor backward chaining on the sentences will allow the price query for an individual car to be handled efficiently.
e. Can you suggest a solution enabling this type of query to be solved efficiently in all cases in logic systems? (Hint: Remember that two cars of the same year and model have the same price.)
12.22 One might suppose that the syntactic distinction between unboxed links and singly boxed links in semantic networks is unnecessary, because singly boxed links are always attached to categories; an inheritance algorithm could simply assume that an unboxed link attached to a category is intended to apply to all members of that category. Show that this argument is fallacious, giving examples of errors that would arise.
12.23 One part of the shopping process that was not covered in this chapter is checking for compatibility between items. For example, if a digital camera is ordered, what accessory batteries, memory cards, and cases are compatible with the camera? Write a knowledge base that can determine the compatibility of a set of items and suggest replacements or additional items if the shopper makes a choice that is not compatible. The knowledge base should works with at least one line of products and extend easily to other lines.
12.24 A complete solution to the problem of inexact matches to the buyer’s description in shopping is very difficult and requires a full array of natural language processing and information retrieval techniques. (See Chapters 22 and 23.) One small step is to allow the user to specify minimum and maximum values for various attributes. The buyer must use the following grammar for product descriptions:
Description → Category [Connector Modifier ]∗
Connector → “with” | “and” | “,” Modifier → Attribute | Attribute Op Value
Op → “=” | “>” | “<”
Here, Category names a product category, Attribute is some feature such as “CPU” or “price,” and Value is the target value for the attribute. So the query “computer with at least a 2.5 GHz CPU for under $500” must be re-expressed as “computer with CPU > 2.5 GHz and price < $500.” Implement a shopping agent that accepts descriptions in this language.
12.25 Our description of Internet shopping omitted the all-important step of actually buying the product. Provide a formal logical description of buying, using event calculus. That is, define the sequence of events that occurs when a buyer submits a credit-card purchase and then eventually gets billed and receives the product.